

導入
•
LLMはzero/few-shot promptingだけでも多くのtaskで優れた性能を発揮するが、回答結果は入力されたpromptの内容によって大きく影響を受ける
•
しかし、taskに合わせて人が直接最適なpromptを作ることは非常に難しく、時間とコストがかかる作業であり、また、promptがどれだけうまく動作するかを事前に確認することは容易ではない
•
この記事では、上記の問題に対する解決策の一つとして、LLMを活用して最適なプロンプトを自動的に生成する最新の研究と関連するreferenceについて紹介する
•
レビューした論文
◦
Automatic Prompt Engineer (APE) : https://arxiv.org/abs/2211.01910 (by Univ. of Toronto, Vector Institute, Univ. of Waterloo)
◦
◦
◦

(画像出典) プレゼンテーションの「Designer」機能を使用して画像を自動生成します。
概要
•
Promptを自動的に生成するためには下記のような問題が存在する
◦
Instruction Generation : 与えられたtaskに合わせてinstructionを自動的に生成
◦
Instruction Ranking : いかに良いプロンプトなのかパフォーマンスを予測
•
要約
Stage | Features | APE | iPrompt | Auto Instruct | BPO |
Instruction Generation | バックボーンモデル | InstructGPTバックボーンモデル | GPT-J | ChatGPT
GPT-4 | llama2-7b-chat |
方式 | prompting | prompting | prompting | tuning | |
詳細 | 3つの固定meta promptで複数個生成
| 学習データを入力として複数個生成
| 7つの固定meta promptで各3個ずつ合計21個生成
| simple promptを入力としてoptimized promptを生成するように学習
| |
Instruction Ranking | バックボーンモデル | InstructGPT | GPT-J
GPT-3 | FLAN-T5-Large | なし |
方式 | prompting | prompting | tuning | ||
詳細 | 生成したプロンプトを入力としてLLM結果を予測します。
(accuracy & log prob.ベース)
| 生成したプロンプトを入力としてLLM結果を予測します。
| LLM生成結果と正解間のスコアの分布とrankerの'yes'tokenの確率分布を一致させるように学習
|
方法論の詳細
•
APE
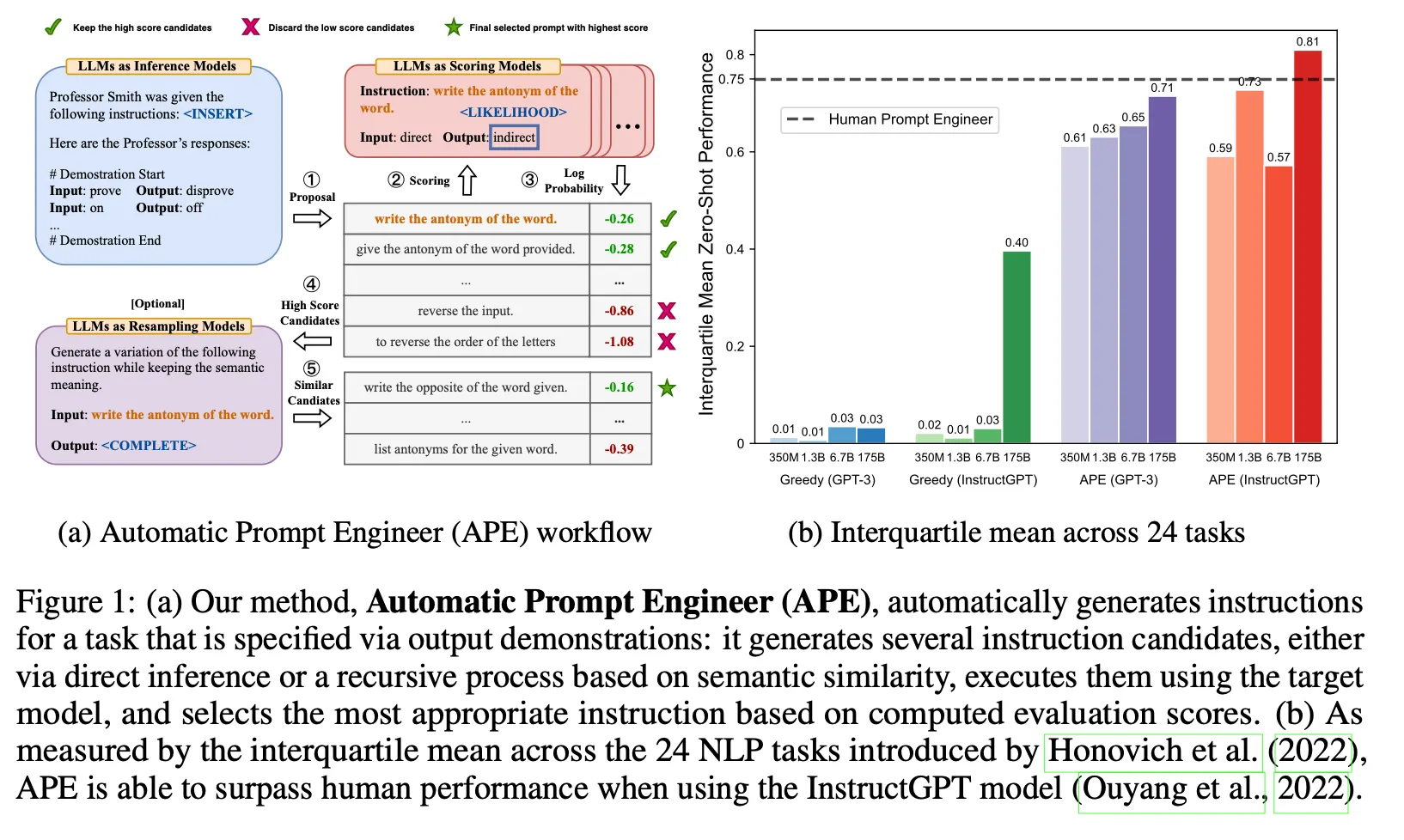
◦
