

この記事の前半ではSuper-NaturalInstructions(SuperNI)論文を概観した後、後半ではSuperNIに含まれるデータセットのうち、韓国語であったり、興味深いテーマを含んでいるデータセットを紹介します。

論文紹介
概要
•
SuperNIはAllen Institute for AI、University of Washington、Arizona State Universityをはじめとする合計21機関所属の研究者が参加し、1600余りのNLP instructionデータを作成し、公開したプロジェクトです。
◦
•
https://arxiv.org/abs/2104.08773で61個のタスクに関するデータを公開することからスタート。
•
合計88人のコントリビューターが既存の公開されたNLPデータを活用し、クラウドソーシングするなどの方法で作業
•
Tk-Instruct(英語)及びmTk-Instruct(多言語)モデル開発
◦
それぞれT5とmT5モデルをSuperNIデータでfine-tuning
◦
119種類の英語タスクでInstructGPT比ROUGE-Lスコア基準9.9点向上
◦
35種類の英語以外の言語タスクでInstructGPT比13.3点向上
方法論の詳細
•
データ構造
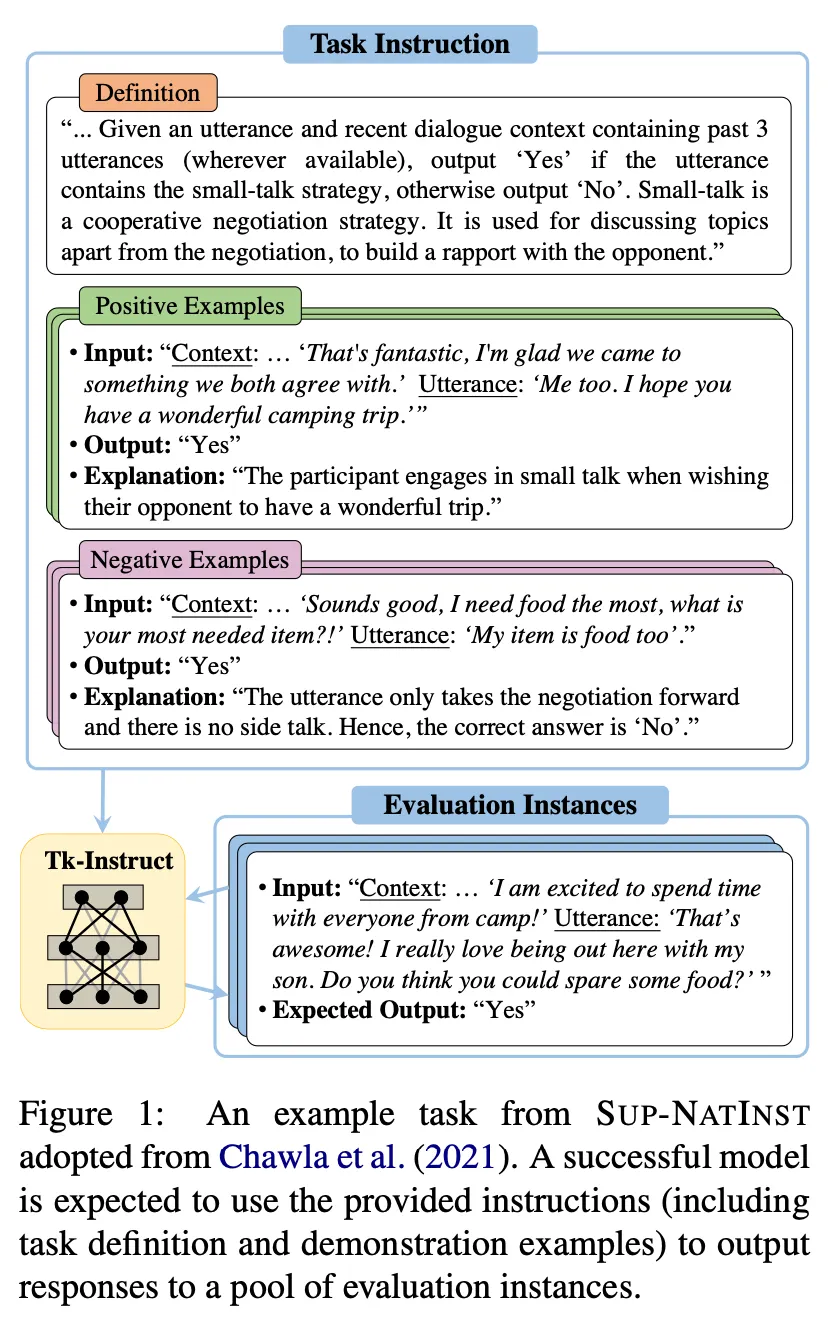
◦
Definition : タスク遂行のためのinstruction
◦
Positive examples : input / correct output / 関連する説明で構成
◦
Negative examples : input / incorrect output / 関連する説明で構成
◦
