


cleanUrl: "/cuda-tokenizer"
floatFirstTOC: left
YAML
복사
最近、LLMは既存のアクセラレータ用の言語以外にも、基本的なC、numpyのような基礎的な言語で実装されています。これは学習と理解の目的はもちろん、性能の最適化など様々な理由で大きな意味を持ちます。
しかし、その大部分は簡略的な実装で多言語のサポートができない場合があります。
このような部分をもっと原理を理解してから実装すれば、様々なデバイス(NPU、GPU、FPGA)での実装と低レベル、高性能が必要なトークン生成戦略に直接的に大きく役に立ちます。
本記事では、純粋なCUDAおよびC文法に従いながら、最小限の実装でllamaモデルを推論し、その過程でLLMの多言語マルチバイト言語を扱う方法を説明します。
(llama3 cuda base code - )
LLMは強力な性能を発揮しながら、様々な活用も進んでいます。
自然言語処理の観点で、このようなLMの性能と欠点を大幅に改善したポイントの一つは**OoV(Out of Vocabulary)**問題の解決です。
一般的に自然語は、機械が理解しやすい数値単位に分解・変換された後、適切なエンベデッドベクトル、テンソルなどによって「意味的なエンベデッド」の処理を行います。
ここで、Vocabularyを大きくすればするほど、モデルと計算性能に負担がかかり、反対に小さくしすぎると、使用、理解する語彙の不足でモデルの性能が低下する場合があります。
それを解決するための代案の一つが、本稿で紹介するBPE(Byte Pair Encoding)形式の様々な派生アルゴリズムです。現在、多様なアルゴリズムと方法論が知られていますが、核心の原理は簡単です。
OoVで発生した UNK_ つまり、知らない語彙を言語的に最小単位である形態素より小さい単位に分解します。もっと正確には機械の表現であるバイトレベルまで分解します。
例えば、 という絵文字は次のようなUnicodeで定義され、(U+1F44C)
という絵文字は次のようなUnicodeで定義され、(U+1F44C)
という絵文字は次のようなUnicodeで定義され、(U+1F44C)UTF-8エンコーディング形式では、[0xF0, 0x9F, 0x91, 0x8C]のように4バイトをリストすることで表現されます。
