
.png&blockId=87a27d16-bc2f-4a0a-9950-de5d3b6ef694&width=3600)
.png&blockId=de4d05fa-f606-470a-9915-c73503660b73)
今回のブログでは、韓国語データキュレーションについて説明します。データキュレーションは、データの構築と生成だけでなく、データの活用価値を高めるすべての活動を含みます。この記事で扱うすべてのデータは、外国人もダウンロードできるデータです。 データについてのより詳しい説明は https://github.com/ko-nlp/Open-korean-corpora と https://corpus.korean.go.kr/main/requestMain.do에서 を参照してください。外国人の参加申請については、次の文書の内容を参照してください。
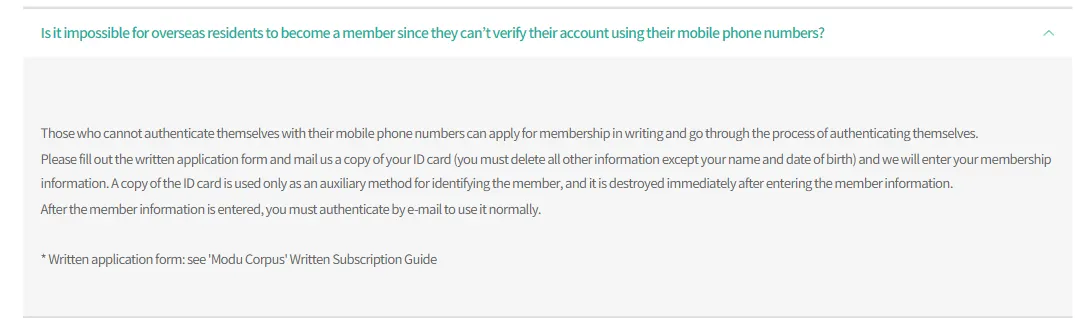
1. 韓国語コーパス構築の変化の様子
