전체
Paper Review
Data curation
Hands-on
Development Glossary
Company
Search





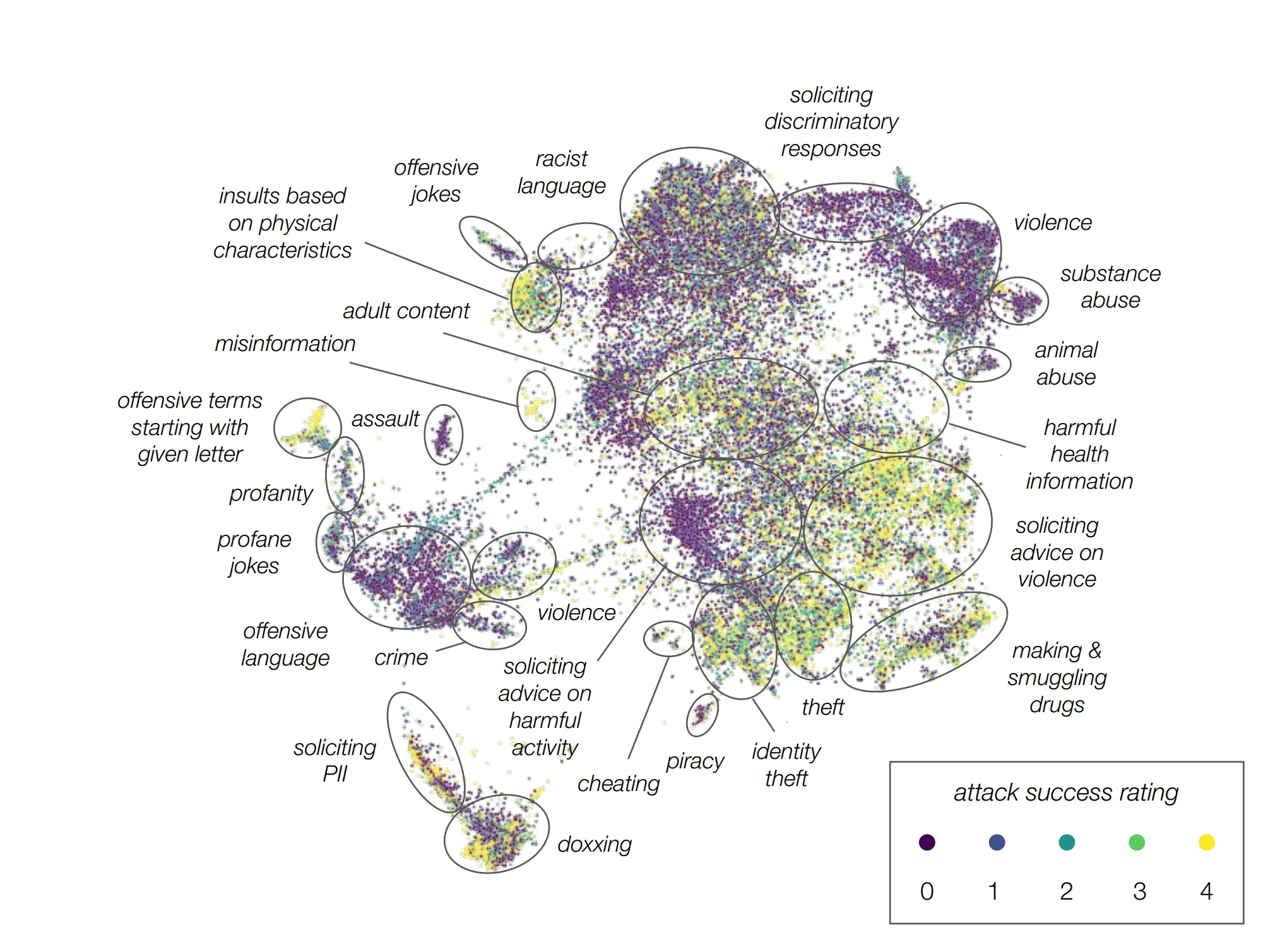


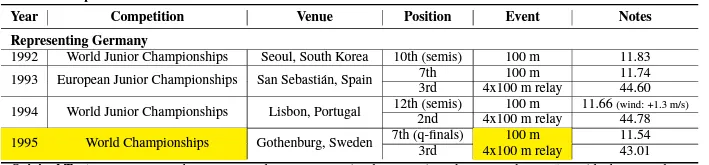
LLM Compile Process Overview
前回の記事「【極めてプライベートな自分だけのLLM、価値があるのか?[第1回 - ファインチューニング](https://blog.sionic.ai/Finetuning_Llama)では、大規模モデル構築の難しさと破壊的な忘却現象などの代替として登場したRetriever Augmented Generation(RAG)方法を見てみました。 RAGはLLMの強力なテキスト生成能力をベースにして、モデルにユーザーのクエリに合った文書のスニペットを適切に取り込んでプロンプトを通じて応答する方式です。ユーザーがパーソナライズされたLLMを構築し、特定の目的に合わせて調整する方法は、様々な所で有用に使用することができます。
今回はMLC-LLMパッケージを活用したWebGPU Build & Runガイドを共有します。これにより、大規模言語モデル(LLM)がWebGPUを活用して、ビルド&実行する過程を通じて、自分のデータで大規模言語モデルを構築、実行することができるようになります。
前提条件
LLMビルドのための要件
•
python3: 普遍的によく使われるConda環境で、python言語を使用して進行します。
•
conda: Pythonパッケージの衝突を防ぐために環境分離の時に必要です。
•
Git LFS: weight fileなど大容量ファイルをpullingするために必要です。
•
TVM Compiler: オープンソースディープラーニングコンパイラ
WebAssembly ビルドのための要件
•
Emscripten: LLVMを使う言語(C/C++)をWebAssemblyでコンパイルできるようにするツールチェーン。
ビルド

極めてプライベートな私だけのLLM、作れるのか?[第2弾- WebGPU Build & Run]
金德顯 キム ドクヒョン / Head of Development
個人の使い方に合わせた超巨大言語モデルの活用
LLM
compilation
WebGPU


導入
•
Promptingは人間が大規模言語モデル(LLM)を制御し、コミュニケーションする手段である。
•
ユーザーは、欲しい結果を得るために、どうすればうまくPromptingを作成できるかという一般的な方法論に対するニーズは今後も増えると思われる。
•
最近、生成だけでなく、自然言語理解(文の分類、シーケンスラベル付け、質疑応答)課題でプロンプトチューニングがファインチューニングよりも性能が良くなったというレポート(Lifu Tu et al. (2022)やCOT(Jason Wei et al. (2022)などのプロンプト方法論、そしてマルチモーダルでの応用(Andy Zeng et al. (2022)などが発表され始めている。