3種類のmeta prompt (forward mode, reverse mode, customized prompt)に学習データ(input, output)を入れてm個のinstructionを生成

◦
生成したinstructionにtrainingデータセットからrandom samplingしたexamplesを入れて答えを予測。予測した結果と実際の正解を比較し、instructionに対するスコアを測定します。
▪
execution accuracy : 各exampleに対して正解かどうかを0-1 lossで評価
▪
log probability : 正解textに対するLLMのlog probability値をスコアとして使用
◦
測定したスコアに基づいてtop k instructionを選択する
◦
(Optional) top k instructionと同様の意味を持つ変形instructionをLLMを通じて追加生成し、評価対象のinstruction setに追加
◦
上記の過程を繰り返す

◦
アルゴリズム

•
iPrompt
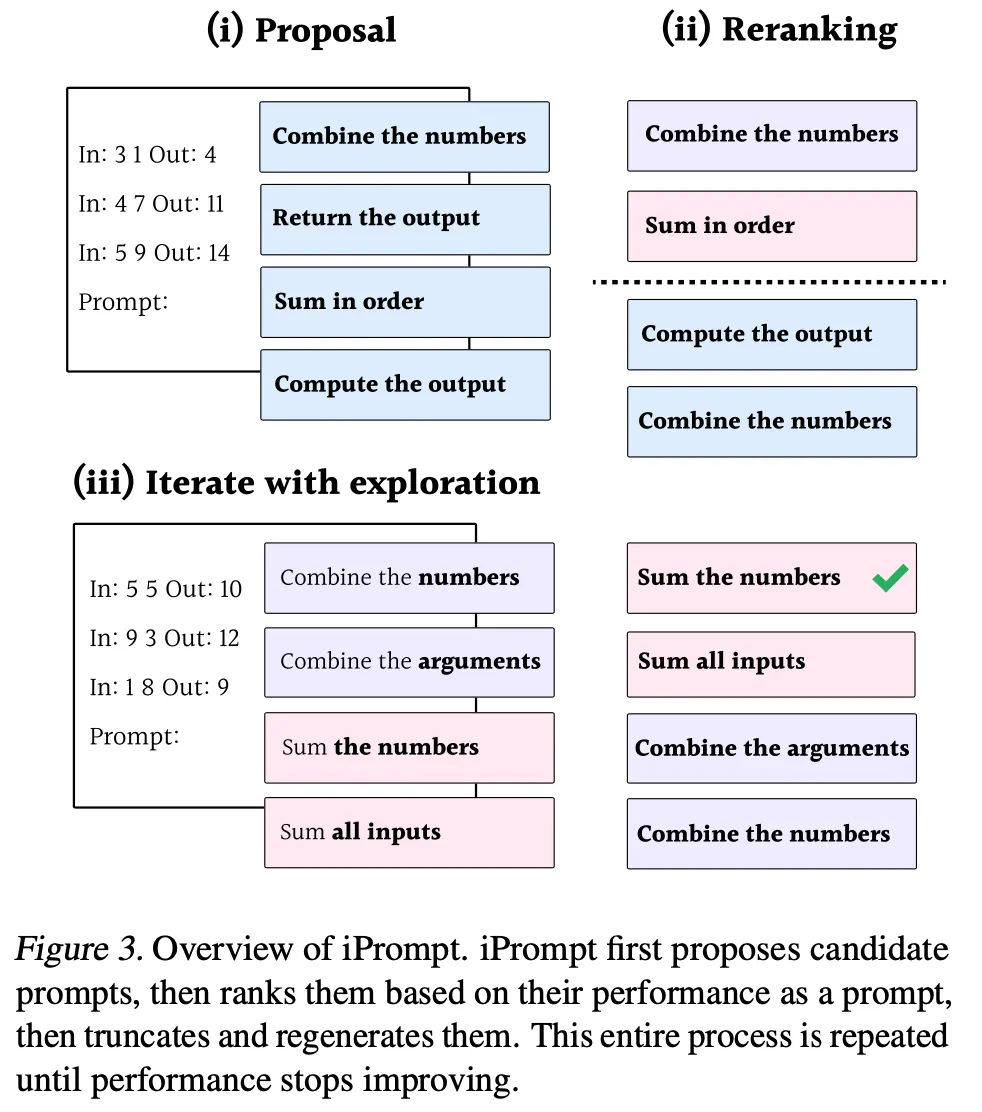
◦
学習データ(input, output)だけを使ってzero-shotでcandidate promptsを生成
▪
instruction生成用のmeta promptについて詳しい言及がない
▪
簡単なinstructionと例題データ程度の基本的な形になると予想
◦