上記のように多言語及び拡張文字がOoVが発生した場合、BPEアルゴリズムはこれを複数バイトに分割して2~4個のトークンに割ります。
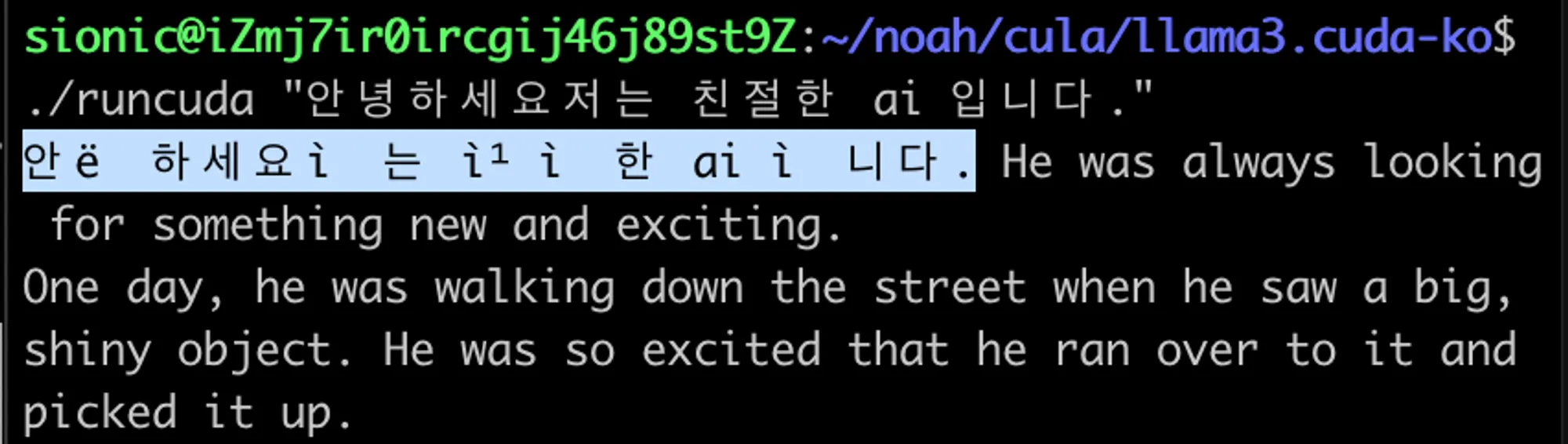
そのため、これを適切な表現とトークンの再合成によって出力をする必要があります。単純にBPEで発生したバイト順序列を出力すると、下記のような不自然な結果が得られます。
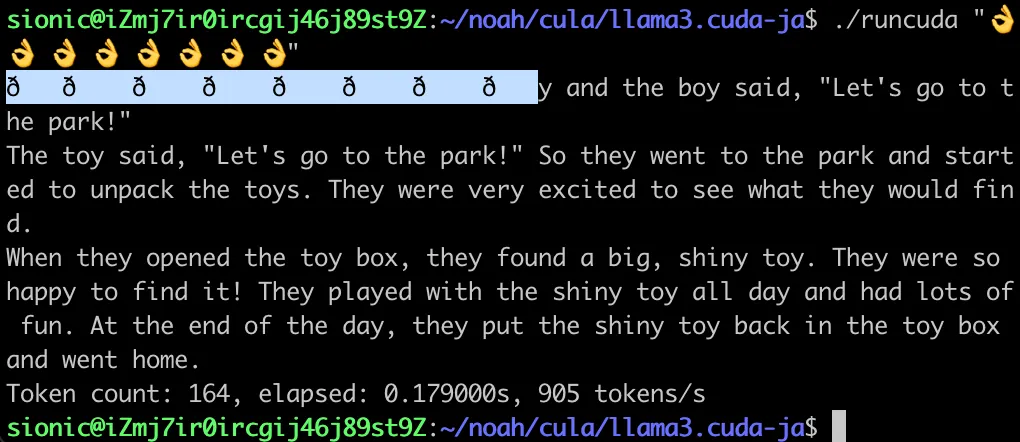
このような場合、該当トルクナイザを使うと簡単な問題ですが、今はC言語レベルの最小限の実装でその原理を理解する時間なので、少しリバースエンジニアリングを通じてアプローチしてみます。
まず、その出力を全てトークンまたは文字列の長さを測定して、その内容をバイト単位の16進数で分けて出力してみます。
一番最後の数字が文字列の長さであり、例えば2である場合、バイト1、バイト2、ヌル文字、該当文字列の出力値、長さの順番になります。 出力コードは下記のようになります。
void safe_printf(char *piece) {
...
int cutbit = 0xff;
int len = strlen(piece);
if (len == 0) {
printf("%02X %s %d \n", piece[0] & cutbit, piece, strlen(piece));}
if (len == 1) {
printf("%02X %02X %s %d \n", piece[0] & cutbit, piece[1] & cutbit, piece, strlen(piece));}
if (len == 2) {
printf("%02X %02X %02X %s %d \n", piece[0] & cutbit, piece[1] & cutbit, piece[2] & cutbit, piece, strlen(piece));}
if (len == 3) {
printf("%02X %02X %02X %02X %s %d \n", piece[0] & cutbit, piece[1] & cutbit, piece[2] & cutbit, piece[3] & cutbit, piece, strlen(piece));}