Evaluation instances : Tk-Instruct及びmTk-Instructモデルの学習には使わず、 evaluationのみに使用するテストデータ. タスク別バランスを合わせるため、最大6500個に制限
•
SuperNIデータセットの簡単な統計分析
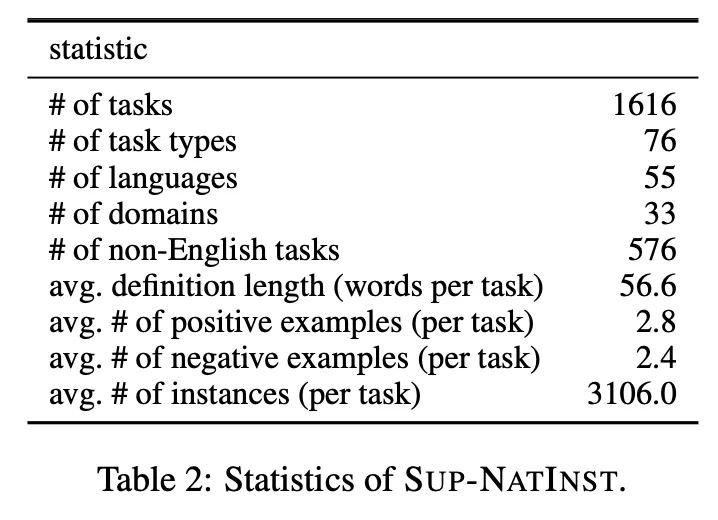
•
SuperNIに含まれるTaskの種類と他のinstructionデータセットとの比較
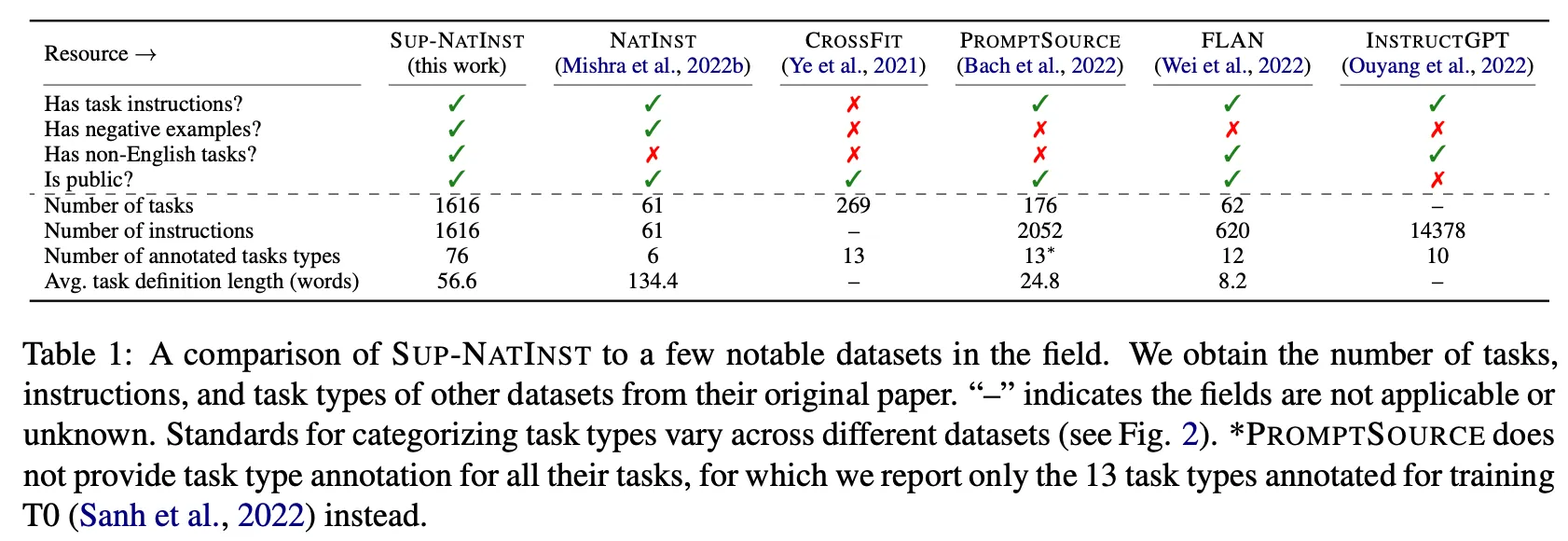
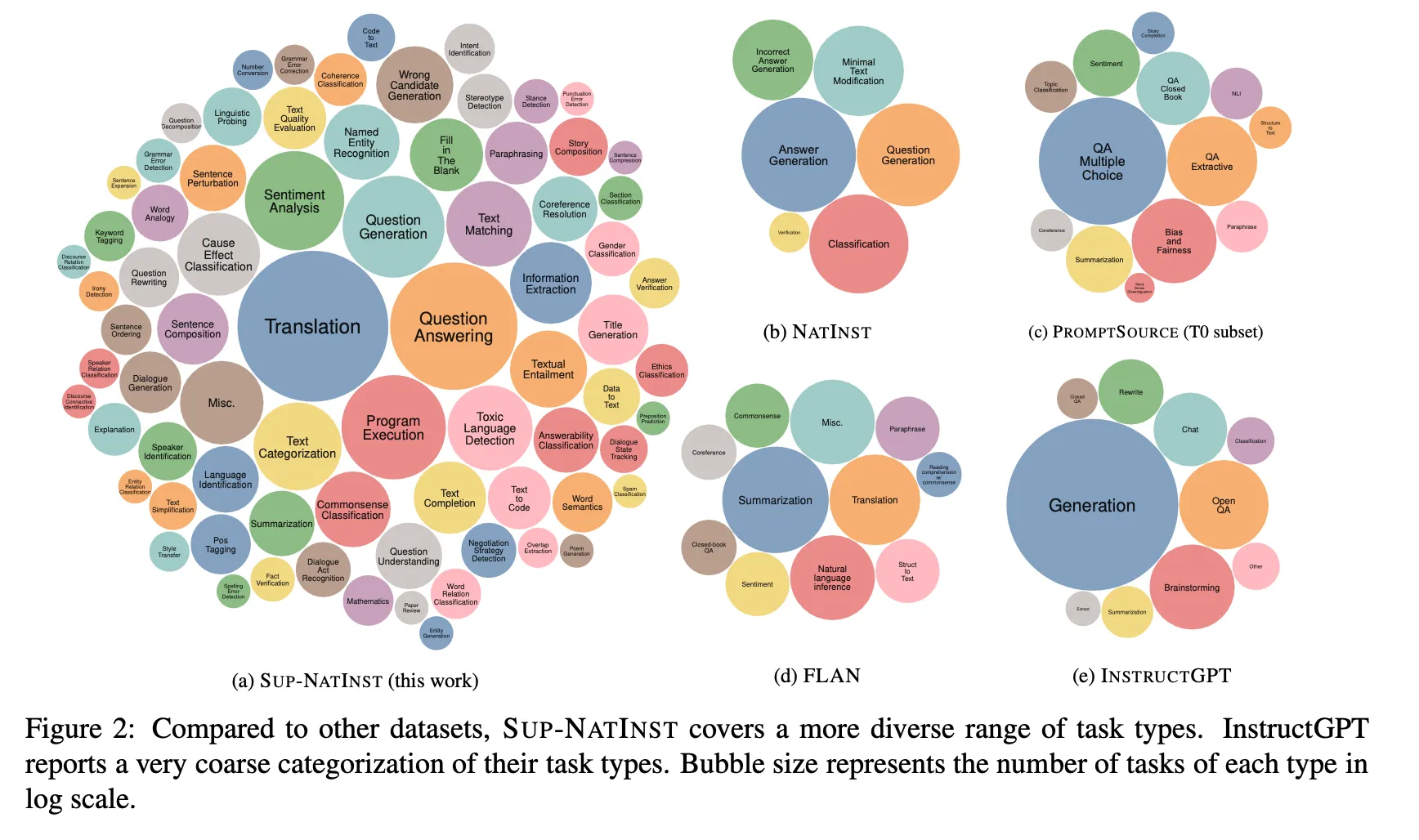
結果
•
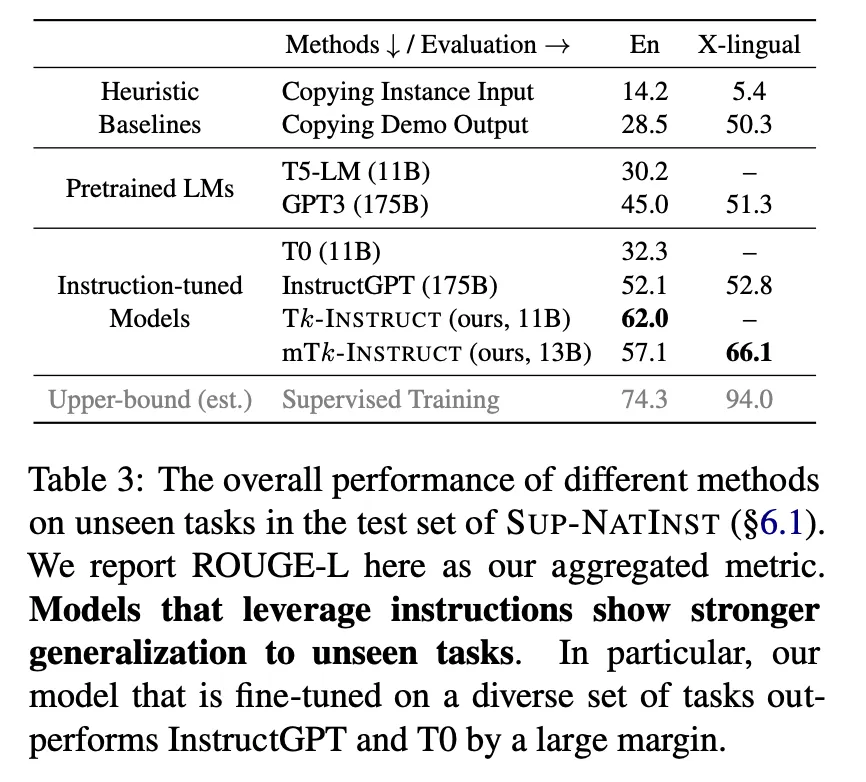
全体の結果サマリー
◦
英語:発表当時基準InstructGPT対ROUGE-Lスコア基準で9.9点高い(52.1 vs 66.0)
◦
多言語:発表当時基準InstructGPT対ROUGE-Lスコア基準で13.3点高い(52.8 vs 66.1)
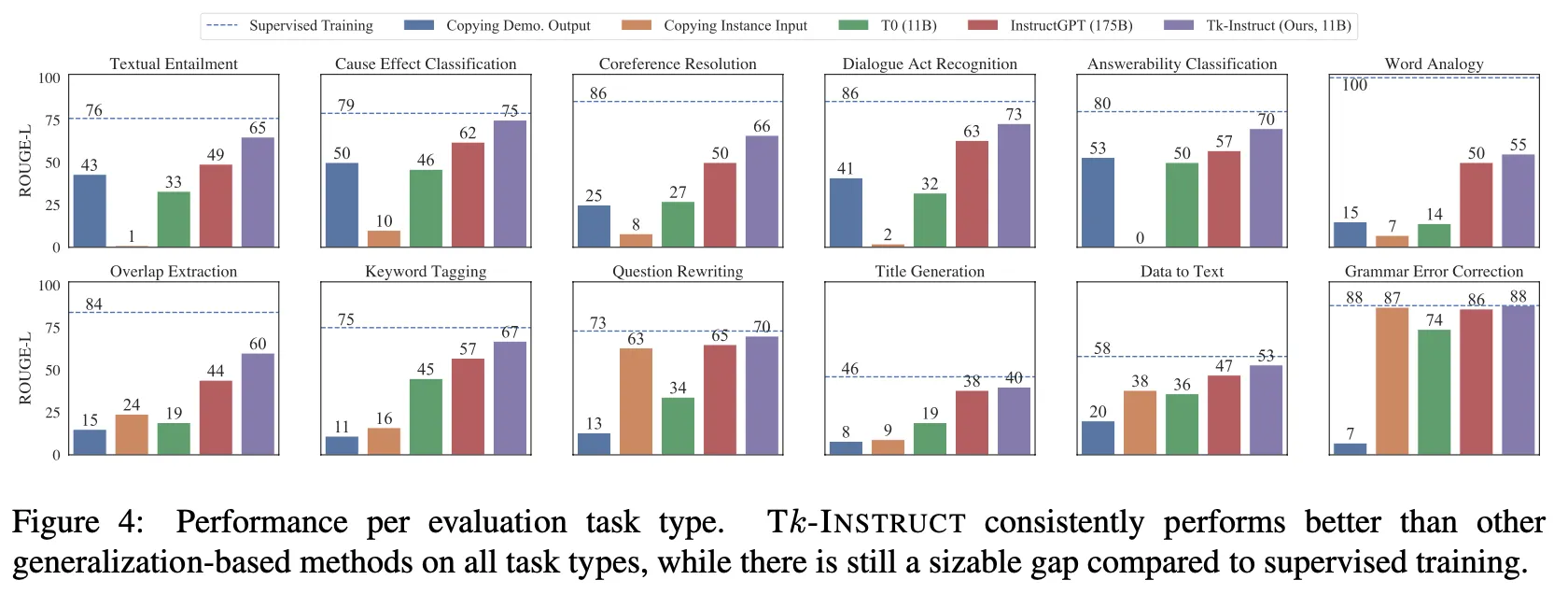
•
タスクのタイプ別性能比較
◦
すべてのタイプでInstructGPTより優れており、一部のタイプではsupervised SOTA性能とほぼ同程度

主要データの紹介
データに最も多く含まれたカテゴリ
•
上位カテゴリーを見ると、上記の論文レビューから分かるように翻訳に該当する課題が最も多く、翻訳以外にも質疑応答、プログラム実行("Generating text that follows simple logical operations such as "repeat", "before", "after" etc."などの課題)、質問文の自動生成、感情分析、カテゴリー分析、文の類似性評価、敏感なテーマ検出、因果関係分類、情報抽出などが多い