生成したinstructionにtrainingデータセットからrandom samplingした例を入れ、LLMで回答を生成。正解textに対するlog probabilityをスコアとして使用。
◦
測定したスコアに基づいて top k instructionを選択
◦
選択されたinstructionから任意の位置を基準に後ろを切り取った後、その部分をLLMで再作成して新しいprompt候補を作る。上記の過程を繰り返す
•
オートインストラクト
◦
次の3つのステップで構成されています。
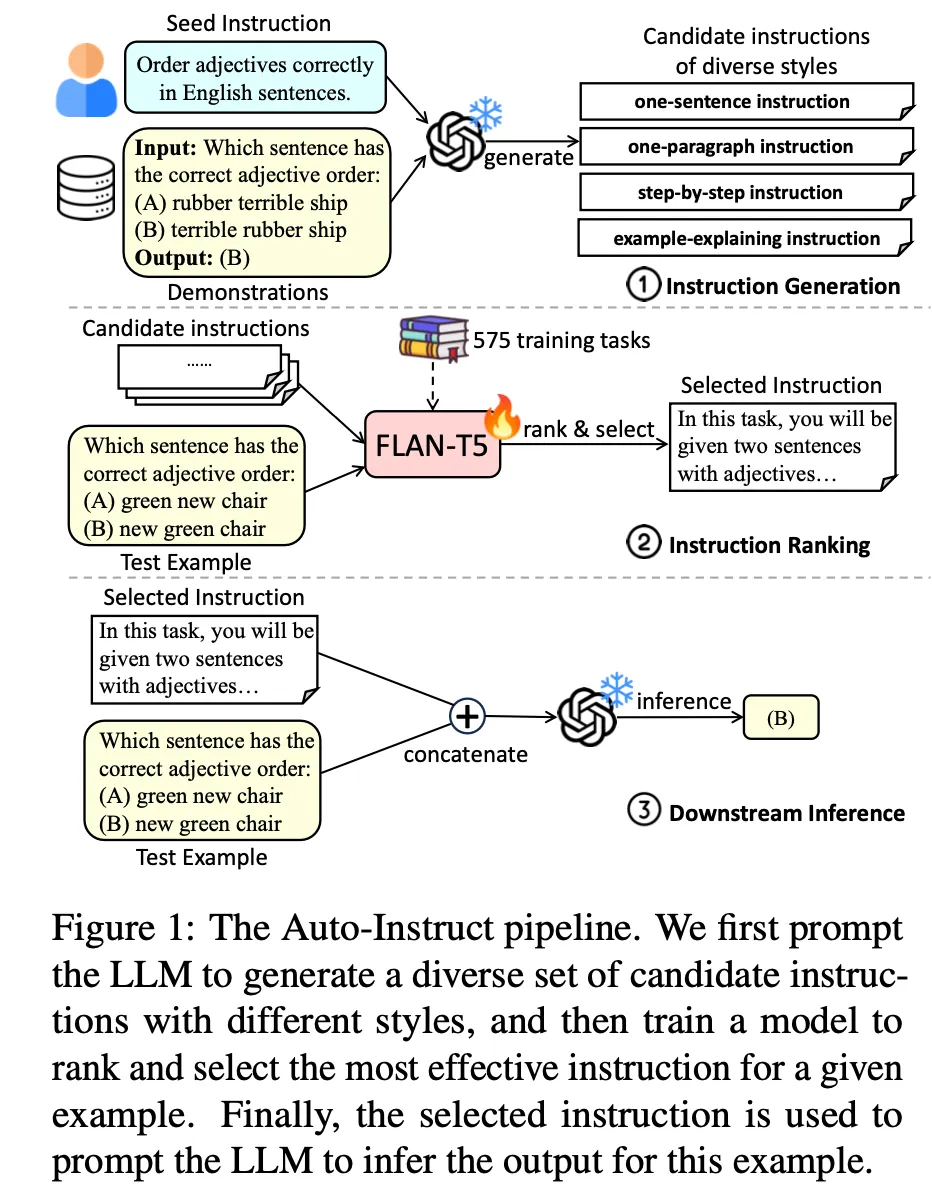
•
Instructionの生成
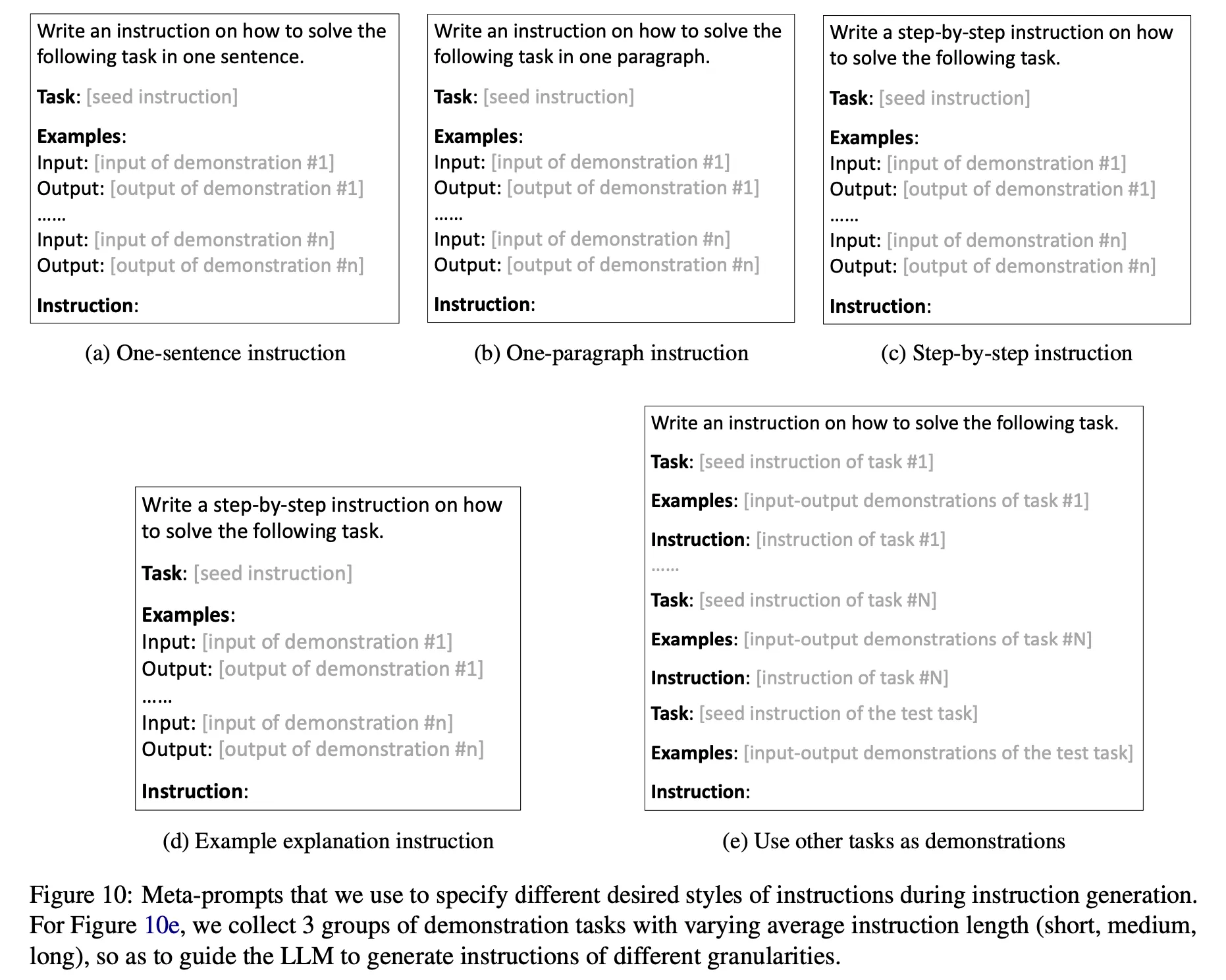
◦
Instructionを生成するmeta promptを7つの異なる形式で構成し、それぞれ3つずつ生成(合計21個)
▪
次のように4つの異なるstyleで生成するように明示的に指示(上の図で(a)-(d)) : 'one sentence', 'one paragraph', 'step-by-step', 'explanations of the given examples' (例の図で(d)のinstructionが間違っている。'explanations of ...' に変えるべき)
▪