if (len == 4) {
printf("%02X %02X %02X %02X %02X %s %d \n", piece[0] & cutbit, piece[1] & cutbit, piece[2] & cutbit, piece[3] & cutbit, piece[4] & cutbit, piece, strlen(piece));}
unsigned char header = piece[1] & cutbit
if (header == 0xC3){
unsigned char mask = 0x40;
unsigned char payload = piece[1]
unsigned char decode = payload | mask;
printf("%c", decode );
}else if(header == 0xC2) {
printf("%c", payload);
}else{
printf("%s", piece);
}
C
복사
例題で値を16進数で出力して確認する理由は、1バイト、8ビットを常に2桁の16進数で表現できるため、4ビット単位の基数的な直観性のためです。
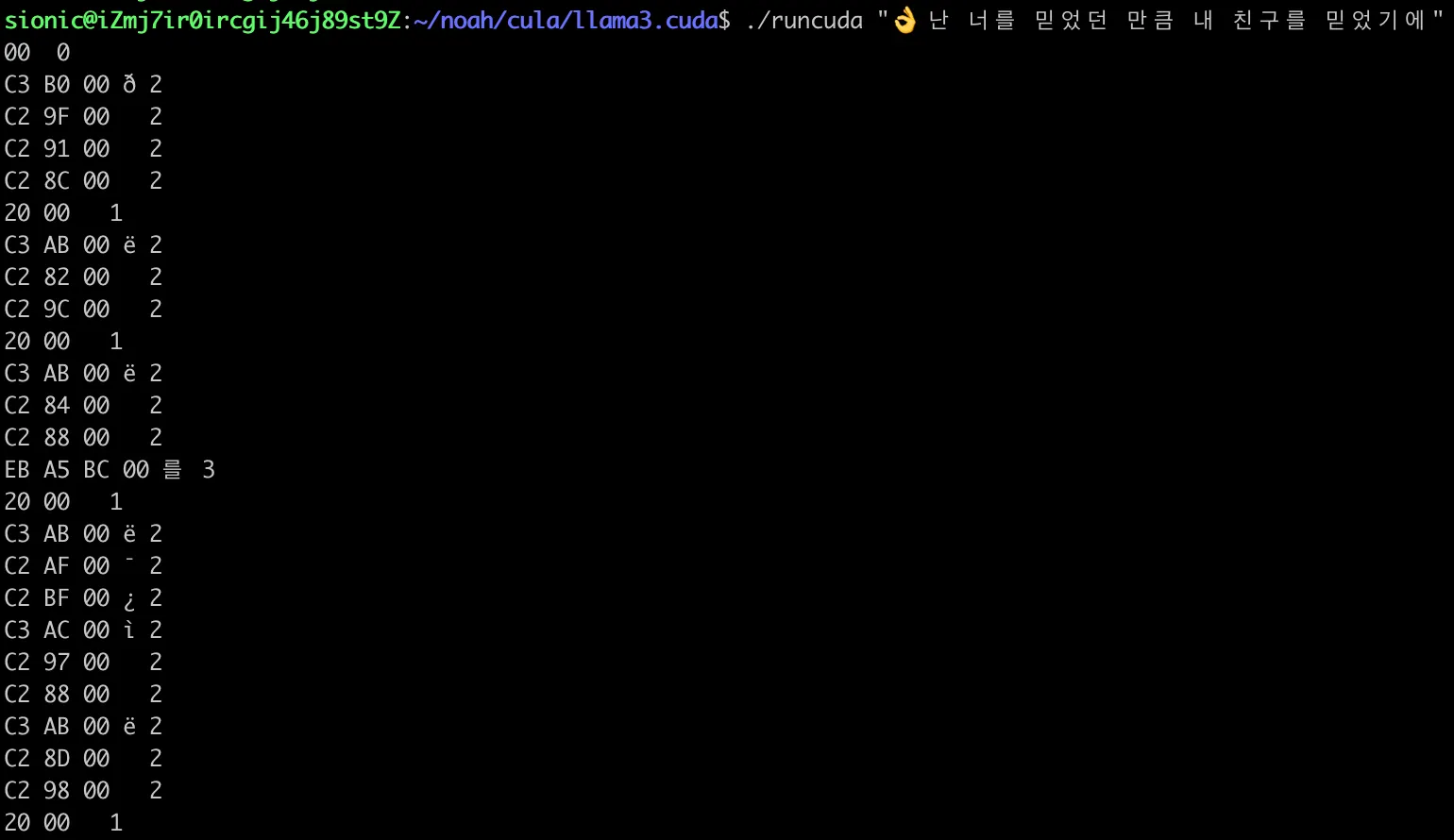
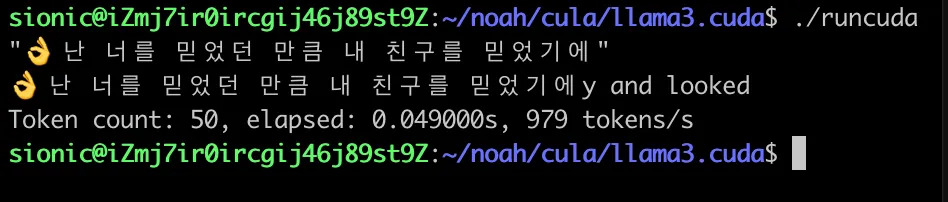
’난 너를 믿었던 만큼(私はあなたを信じていた分だけ)’っていうハングルの歌の歌詞の文章が該当llama.cudaプロジェクトの出力構文で順番に出力されることが確認できます。
난 너를 믿었던 만큼(私はあなたを信じていた分だけ)’っていうハングルの歌の歌詞の文章が該当llama.cudaプロジェクトの出力構文で順番に出力されることが確認できます。#👌
C3 B0 00 ð 2 # 👌 - TrailByte and bit masking
C2 9F 00 2 # 👌 - 2番目のバイト
C2 91 00 2 # 👌 - 3番目のバイト
C2 8C 00 2 # 👌 - 4番目のバイト
#
20 00 1 # 空白
#난
C3 AB 00 ë 2 # 난
C2 82 00 2
C2 9C 00 2
#
20 00 1 # 空白
#너
C3 AB 00 ë 2 # 너
C2 84 00 2
C2 88 00 2