Open-korean-corporaを通じて1次韓国語データキュレーションを行った2019年には、構文解析データと類似文、並列コーパスなどが多数ありました。
<図1> データの一般的な使用と提供機関
これは、次の画像のように、形態素や文章の特性を抽出し、必要な情報を処理するデータが主に構築されたためです。
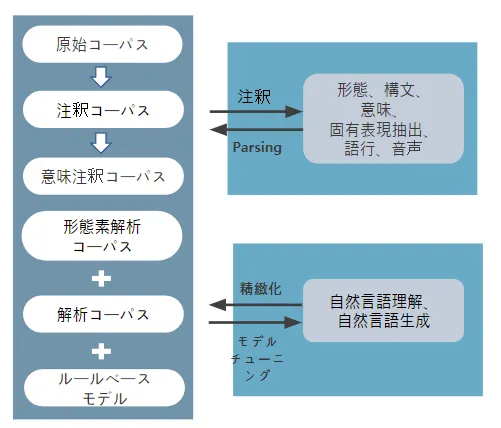
<図2>テキストデータの分析方法と自然言語処理課題の細分化
2020年から現在(2023年)まで、嫌悪表現とともに様々なテーマ(その他のテーマに含まれる)のデータが増加しました。全体的に意味分類に関連するデータが研究や産業で多く使われていることが確認できます。
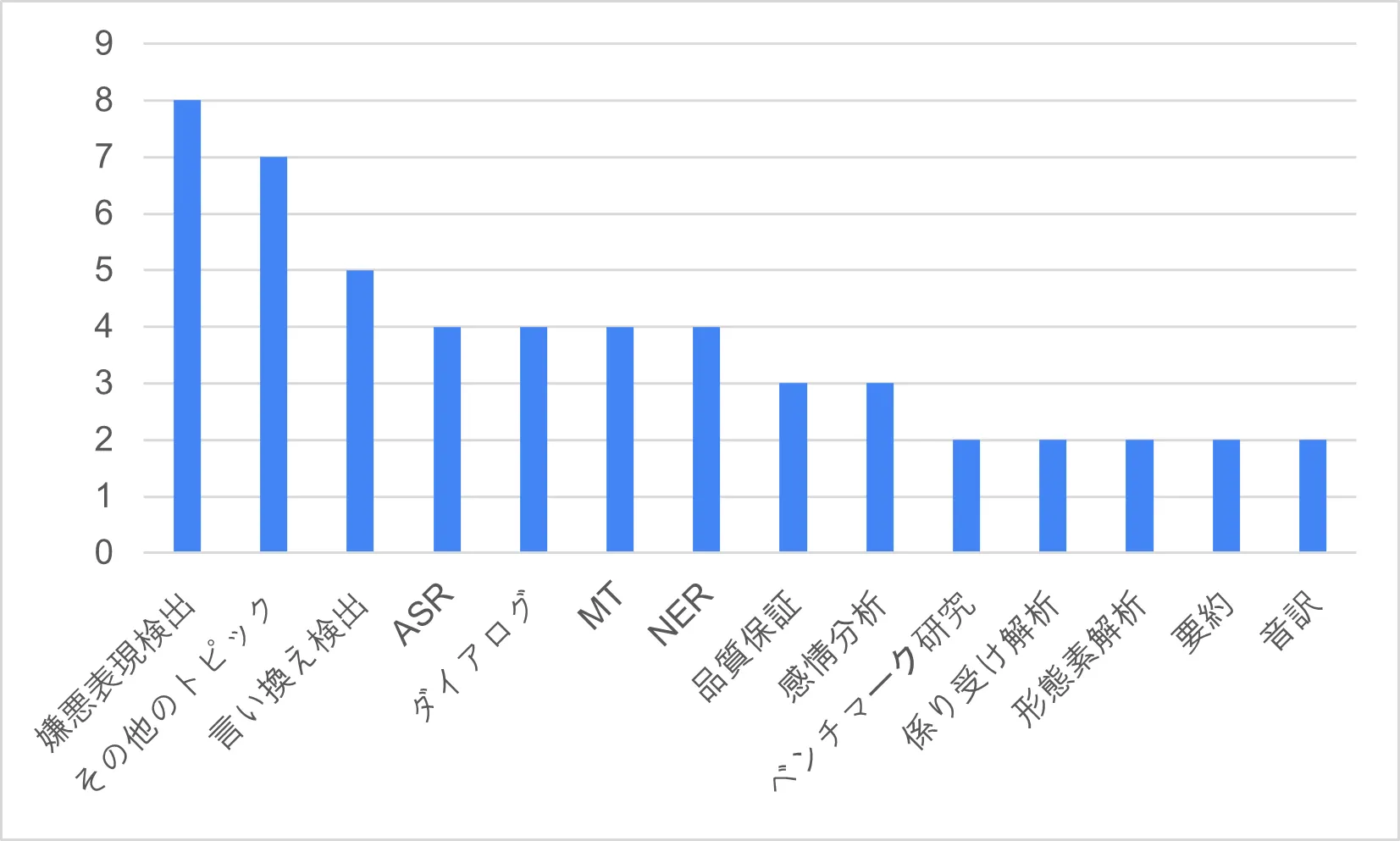
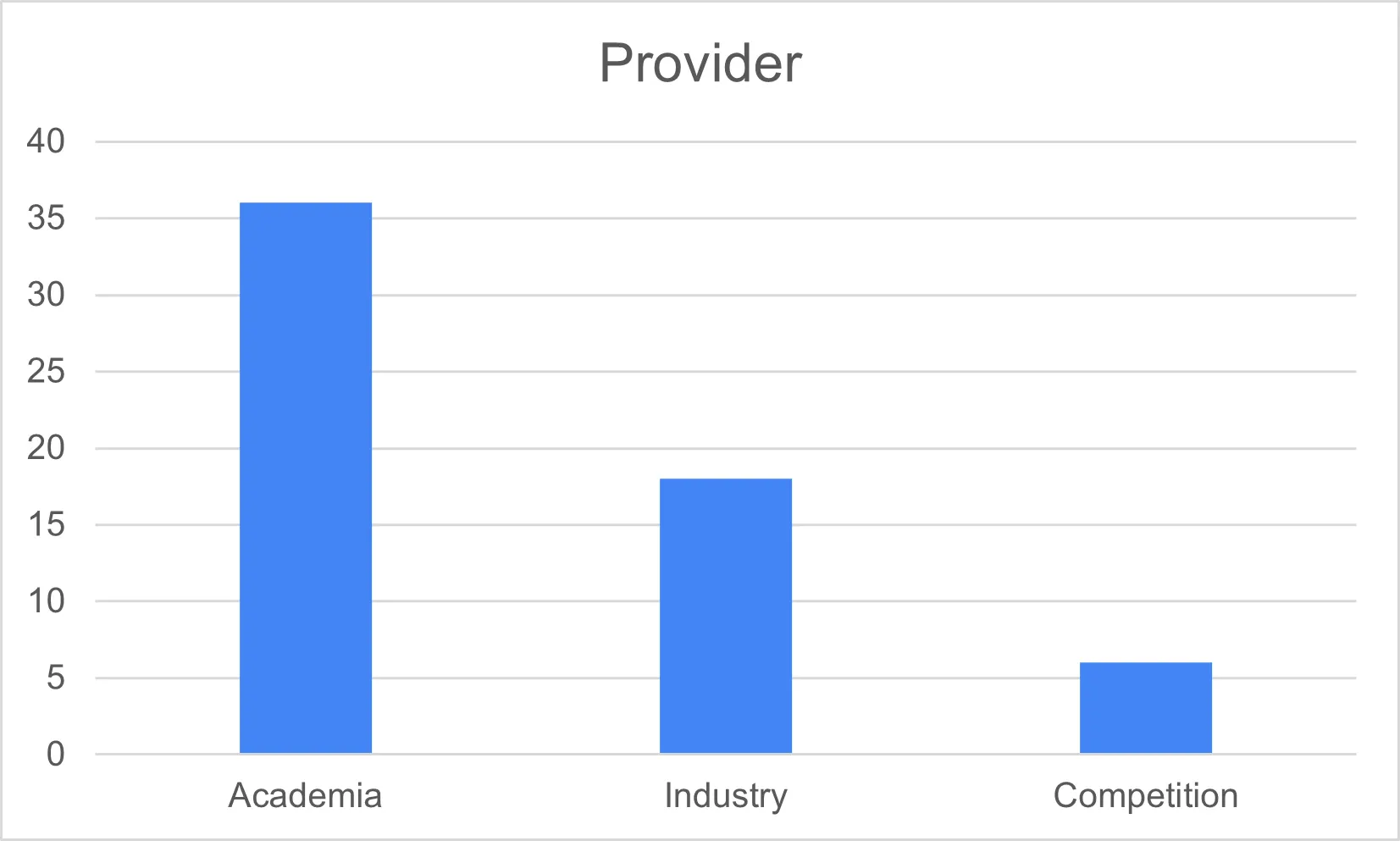
<図3> データの一般的な使用と提供機関
このような変化を反映して、時期によって多く構築されたデータを一つのイメージで表すと次のようになります。