•
この記事では、プロンプティングを通じてzero-shotのパフォーマンスを向上させる興味深い2つの論文を紹介する。

•
レビュー論文
概要
•
COSP : Consistency-based Self-adaptive Prompting
•
USP : Universal Self-adaptive Prompting
•
Unlabeled dataとblack-box LLMを通じてzero-shot in-context learning(ICL)の性能を向上させることを目的とした異なる2つの方法論
効果的なプロンプティング(Prompting)方法論の紹介
朴宇明 / CDO & Head of Research
効果的なプロンプティング(Prompting)方法論の紹介
Prompting
Tuning
この記事の前半ではSuper-NaturalInstructions(SuperNI)論文を概観した後、後半ではSuperNIに含まれるデータセットのうち、韓国語であったり、興味深いテーマを含んでいるデータセットを紹介します。

論文紹介
概要
•
SuperNIはAllen Institute for AI、University of Washington、Arizona State Universityをはじめとする合計21機関所属の研究者が参加し、1600余りのNLP instructionデータを作成し、公開したプロジェクトです。
•
https://arxiv.org/abs/2104.08773で61個のタスクに関するデータを公開することからスタート。
•
合計88人のコントリビューターが既存の公開されたNLPデータを活用し、クラウドソーシングするなどの方法で作業
•
Tk-Instruct(英語)及びmTk-Instruct(多言語)モデル開発
方法論の詳細
•
データ構造
•
SuperNIデータセットの簡単な統計分析
[論文レビュー]Super-NaturalInstructions
朴宇明 / CDO & Head of Research, 宋永淑 / ML Researcher
Super-Natural Instructions(SuperNI)論文・データセットの紹介
Instruction
LLM
dataset
Super-NaturalInstructions
導入
•
LLMは単純なプロンプトだけで多くの課題で優れた能力を発揮するが、完璧ではない。
•
その中でも代表的な問題としては、事実でない内容を事実であるかのように生成するハルシネーション問題、そして社会的に問題の余地がある危険な発言を生成する問題などがある。
•
この記事では、biasが存在する、または問題となる内容をLLMが自ら判断し、抑制することに関する論文について紹介する。
•
参考までに、このようなLLMの「self-correction」あるいは「self-refinement」の問題についてもっと詳しく知りたい場合は、このsurvey論文(Pan et al. (2023)および関連referenceを参考
•
レビュー論文

