
導入
•
チャットボット、要約、機械翻訳など多くの自然言語生成AIの開発において、正確な評価(evaluation)は非常に重要であるが、苦痛なプロセスである。
•
LLMはpromptingだけで様々な問題解決で良い性能を示しており、最近の論文ではGPT-4を通じてevaluationを自動的に行うなど、人の判断が必要な領域で活用する事例が徐々に増えている。
•
この記事では、LLMを活用して事実検証(fact verification)を行い、自ら誤った情報を修正して幻覚(hallucination)を抑制する内容の論文について紹介する。
•
レビュー論文
◦
https://arxiv.org/abs/2309.11495 (by Meta AI)

概要
•
質問に対してすぐに答えを生成するのではなく、LLMが自ら推論の流れを生成させると性能がより高くなるという現象は、いくつかの論文で観察(Chain of Thought)
•
この論文では、回答ドラフトを生成した後、自ら回答の信頼性を検証できる質問を生成して確認した後、最終回答を生成するChain-of-Verification(CoVe)方法を提案します。
•
List-based questionとlong-form text generation問題でhallucinationが減少し、パフォーマンスがより向上する結果を観察。
方法論
•
以下の手順でユーザーの質問に対する回答を生成する。
•
回答ドラフトを作成
◦
与えられた質問に対してLLMから回答を生成
◦
プロンプトの例

•
Verification questionを生成
◦
質問と生成した回答を見て確認が必要な内容に対するverification questionを生成します。
◦
プロンプトの例

•
各verification questionに対する回答を生成する。
•
生成したverification質問に対して回答を生成する方式は大きく4つに分けられる(joint, 2-step, factored, factor+revise)。
◦
Joint : verification 質問の生成と回答を一つのプロンプトで同時に行う。
◦
2-step : verification 質問の生成と回答を分離して行う。
生成した質問だけを集めてLLMから回答を生成する。
◦
Factored : verification 質問に対する回答を生成する時、質問一つずつ別々にLLMを呼び出して生成する。
◦
Factor+Revise : 最初の回答とverification結果が互いに一致するかどうかを別のPromptを通じて明示的に確認する過程を追加。
•
プロンプトの例