基本instruction(上の図の(e))に3種類の異なる例を入れて生成 : ここで例に入るデータはSuperNIから抽出。SuperNIデータをinstructionの長さを基準に3つのグループにclusteringした後、同じclusterのデータでmeta promptを生成。
•
Instruction ranking&選択
◦
FLAN-T5-Largeモデルをチューニングして使用
◦
SuperNIデータセットから英語データのみを抽出した後、task type(e.g., QA, sentimental analysis, etc.)に応じて分類
◦
Input に対して評価しようとする instruction で以下のようにプロンプトを構成して ranking model に入力する。この時、モデルで生成する 'yes' トークンのlogit値が instruction のスコアになるように学習
◦
このため、正解と入力したinstructionで生成した回答間のROUGE-Lスコア(下式で )の分布(softmax over all candidates)と'yes'トークンの確率分布を最大限一致するように学習する(二つの分布間のKL divergenceを最小化)
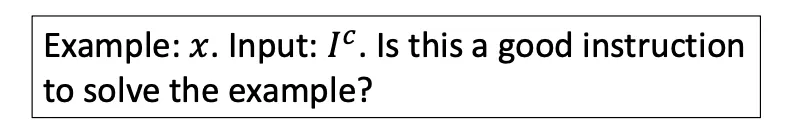
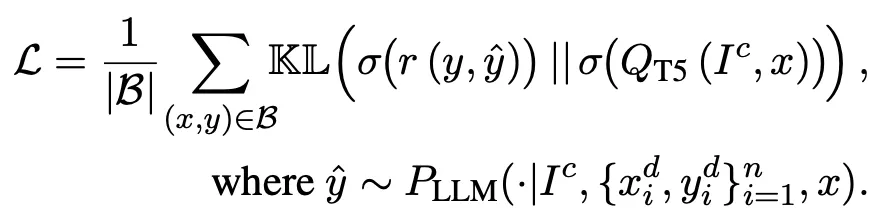
◦
使用したtask種類 : 575(train), 91(test)
◦
一つのtaskごとにそれぞれ最大400個までの例をsampling --> 合計122k構築