•
ソースデータとして最も多く使用されたデータを見ると、次の表で確認できるようにウィキペディアであることが分かる
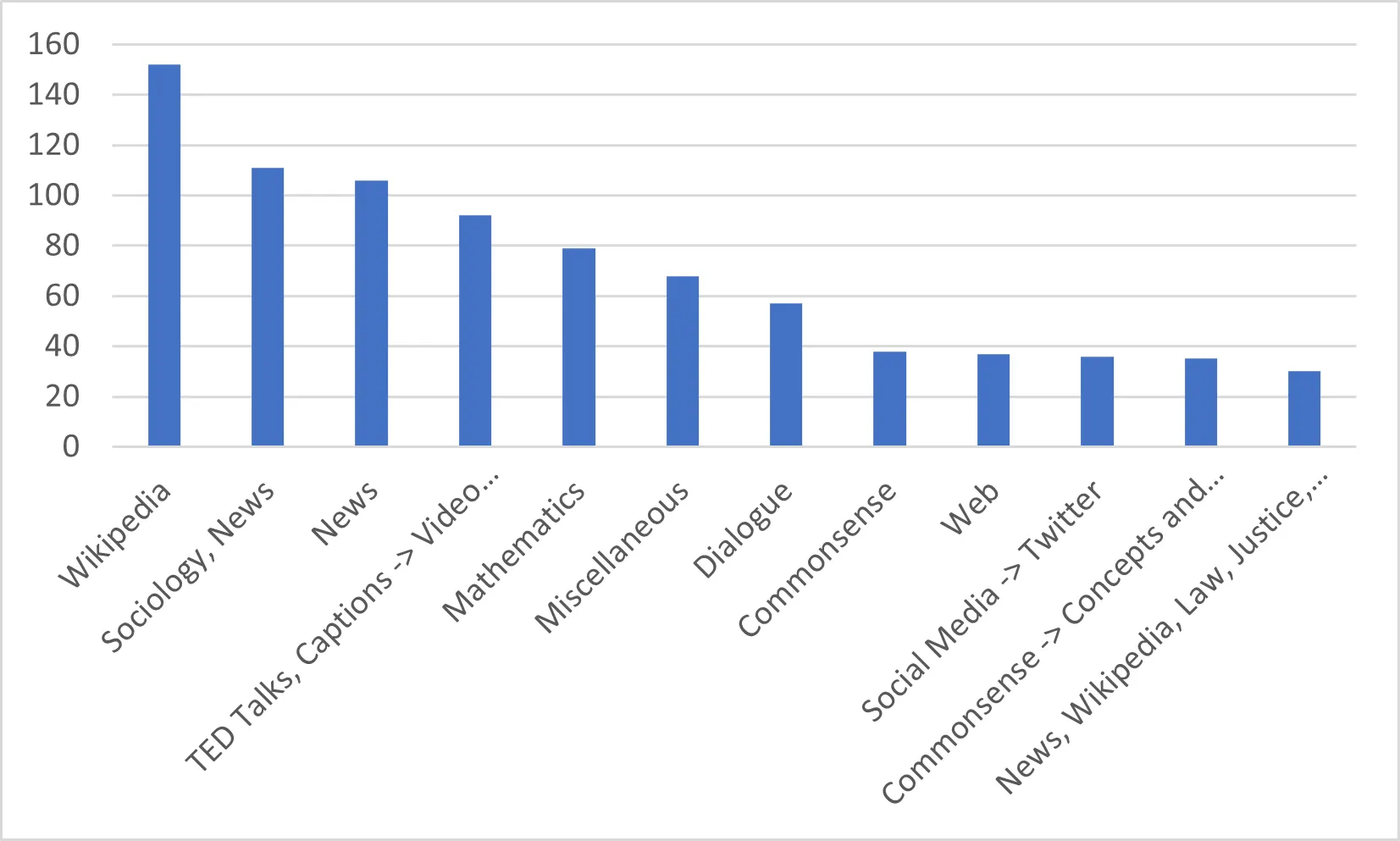
•
そのほか、ニュースやウィキペディアとニュースを一緒に使うことが多く、数式、会話、一般常識、SNSデータなどが多く使われている
使用言語
言語 | データ量 | 言語 | データ量 | 言語 | データ量 |
English | 1243 | Urdu | 10 | Assamese | 1 |
Spanish | 27 | Galician | 9 | Burmese | 1 |
Japanese | 25 | Hebrew | 9 | Czech | 1 |
Persian | 24 | Catalan | 7 | Dutch | 1 |
Hindi | 20 | Korean | 7 | Greek | 1 |
Chinese | 15 | Dutch, English | 4 | Igbo | 1 |
Gujarati | 15 | Bulgarian | 3 | Kannada | 1 |
Telugu | 14 | Croatian | 3 | Kurdish | 1 |
Arabic | 12 | Swedish | 3 | Lithuanian | 1 |
Bengali | 12 | Turkish | 3 | Malay | 1 |
French | 12 | Central Khmer | 2 | Nepali | 1 |
Marathi | 12 | Filipino | 2 | Norwegian | 1 |