<図4> Diachronic Overview of (Open) Korean Corpora (1990s – 2023)
From W. I. Cho, S. Moon, and Y. Song, "Revisiting Korean Corpus Studies through Technological Advances" in Proc. PACLIC, Dec. 2023.
このような変化が起こった原因として、word2vec以前は構文や形態などから得た情報を自然言語処理で主に使用したのに対し、word2vec以降は収集されたデータを精製しながら正解セットを通じてモデルを教育する方式でモデリングが行われたからです。

<図5> 自然言語処理の一般的なプロセス
つまり、word2vec以前は次のように構文を解析する研究が多く、今も様々な研究が行われています。
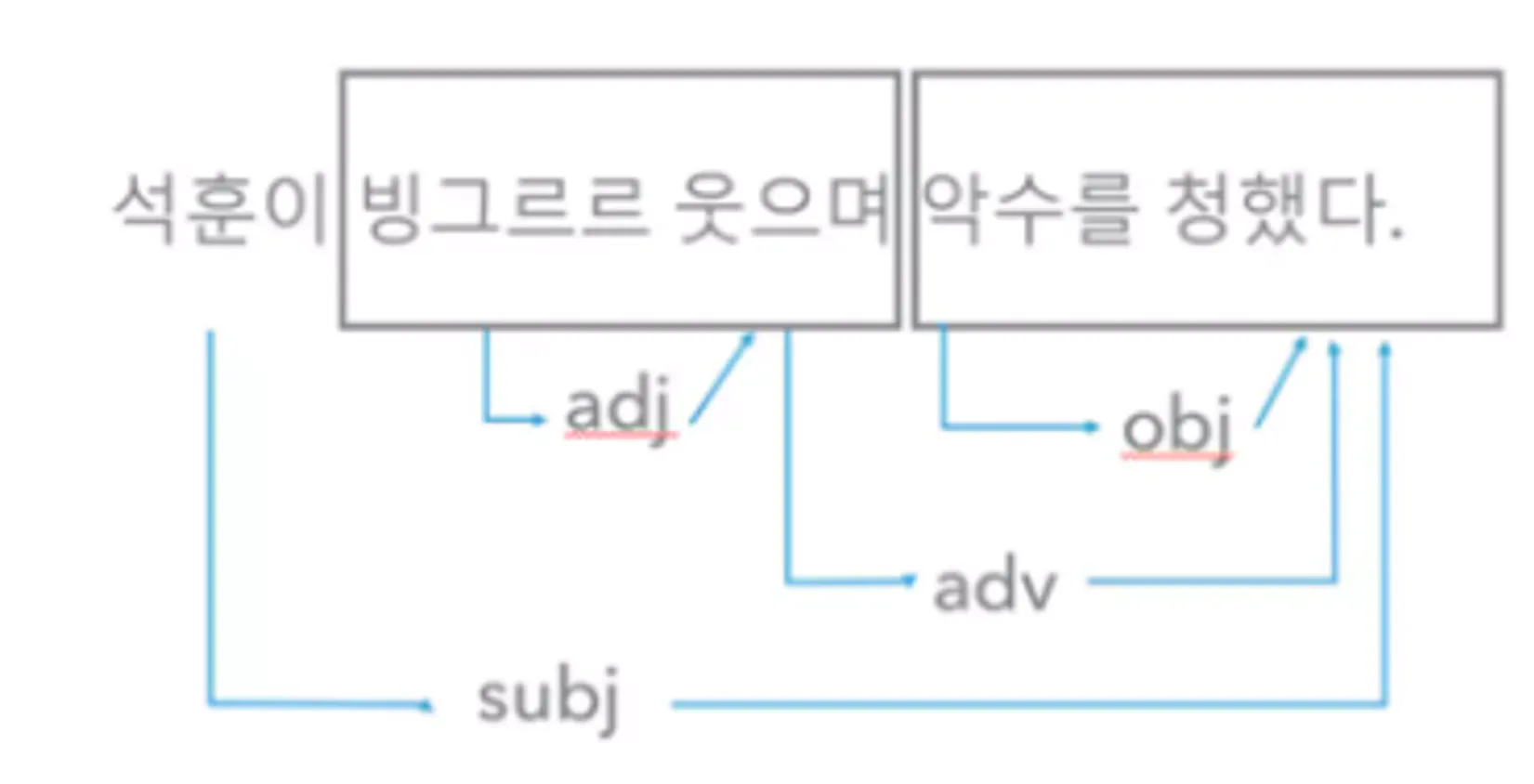
<図6>パク・ジンホ(2004)から引用、subj 主語、obj 目的語、adj 管形語、adv 副詞語
word2vec以降、ベクトル空間上で単語間の関係を把握できるようになり、NAVERの映画レビューデータのように大量のデータに肯定的な感情であれば1、否定的な感情であれば0というラベルを付けて、BERTのようなモデルがよく学習するかどうかを確認することなどが自然言語処理で主流になりました。
$ head ratings_train.txt
id document label
9976970 아 더빙.. 진짜 짜증나네요 목소리 0
3819312 흠...포스터보고 초딩영화줄....오버연기조차 가볍지 않구나 1
10265843 너무재밓었다그래서보는것을추천한다 0
9045019 교도소 이야기구먼 ..솔직히 재미는 없다..평점 조정 0
6483659 사이몬페그의 익살스런 연기가 돋보였던 영화!스파이더맨에서 늙어보이기만 했던 커스틴 던스트가 너무나도 이뻐보였다 1
5403919 막 걸음마 뗀 3세부터 초등학교 1학년생인 8살용영화.ㅋㅋㅋ...별반개도 아까움. 0
JavaScript
복사
2.コーパス構築の底辺拡大 **2.
