
.png&blockId=235ef201-4544-4c8f-ab14-228a94038879&width=3600)

はじめに
•
推論とは、すでに知られている事実をもとに新たな判断や結論を導き出すことである。推論は知的活動をする上に不可欠な能力である。
•
したがって、LLMがどのような推論能力を示すかは、人々がAIが本当に「知能」を持っているかを体感する重要な要素といえる。
•
Scratchpads, Chain of Thoughtsなどをはじめ、LLMが持つ推論能力を最大限に引き出すための研究が継続的に行われている。
•
この記事では、推論をより効率的に行うために2段階に分けてアプローチしたSelf-Discoverという方法を紹介する。
•
概要
•
一行要約 : 与えられたタスクに合わせて詳細な解法を設計し、各事例別に設計した推論方法を基に解くと効果が良いという内容である。
•
人が通常問題を解く時、問題タイプによって具体的な推論方法を設計してから、実際の解答をすることをLLMに適用した方法。
•
複数のLLM、複数のタスクで全体的に性能向上の効果を持つ。
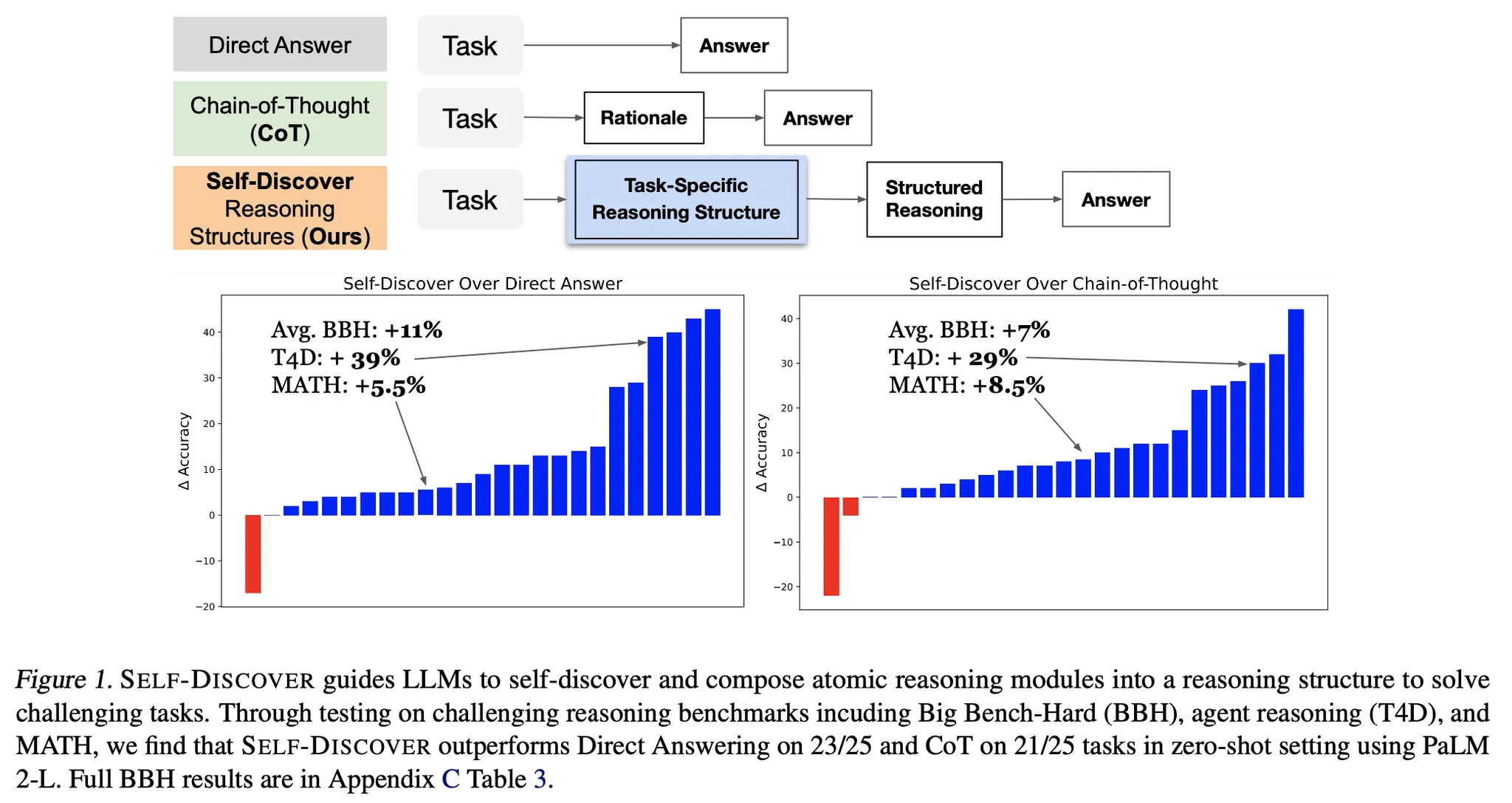
方法論の詳細
•
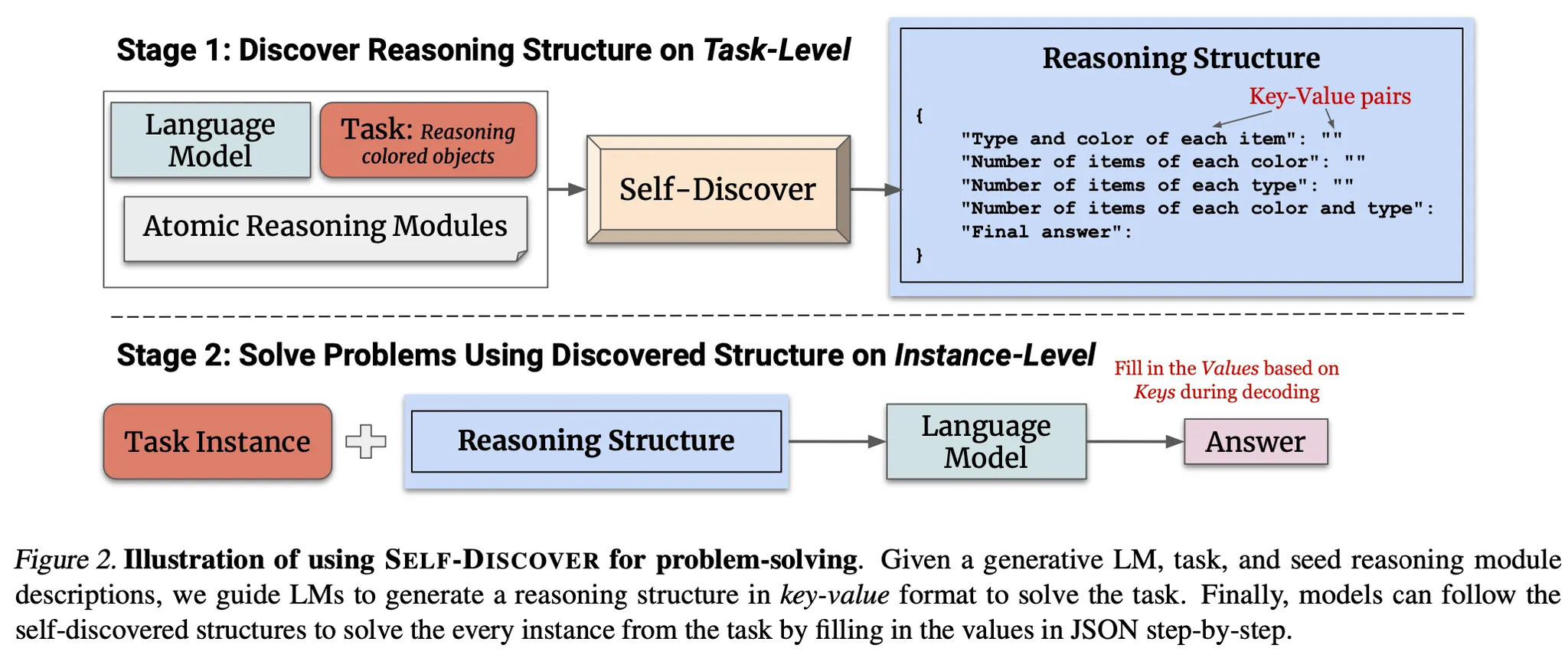
推論問題を次の2つのStageに分けてアプローチする。
•
Stage 1 : Self-discover task-specific structures