Italian | 11 | Finnish | 2 | Romanian | 1 |
Malayalam | 11 | Indonesian | 2 | Sinhala | 1 |
Oriya | 11 | Lao | 2 | Slovak | 1 |
Panjabi | 11 | Russian | 2 | Somali | 1 |
Polish | 11 | Thai | 2 | Tagalog | 1 |
Portuguese | 11 | Vietnamese | 2 | Xhosa | 1 |
Tamil | 11 | Yoruba | 2 | Zhuang | 1 |
German | 10 | 合計 | 1613 |
•
英語のデータが最も多く、出力形式が韓国語のデータセットは全部で7個
•
出力だけが韓国語であるデータはすべて翻訳されたデータであり、入出力ともに韓国語であるデータはPawsx(https://github.com/google-research-datasets/paws/tree/master/pawsx) 1つだけである。 Pawsxデータセットは、フランス語、スペイン語、ドイツ語、中国語、日本語、韓国語などタイプが区別される6つの言語を人間が翻訳したPAWS評価ペア23,659個と機械翻訳されたトレーニングペア296,406個が含まれている。翻訳はPAWS-Wikiで確認可能。
Name | Summary | Category | Domain | Input Language | Output Language |
task771_pawsx_korean_text_modification | Given a sentence in Korean, provide an equivalent paraphrase in said language | Paraphrasing | Wikipedia | Korean | Korean |