2020年を前後して現れた著しい変化は、国家だけでなく、企業や機関もデータ構築に積極的に参加するようになったことです。国立国語院(みんなのコーパス)、情報化振興院(AI HUB、NAVER(NLP Challenge、アップステージ(Klue benchmark、スマイルゲートAI(嫌悪表現データなど)などがその例である。具体的なデータの説明は Open-korean-corpora で確認することができます。
Open-korean-corpora で取り上げられなかったが、主要データの一つである国立国語院のデータを見ると次のようになります。
コーパス名 | 発行年 | 生コーパス/タグありコーパス | 分量 | 例 |
日常会話(일상대화) | 2020 | raw | 2,232個
総容量317MB | 반려동물을 키우고 계신가요 |
語彙意味分析(어휘의미분석) | 2020 | tagged | 2019年度に構築された300万語節規模(書き言葉200万、話し言葉100万語節)とメッセンジャー会話コーパス(92万語節)を対象に形態分析と語彙意味(体言類と用言類)を分析したコーパス | "word": "제주",
"sense_id": 8,
"pos": "NNP",
"begin": 1,
"end": 3,
"word_id": 1 |
語彙関係(어휘관계) | 2020 | tagged | ウリマルセム辞書ベースの語彙関係基礎資料20万組(類似語60,000組、反対語10,000組、上位語70,000組、下位語60,000組) | 가가대소
방소
유의어 |
文法性判定(문법성판단) | 2020 | tagged | 合計19,940文(文法的な文章9,970文、非文法的な文章)
ファイル4個
合計3.19MB | 높은 달이 떴다. 4.981(평균)
달이 뜸이 높았다. 2.223(평균) |
固有表現抽出(개체명) | 2020 | tagged | 合計300万語節(書き言葉200万語節、話し言葉100万語節)
ファイル2個
合計909MB | "form": "멕시코",
"label": "LC" |
類似文章(유사문장) | 2020 | tagged | 179,589文
ファイル1個
合計42.5MB | "경기 성남시 판교신도시에서 이달 분양하는 중대형 아파트의 3.3m²당 분양가가 1500만 원 후반대로 결정될 것으로 보이는데 이는 2006년보다 200만 원 정도 싼 가격이다." |
ウェブ(웹) | 2020 | raw | ブログ 11,521件
掲示板 9,089件
ヌリ疎通網 1,989,656件
レビュー: 96,810件 | "title": "비타민 사기 진짜 어려워..",
"form": "오메가3와 비타민C, 달맞이꽃종자유 등을 사려고 몇 시간을 검색하며 공부했다. 그 결과 오염되지 않은 바다에서 잡힌 먹이사슬의 하단에 있는 생선이 좋다고 들었는데(덩치가 커지면 중금속 오염이 심하다고 함)” |
新聞(신문) | 2020 | raw | 記事3,536,491件(2009年から2018年までの10年間に生産された新聞記事年間1億語以上)
ファイル363個
合計15.6GB | 2008년의 마지막 새벽, 언론의 카메라는 서울 여의도를 향했다. 방송법 등 주
요쟁점 법안이 상정될 국회 본회의장을 두고 여야 의원들의 전쟁을 기다리고 있었던 것 |
文語(문어) | 2020 | raw | 書籍、雑誌、レポートなど著作権問題が解決された著作物10,045種の書き言葉の生コーパス
ファイル10,045個
合計4.24GB | 01범보다 무서운 곶감 |
口語(구어) | 2020 | raw | 公的独白2,490件
公的会話19,104件
準口語・台本4,102件(ドラマ)
ファイル25,696件
合計6.73GB | "title": "EBS 정오뉴스 2018년 1월",
"author": "박민영 외",
"publisher": "EBS",
"date": "20180000",
"topic": "도서관의 변신, 메이커 스페이스에 대한 기사"
"form": "미국의 공공도서관들이 새로운 모습으로 변신하고 있습니다." |
文書要約(문서 요약) | 2020 | tagged | 新聞コーパスから抽出した記事4,389件
コーパスから記事抽出後
テーマ及び要約作成した文章13,167件 | 기사 제목, 부제목-1문장, 기사, 기사 요약-2문장 이상 |
構文(구문) | 2020 | tagged | 文語200万語節
口語200万語節
文語1.07GB
口語583MB | "word_form": "판교신도시에서",
"head": 5,
"label": "NP_AJT" |
形態分析(형태분석) | 2020 | tagged | 300万語節(文語200万語節、口語100万語節)
ファイル2個
合計2.31GB | "form": "제주",