•
上記の内容を総合して最終回答を生成
◦
プロンプトの例

結果
•
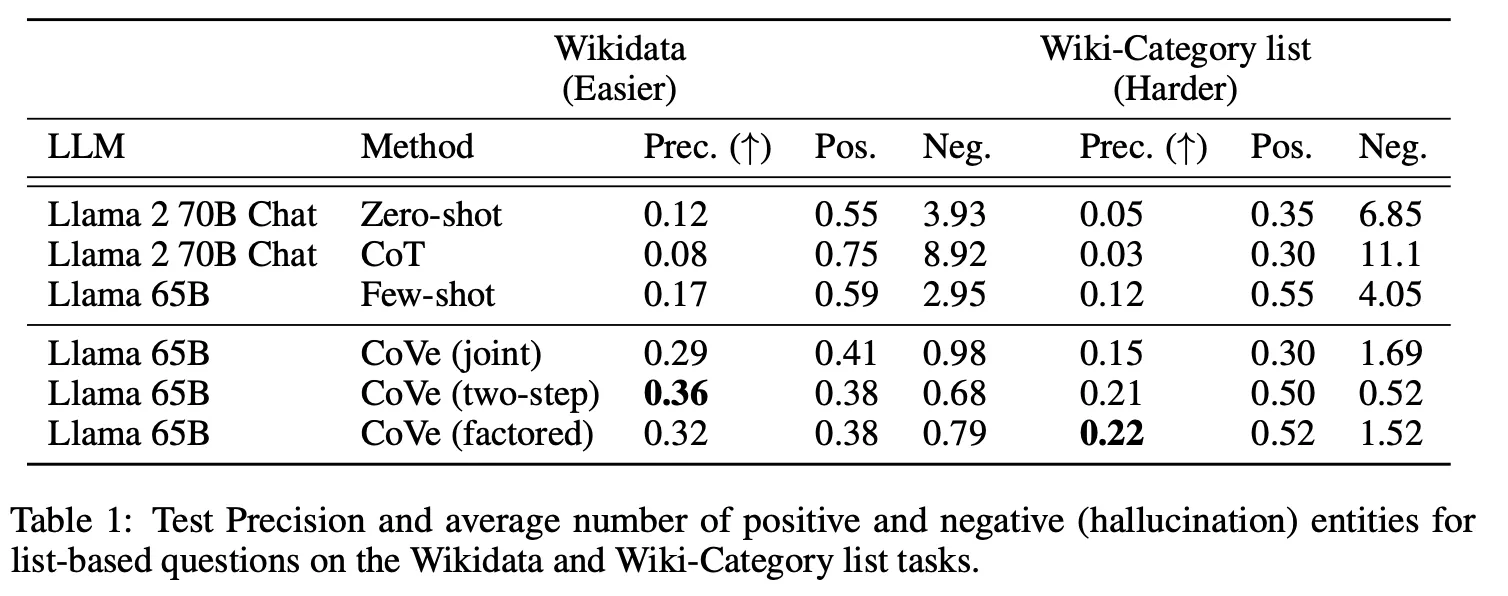
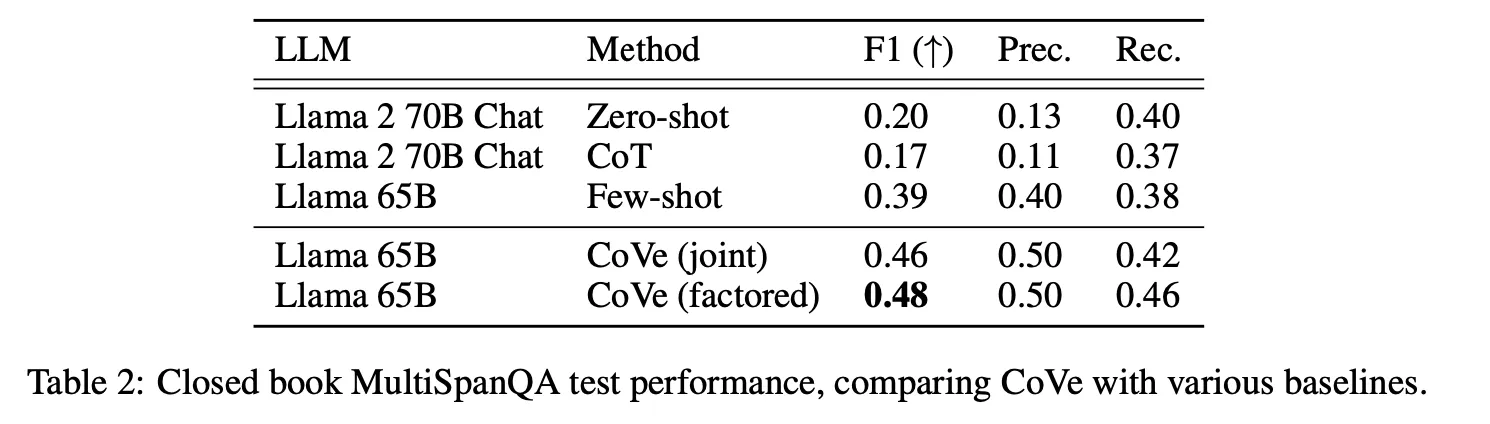
Few-shot に比べて list-based tasks (Wikidata, Wiki-Category) および Closed-book QA(MultiSpanQA) で大幅な性能向上が観測された。
•
当該タスクでCoTが zero-shotより全て性能が落ちる部分は疑問。
•
Jointの場合、最初にLLMが生成した回答に誤った情報がある場合、verification過程でnoiseとして作用する可能性があるため、一般的に2-stepやfactoredより性能が劣る。
議論事項
•
Zero-shot/few-shot promptを通じてLLMが事実を検証し、判断できるということを示したという点で意義がある。
•
提案した方法は、LLMが持つfact verification能力で推論の精度を高めるもので、広く見ればCoTの変形とも考えられる。