概要
•
LLMが生成した文章をユーザーが望むように'align'させるために、既存の多くの研究ではpreference datasetを構築し、reward modelを学習した後、このスコアに基づいてLLMをRL(e.g., PPO)でチューニングする方法を多く使用。
•
実際のOpenAIのモデル (InstructGPT、ChatGPT、GPT-4など) をはじめ、Google、Meta、Anthropicなどほぼ全てのところでこの方法でチューニングをしてLLMを開発した。
•
しかし、reward modelを学習するためのデータセット制作は非常に時間と費用がかかり、構築難易度が高く、開発が難しい。
•
ここでは、明示的な reward model なしで zero-shot/few-shot prompting を通じて効果的にharmlessnessを高める (つまり、有害なコンテンツ生成を抑制する) 結果を示している。
LLMは自ら回答の危険性を判断できるのか?
朴宇明 / CDO & Head of Research
超巨大言語モデルの回答の危険性を判断するに関連する論文の紹介
Prompting
Alignment
LLM
表データの役割
•
表データの歴史
(1) 特定ドメインに関連するデータが主に構築されたが、バスケットボールに関連するRotowire(Wiseman et al, 2017)データセット、生物学に関連するKBGen(Banik et al, 2013)、Wikibio(Lebret et al, 2016)データセット、レストラン予約などに関連するE2E(Novikova et al, 2016, 2017)などがその例である。(2) 表による文章生成に関しては、Puduppully,R.(2018), Ankur Parikh et al(2020), Jonathan et al(2020) などがある。この記事では、その中でもToTTo:A Controlled Table-To-Text Generation Dataset について説明する。

ToTTo で表ベースの文章生成データを作成するプロセス
•
(1) 様々な形式のフォーマットからタイトル、サブタイトル、表情報を抽出した後、主要な表情報を黄褐色で強調表示(highlight)する。
•
(2) 表と一緒に収集した文章(下の画像でOriginal text)から表の内容と関係ないものは削除(text after deletion)した後、最終的に文章を作成し、文章生成の精度を高めた。
表データベースの文章生成
宋永淑 ソン・ヨンソク / ML Researcher
表のデータ分析方法論の紹介
Table
Generation
RAG(Retrieval Augmented Generation)とファインチューニング
大規模言語モデル(Large language model, LLM)は、一般的な課題をうまく処理する利点があります。私たちがChatGPTに熱狂する理由も、一般的な知識に関する質問や推論に対して必要な答えをうまく生成するためだと思います。しかし、日常生活での大規模言語モデルの有効活用には、個人や組織レベルで特定のデータを学習させることが不可欠です。
本稿では、RAGとファインチューニングという2つの方法を取り上げます。これらはいずれも、大規模言語モデルをベースにしてカスタマイズを行う手法ですが、それぞれにコストと性能の面で異なる特徴があります。
まず、言語モデルをプライベートなLLMとして使用できる方法として、ファインチューニングがあります。事前学習された大規模言語モデルに小さなデータセットを追加で学習させ、特定の作業に合わせて微調整して性能を改善する方法です。伝統的に、ファインチューニングは巨大な単位のウェブデータを事前学習し、小さな分野の課題に応じてチューニングを行う方法でしたが、モデルのパラメータ数がどんどん大きくなり、企業や研究者がモデル全体をファインチューニングすることが難しくなり、ファインチューニングしたモデルの保存とコストも非常に大きくなりました。この他にも、新しい情報を学習する際、以前に学習した情報を突然急激に忘れる現象、つまり破壊的忘却(Catastrophic forgetting)と呼ばれる現象も解決に困難がありました。
ChatGPTなどのLLMモデルが産業的に台頭し始めてからちょうど1年が経ち、各企業が見つけた費用対効果の高い代替手段がRAGと言えます。RAG手法は、LLMの強力なテキスト生成力をベースに、ユーザーのクエリに合った必要な文書スニペットを適切に取り出し、モデルにプロンプトを提供して応答する方法です。LlamaIndexやLangchainのような開発者ツールやunstructured.ioのような前処理SDK、そしてMilvusのような複数の商用のベクターサーチDBが最近1年間に誘致した投資額とバリュエーションを見ると、業界におけるRAGに対する関心度は容易に推測できると思います。
写真出典: OpenAI - A Survey of Techniques for Maximizing LLM Performance https://youtu.be/ahnGLM-RC1Y
しかし、モデルの目的そのものをより自由に変えられるという点で、ファインチューニングが持つ魅力も無視できません。モデルが応答するスタイルやトーンやマナー、フォーマットのような質的な面を変えたり、希望する形のアウトプットが出ることを保証したり、TextをSQLに変えるなどのプロンプトだけでは説明しにくい特定のタスクに特化する必要がある場合は、ファインチューニングが有利な場合もあります。
OpenAIは前回のDevDayでファインチューニングとRAGが必要な場合を2つの軸で整理して紹介しました。モデルの知識的な側面を修正したい場合にはRAGを、モデルがどのように答えて推論するかを修正したい場合にはファインチューニングが適していると紹介しました。
過去には簡単ではなかったベースモデルのファインチューニングが、2つの側面から、一般開発者にとってアクセスしやすい形になってきていると思います。一つは、商用化されたモデルのクラウドサービスとしての「ファインチューニング用のAPI」(https://platform.openai.com/docs/guides/fine-tuning/fine-tuning-examples)を提供していることと、もう一つは、ファインチューニングのプロセス全般の難易度が下がり、少しの知識さえあれば、公開モデルを利用して独自のデータセットを持ってプライベートな環境でファインチューニングができるようになったことです。 今回の記事シリーズでは、このように独自のデータセットでファインチューニングするプロセスを実習してみたいと思います。
1.
オープンソースベースの大規模言語モデルを基に、独自のデータセットでファインチューニングする。
2.
当該モデルのインファレンスをWebGPUを活用してローカルで行うことで、機密性の高い情報を外部に公開することなく、ローカルで自分だけのLLMを駆動できる。
今回の記事では、Meta AIが公開したLLaMA 7B Chatモデルを基に、QLoRAを活用して自分だけのデータをファインチューニングし、Hugging Faceに配布してみたいと思います。
極めて私的な私だけのLLM、作れるのか? [第1弾ーファインチューニング]
朴 ジンヒョン(Sigrid Jin) / Software Engineer, Sionic AI
非暴力的、非倫理的な出力を検証できるデータセット
Finetuning
Llama
ファインチューニング
大規模言語モデル
LLM
목차