•
選択したinstructionで最終結果を生成
•
BPO
◦
学習データセット構築
▪
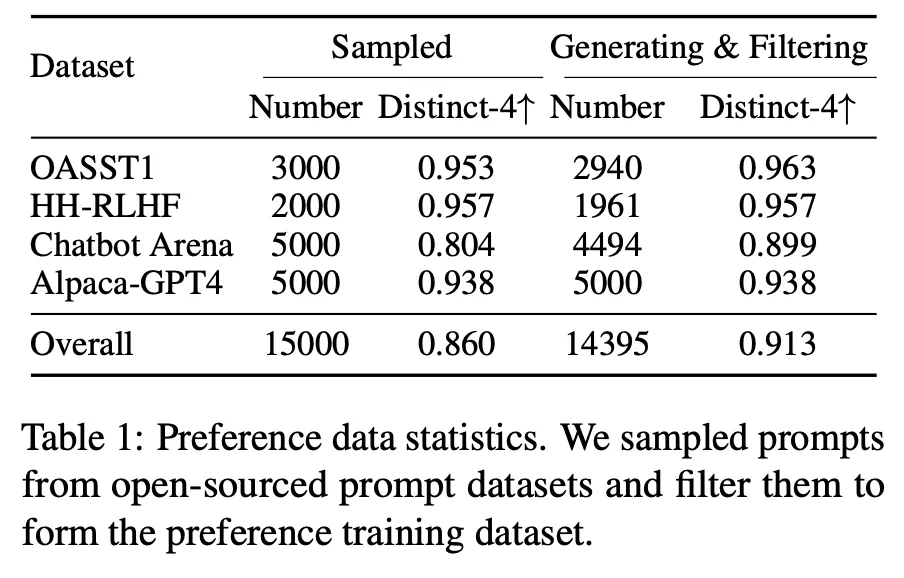
4つのデータセット(OASST1, HH-RLHF, Chatbot Arena, Alpaca-GPT4)から(user input, good response, bad response)tripletを抽出
▪
抽出した情報をもとに以下のプロンプトを構成し、ChatGPTを通じてより良いinstructionを生成。合計14,395 pairs

◦
Prompt生成モデルの学習
▪
(user input, optimized input)のpairデータを活用して下記のobjective functionでPLMをチューニングし、最適化されたinstructionを生成できるモデルを学習。 論文ではllama2-7b-chatモデルをバックボーンモデルとして使用した。
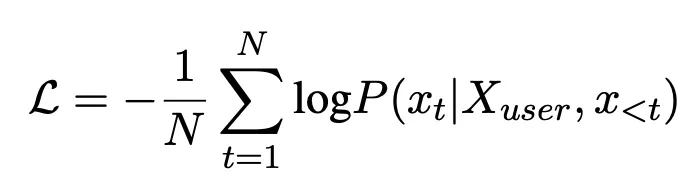
結果
•
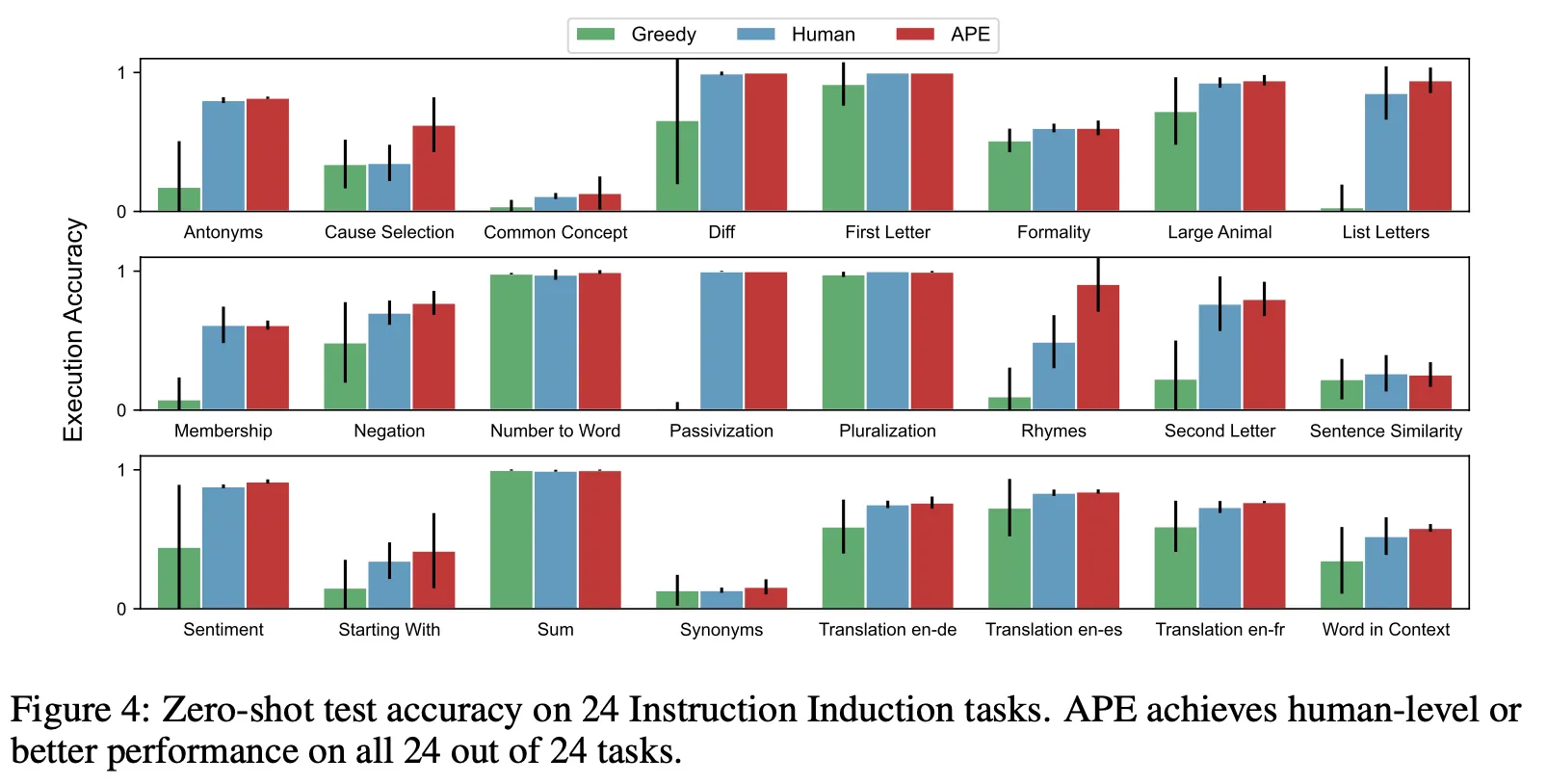
APE
◦
Instruction Induction tasks, BIG-Bench実験
◦
Greedy promptおよびhuman promptと比較してパフォーマンスの向上が観察されました。
•