"label": "NNP" |
推論確実性(추론확신성) | 2020 | tagged | 新聞、準言語コーパスから対象談話を抽出
ファイル1個
合計272KB | 변화에 대한 적응이 항상
성공적일 수는 없다. 당신을
힘들게 하는 팀원이 당신의
리더십을 키우는 원동력임을
기억한다면, 갈등을 겪을
때마다 당신은 더욱 발전할 수
있는 기회를… |
日常会話(일상대화) | 2021 | raw | ファイル4,143個
合計560MB | 아, 지금 |
新聞(신문) | 2021 | raw | 2020年の新聞記事729,280件
ファイル35個
合計2.95GB | 대통령, 시장 방문만 하지 말고 실천해달라 |
国会議事録(국회회의록) | 2021 | raw | 5,395件
(73,478,080語節)
ファイル5,395個 307MB | 회의를 시작하도록 하겠습니다. |
推論の確実性(추론확신성) | 2021 | tagged | 문어, 신문, 구어, 대화, 파일 1개, 총 1.457KB5,395件(73,478,080語節), : ファイル5,395個、合計307MB | 선행 문장- 대상 문장 P5: 그렇게 바꾸어가면 만성 피로에 걸릴 일이 없거든요.- 후행 문장 |
オンライン会話(온라인대화) | 2022 | raw | 合計74,665件(会話メッセージ)
ファイル47,421件
合計835MB | "지금 운동하러가려고하는데 반팔 반바지 입으니까 선크림을 발라야돼” |
新聞(신문) | 2022 | raw | 2021年の新聞記事978,342件
ファイル34個
zipファイル1個
898MB | 변이 바이러스 잡는 모더나 백신 2000만명 올 2분기 한국 온다 |
メッセンジャー(메신저) | 2022 | raw | 合計3,836件(会話メッセージ691,535件)
総容量212MB | 짜쟌 |
正書法矯正(맞춤법교정) | 2022 | tagged | 約400万語節
ファイル1個
合計517MB | 하이하이 |
固有表現連結(개체명연결) | 2022 | tagged | 合計約1,100万語節(ウェブ500万、文語300万、口語300万語節)
ファイル数323個
総容量255MB | "id": 2,
"form": "고대",
"label": "DT_DYNASTY",
"begin": 27,
"end": 29,
"kid": "07070000000019",
"wikiid": "378315",
"URL":
"https://ko.wikipedia.org/wiki/%EA%B3%A0%EC%A0%84_%EA%B3%A
0%EB%8C%80” |
国立国語院のコーパス申請及び活用方法は、以下の動画から確認できます。


3. 事前学習モデルの発展と学習用データセット
•
SKTBrain/KoBERT : 韓国語版Wiki文 (5M)
•
klue/roberta : みんなのコーパス, コモン・クロール, Namu wiki, NAVERニュースクロール, 国民請願
•
monologg/KoELECTRA :
◦
v1、v2の場合約14G Corpus(2.6B tokens)(ニュース, Wiki, Namu wiki)
◦
v3 すべてのコーパス 約20G追加 (新聞、文語、口語、メッセンジャー、ウェブ)
•
ChatGPT以降は、Llamaなどの大規模言語モデル(LLM)が登場し、Fine tuningやInstruction tuningのようなチューニング技術が主要な研究や開発分野に適用され始め、大規模言語モデルに入力として使用される生データ、質疑応答、マルチターンデータとチューニングに使用する生成データ及び生成モデルの評価に使用するテストデータが主に構築されました。大規模言語モデルとインストラクションデータは次の回で扱う予定です。
参照
•
朴鎭浩(2004), 韓国語の情報化と構文解析, 月印
•
Won Ik Cho, Sangwhan Moon, and Youngsook Song. 2020. Open Korean Corpora: A Practical Report. In Proceedings of Second Workshop for NLP Open Source Software (NLP-OSS), pages 85–93, Online. Association for Computational Linguistics.
•
Won Ik Cho, Sangwhan Moon and Youngsook Song(2023), Revisiting Korean Corpus Studies through Technological Advances, " in Proc. PACLIC 2023
•
一部の画像は次の発表資料を再利用しています https://github.com/songys/pycon2018_keynote