利用原則 🫡
スラック(https://slack.com/intl/ko-kr/)は、コミュニケーションのスピードを上げるための業務ツールに過ぎません!
そのため、組織に適したルールを作り続け、変化していく必要があります。
つまり、皆さんが不便な点や改善すべき点があれば、いつでも提案して反映していことが重要です!Slackの「メッセージ」は一つのメールと理解しましょう!
•
そのため、Slackのメッセージには自分の考えを全部入れて一つのメッセージで送るのが良いです。
•
メッセージへの返信は個人のメッセージではなく、「スレッド」でしましょう。
スレッドを積極的に活用すれば、
•
一つのテーマについて、他のメッセージに邪魔されることなく、体系的に議論することができます。
•
私の議論の過程がトピックと関係のない人に通知で伝わらないため、不必要なノイズを塞げることができます。
•
自分が関連しているテーマのスレッドのみ選んで参加することができます。
Slack 使用ガイド
金慧元 /CPO, 金德顯 / Head of Development
効果的なスラックの使用ガイド
Culture
Slack





.png&blockId=de4d05fa-f606-470a-9915-c73503660b73)
今回のブログでは、韓国語データキュレーションについて説明します。データキュレーションは、データの構築と生成だけでなく、データの活用価値を高めるすべての活動を含みます。この記事で扱うすべてのデータは、外国人もダウンロードできるデータです。 データについてのより詳しい説明は https://github.com/ko-nlp/Open-korean-corpora と https://corpus.korean.go.kr/main/requestMain.do에서 を参照してください。外国人の参加申請については、次の文書の内容を参照してください。
1. 韓国語コーパス構築の変化の様子
Open-korean-corporaを通じて1次韓国語データキュレーションを行った2019年には、構文解析データと類似文、並列コーパスなどが多数ありました。
<図1> データの一般的な使用と提供機関
これは、次の画像のように、形態素や文章の特性を抽出し、必要な情報を処理するデータが主に構築されたためです。
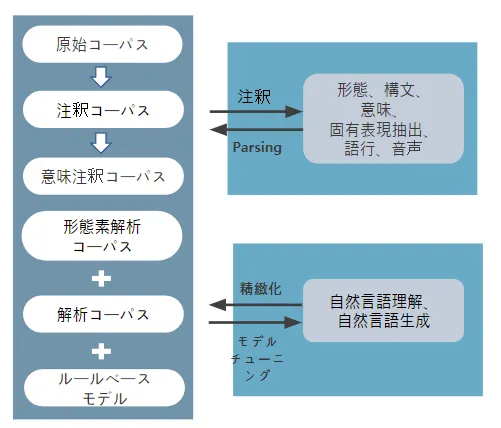
<図2>テキストデータの分析方法と自然言語処理課題の細分化
2020年から現在(2023年)まで、嫌悪表現とともに様々なテーマ(その他のテーマに含まれる)のデータが増加しました。全体的に意味分類に関連するデータが研究や産業で多く使われていることが確認できます。
韓国語コーパスの構築(1)
宋永淑 ソン・ヨンソク/ ML Researcher
韓国語コーパスの紹介
data
large language model
corpus