#를
EB A5 BC 00 를 3 # 를
20 00 1
#믿
C3 AB 00 ë 2 # 믿
C2 AF 00 ¯ 2
C2 BF 00 ¿ 2
#었
C3 AC 00 ì 2 # 었
C2 97 00 2
C2 88 00 2
#던
C3 AB 00 ë 2 # 던
C2 8D 00 2
C2 98 00 2
#
20 00 1 # 空白
#만
EB A7 8C 00 만 3 #만
Markdown
복사
ここでいくつかルールを見つけることができます。自然言語処理で広く使われていた方法の一つであるBIO(Begin, Inside, Outside)タグ付け手法に似たルールです。
マルチバイトトークンが出力される場合
トークンの最初のバイトがC3
そのバイトの中間連結トークンはC2
その他のトークンは通常のUTF-8ヘッダ範囲
つまり、次の絵文字トークンは次のような4つの長さ2文字列で出力されます。
は次のような4つの長さ2文字列で出力されます。 C3 B0 00 ð 2 # 👌
C2 9F 00 2
C2 91 00 2
C2 8C 00 2
Markdown
복사
実際のUTF-8エンコーディング形式では、それぞれ2番目のトークンであるB0 9F 91 8C 4つの順序列で表現されるように見えますが、実際に出力を進めてみると、未知の文字が出力されることがわかります。 ここのB0の場合、一般的なutf-8の文字形式ではなく、いくつかのルールによって最初のトークンが変換されていることが推測できます。
•
実際のUTF-8: F0 9F 91 8C
•
出力されたバイト: B0 9F 91 8C
C3 B0 00 ð 2 # 👌 - TrailByte and bit masking
C2 9F 00 2 # 👌 - 2 Second byte
C2 91 00 2 # 👌 - 3 Third byte
C2 8C 00 2 # 👌 - 4 Fourth byte
Markdown
복사
Unicodeの定義では、上記の絵文字のバイト列は次のようになります。
[0xF0, 0x9F, 0x91, 0x8C ]
よく見ると、特定のビットだけがマスキングされることが確認できます。
このルールを単純なビット演算で考えると、次のようになります。
1 1 1 1 0 0 0 0 -> F0