◦
Stage 1は次の3つの段階を経て進む。
◦
Select : Labelが付いてない例題データを見て、事前に定義した合計39種類のreasoning module(下図参照)の中から適切なモジュールを選ぶ段階。
**例)**小説を生成する -> "creative thinking"

◦
Adapt : 先ほどのselect段階で選択したreasoning modulesをそれぞれタスクに合う詳細なdescriptionで書き直す段階。
**例)**計算問題 : "break the problem into sub-problems" -> "calculate each arithmetic operation in order"
◦
Implement : 先ほどのadapt段階で生成した詳細なdescriptionを基に、実際の問題解決の時に使用するkey-value pair形式の詳細なreasoning structureを生成する段階。この段階のプロンプトには、他のタスクに対して人が作成した詳細なreasoning structureの例示データを入れる。
•
Stage 2 : Tackle tasks using discovered structures

◦
Stage 1で最終的に生成したReasoning structureを入力して、各事例を実際に推論する段階。
◦
Reasoning structureの各key(推論sub-step)に該当するvalueを生成して最終答えを導き出す。
結果
•
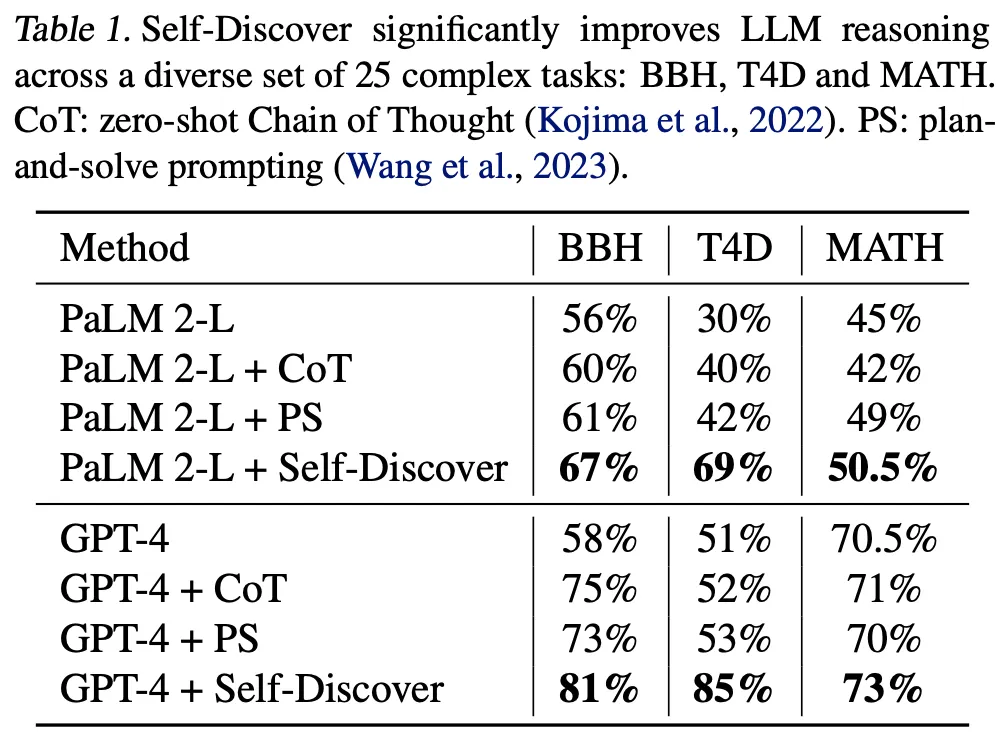
使用LLM : GPT-4, PaLM 2-L
•
Tasks
◦
◦
◦
•
Baseline 1(基本方法論と比較) : Direct prompting, CoT, plan-and-solve
◦
基本的な方法論に比べ、すべてのケースで性能の向上が観察された。
◦
特に様々なworld knowledgeが必要な問題で向上が顕著。