◦
つまり、与えられた問題状況により適したreasoning chainを細かく設計して効果を高める。
•
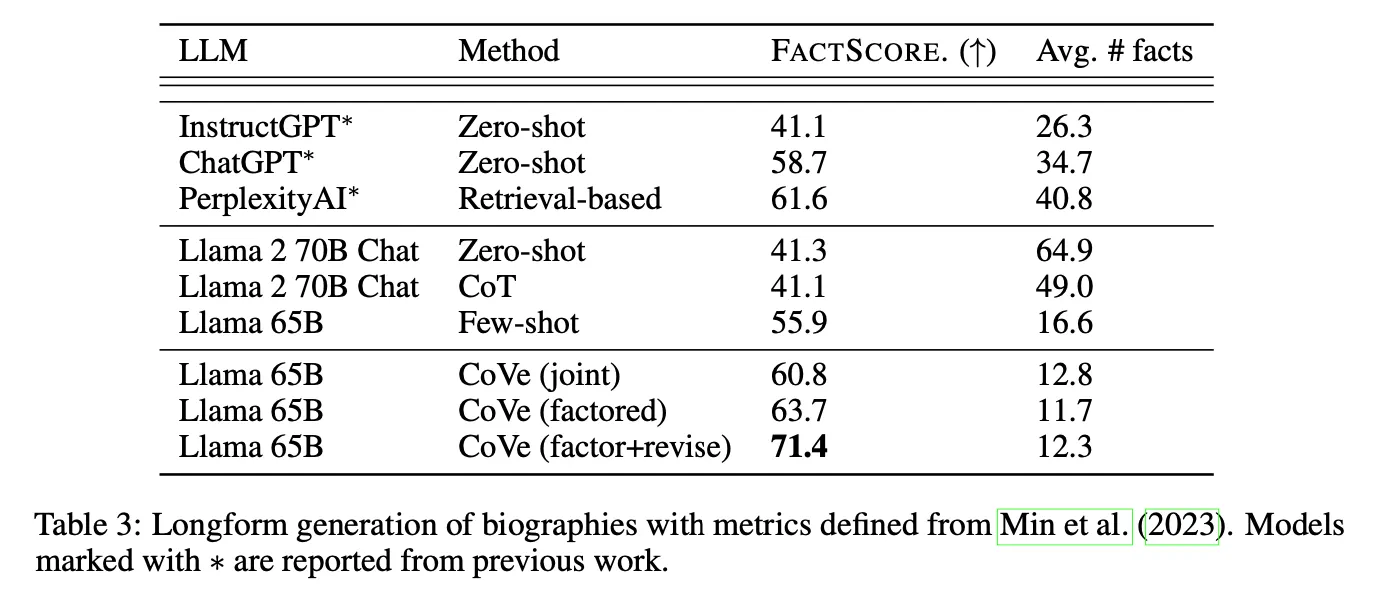
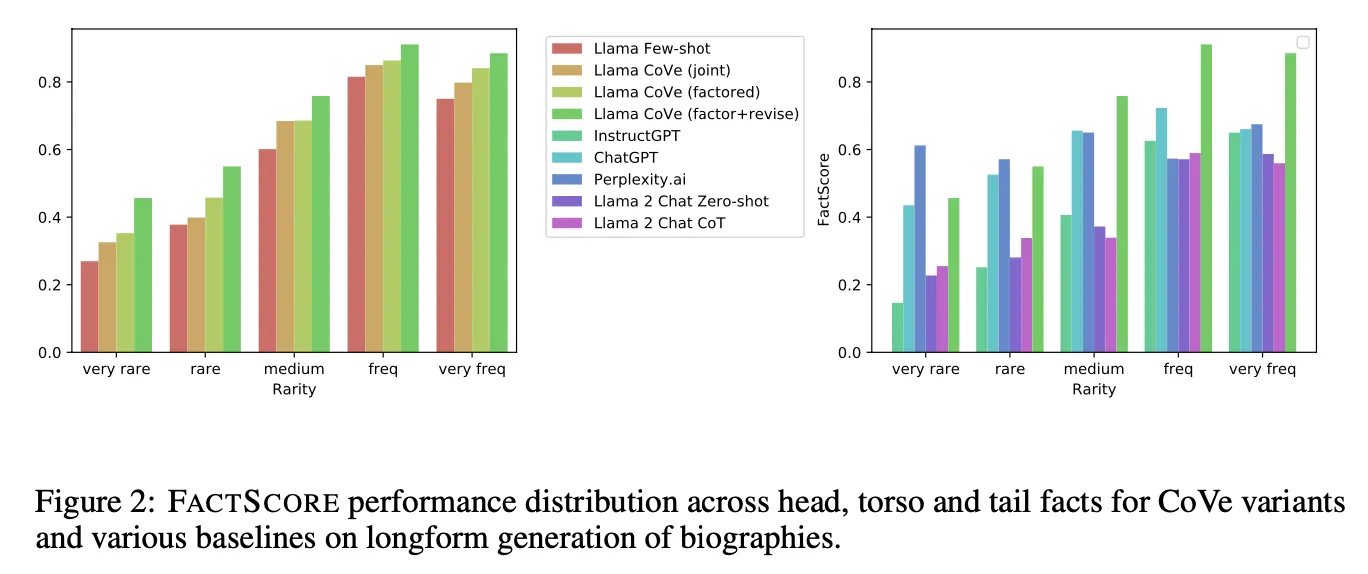
同じバックボーンではないのでfairな比較ではありませんが、外部知識を活用せず、LLMが持つ知識と能力だけで外部知識を参照するretrieval-basedのPerplexityAIよりもより高い性能を示す点は印象的である。しかし、rare factの場合にはPerplexity AIがより高い性能を示す。
•
この現象は、広く知られている知識関連taskはすでにLLMが十分に学習しているので、CoVe手法でそれを適切に活用するだけで良い性能を出せるからだと判断。 しかし、比較的あまり知られていない知識ほどretrievalを通じて外部知識を適切に注入してあげることが絶対的に重要であることが分かる。