task777_pawsx_english_korean_translation | Given a sentence in English, provide an equivalent translation to Korean | Translation | Wikipedia | English | Korean |
task790_pawsx_french_korean_translation | Given a sentence in French, provide an equivalent translation to Korean | Translation | Wikipedia | French | Korean |
task796_pawsx_spanish_korean_translation | Given a sentence in Spanish, provide an equivalent translation to Korean | Translation | Wikipedia | Spanish | Korean |
task802_pawsx_german_korean_translation | Given a sentence in German, provide an equivalent translation to Korean | Translation | Wikipedia | German | Korean |
task808_pawsx_chinese_korean_translation | Given a sentence in Chinese, provide an equivalent translation to Korean | Translation | Wikipedia | Chinese | Korean |
task814_pawsx_japanese_korean_translation | Given a sentence in Japanese, provide an equivalent translation to Korean | Translation | Wikipedia | Japanese | Korean |
•
具体的な例は以下の通りで、ラベル0と1は文の関係が同じ(1で表示)と異なる(0で表示)を意味します。
id | sentence1 | sentence2 | label |
10 | 2005년과 2009년 사이 그가 스웨덴 Carlstad United BK, 세르비아 FK Borac Čačak, 러시아 FC Terek Grozny에서 뛰었던 것은 제외됩니다. | 2005년 후반에서 2009년 사이 그가 스웨덴 Carlstad United BK, 세르비아 FK Borac Čačak, 러시아 FC Terek Grozny에서 뛰었던 기간은 제외입니다. | 1 |
12 | 타바시 강은 루마니아 류드라 강의 지류이다. | Leurda강은 루마니아에 있는 Tabaci강의 지류입니다. | 0- |
•
特徴的なのは、固有表現に該当する人名や会社名などはすべて翻訳せずにそのままにしていること。また、ソースデータとして全てWikipediaを使用した特徴がある。
参考
• Yizhong Wang, Swaroop Mishra, Pegah Alipoormolabashi, Yeganeh Kordi, Amirreza Mirzaei, Atharva Naik, Arjun Ashok, Arut Selvan Dhanasekaran, Anjana Arunkumar, David Stap, Eshaan Pathak, Giannis Karamanolakis, Haizhi Lai, Ishan Purohit, Ishani Mondal, Jacob Anderson, Kirby Kuznia, Krima Doshi, Kuntal Kumar Pal, et al.. 2022. Super-NaturalInstructions: Generalization via Declarative Instructions on 1600+ NLP Tasks. In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, pages 5085–5109, Abu Dhabi, United Arab Emirates. Association for Computational Linguistics.
•
関連GitHubリンク
•
Yinfei Yang, Yuan Zhang, Chris Tar, and Jason Baldridge. 2019. PAWS-X: A Cross-lingual Adversarial Dataset for Paraphrase Identification. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pages 3687–3692, Hong Kong, China. Association for Computational Linguistics.
•
データ分析に使用したソースデータ
•
ソースデータ整理