•
Baseline 2(事前に定義した推論モジュールを活用する方法との比較) : CoT-SC, Majority voting, Best of each RM
◦
より少ない推論の回数でより優れた性能を達成。

追加分析
•
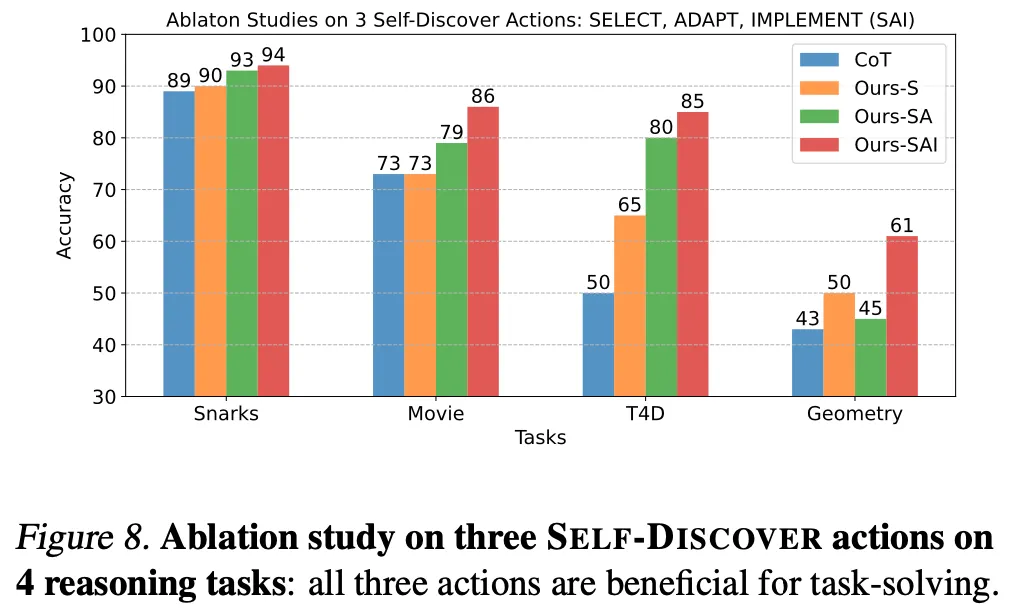
Stage 1の3段階は全て効果がある。
•
Stage 1を通じて生成したプロンプトがLLM間transferrabilityが存在する。

◦
PaLM 2-Lで生成したプロンプトをGPT-4に適用して推論を行う。
◦
比較対象の方法であるOPROは20%のデータを活用した方法であるにもかかわらず、zero-shotで生成したself discoverがより良い。ただし、GPT-4で生成して推論した場合より若干劣る(T4Dで85% vs 79%)。
◦
GPT-4で生成したプロンプトを小さなモデルに適用した場合、CoTに比べて性能がより良い : BBH性能でGPT-3.5-turbo(51% → 56%), LLaMA 2 70B(42% → 52%)
議論事項
•
AIの推論能力は、LLMが登場して初めて意味のあるレベルで発現し始めた。
•
最近の研究は、主に人が問題を解くときにアプローチする方法を適用する試みで効果を見た事例が多数存在し、この論文もその一つと見ることができる。