- 1 0 1 1 0 0 0 0 -> B0
------------------------
0 1 0 0 0 0 0 0 -> 40
Markdown
복사
上記のように、左2番目のビットだけOR演算が処理される単純なルールがあることがわかります。
そのビットマスクは2進数表現で 0 1 0 0 0 0 0 0 0 0 , 16進数表現で (0x40) なので、" | 0x40 " 演算を追加します。
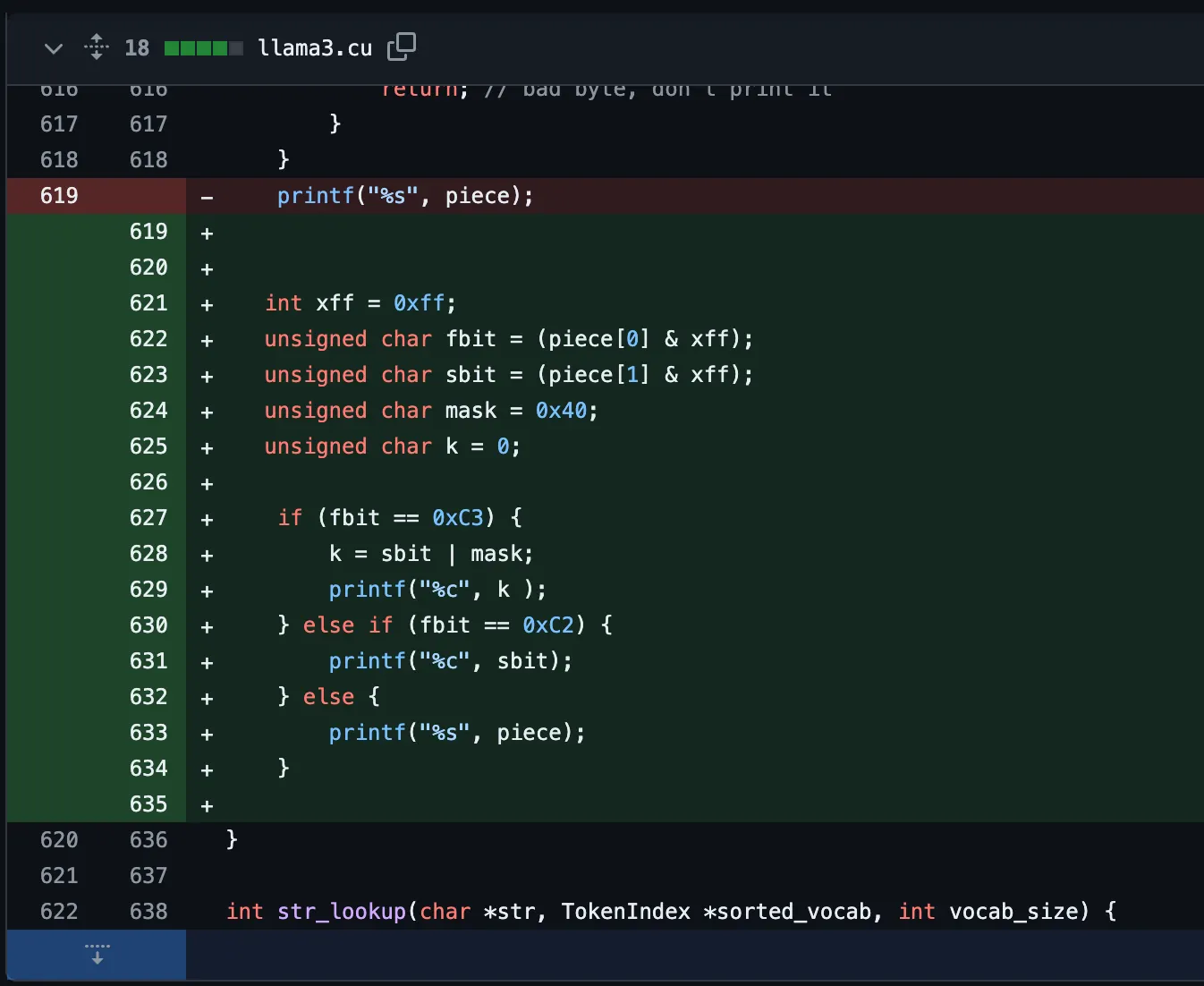
最終的なコードは次のようになります。
1. &マスクを使用して明示的に1バイトだけ残します。
2. 特殊なヘッダーが存在する場合、適切なビット演算でutf-8標準範囲に変換します。
3. マルチバイトはstdoutストリームに1バイト単位で出力します。
4. その他完成されたトークンは文字列単位で出力します。
上記のような実装は、標準的な構成ではなく、逆工学的な観点での最小限の実装を使用するため、予期しない問題が発生する可能性があります。
しかし、cudaまたは低レベルの言語で最小限の実装とデバイスレベルの領域でバイトストリームを制御し、トークン単位の生成戦略を実装し、完全に理解できるため、高い価値を持っています。
一部のルールはクエリ文としても記述できるため、様々な環境で根本的なレベルでLMを理解し、使用することもできます。
Out of Vocabulary(OoV) OoVの問題は、モデルがその単語の事前知識がないため、その文脈を解釈するのに苦労することが原因となります。
よく学習過程で見られなかったか、単語辞書を最適化するために意図的に削除された場合に発生します。
このような現象は、モデルが言語を理解し、生成する際に潜在的な不正確さを発生させる可能性があります。OoVの単語を理解せずに生成された文章は、意味を正確に把握することが困難であり、精度が低下し、深刻なエラーが発生する可能性があります。
C3,C2の場合、マルチバイトUTF-8文字の始まりを知らせる、つまり、OOVで処理されるマルチバイトの始まりを意味します。したがって、この文字列にパターンを利用して簡単にが処理されない問題を解決することができました。
日本語訳
→#
→#
→#私は
→#
→#あなたを
→#を
→#信じて
→#いた
→#分
→#
→#だけ