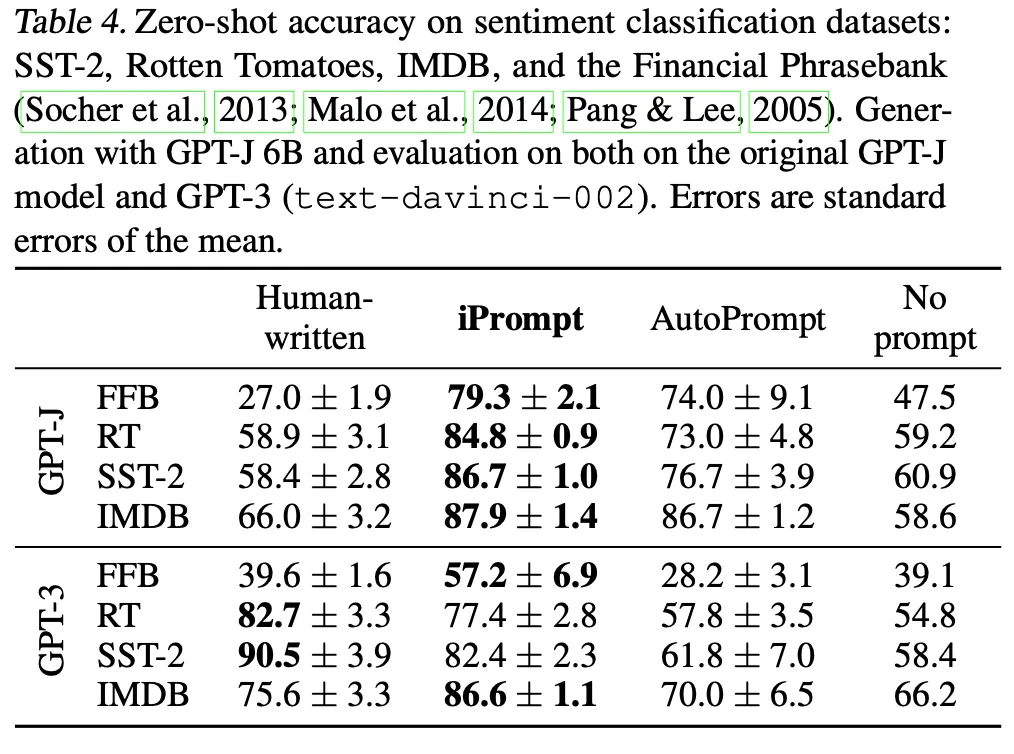
iPrompt
◦
FFB, Rotten Tomatoes, SST-2, IMDB実験
▪
Human promptおよび比較対象であるAutoPromptと比較してパフォーマンスの向上を観察
•
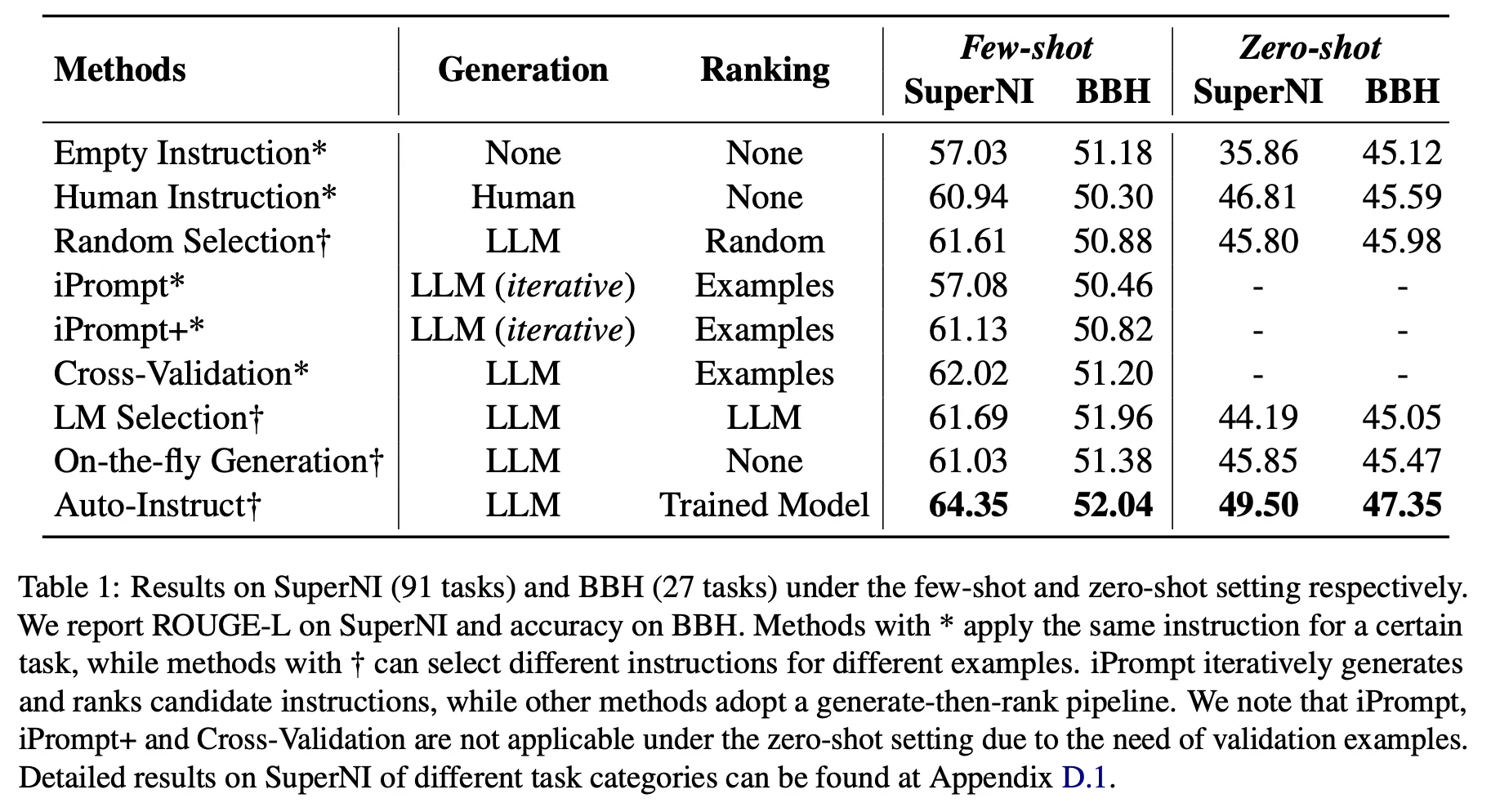
Auto Instruct
◦
LLM이 좋은 instruction을 생성할 능력을 가지고 있음. 그렇지만 적절한 ranking은 필수
▪
아래 표에서 empty instruction, human instruction, on-the-fly generation 비교
▪
LLM이 생성하는 방법론들이 human instruction 및 empty instruction 점수를 넘는 경우가 존재
▪
그렇지만 잘못 선택할 경우 성능이 더 낮아지기도 함
◦
Instruction의 품질을 판단하기에 제안한 ranking model이 가장 효과적
▪
Random Selection, iPrompt, iPrompt+, Cross-Validation, LM Selection, Auto-Instruct 비교
▪
생성한 instruction을 LLM을 통해 판단하거나 validation data를 활용하여 선택하는 것(iPrompt, cross-validation)은 오히려 random selection보다 더 낮은 성능을 보이기도 하는 등 reliable하지 않음
▪
반면 제안한 방법은 모든 경우에서 가장 좋은 성능을 달성
•
Auto Instruct
◦
LLMが良いinstructionを生成する能力を持っている。しかし、適切なrankingは必須。
▪
以下の表でempty instruction, human instruction, on-the-fly generationを比較
▪
LLMが生成する方法論がhuman instructionとempty instructionのスコアを超える場合が存在する。
▪
しかし、間違った選択をすると性能がさらに低下することもある。
◦
Instructionの品質を判断するには、提案したranking modelが最も効果的です。
▪
Random Selection, iPrompt, iPrompt+, Cross-Validation, LM Selection, Auto-Instruct比較
▪
生成したinstructionをLLMを通じて判断したり、validation dataを活用して選択すること(iPrompt、cross-validation)は、むしろrandom selectionより低い性能を示すこともあるなど、reliableでない。
▪
一方、提案した方法はすべてのケースで最高の性能を達成します。
•
BPO
◦
実験した公開LLM APIで全て改善効果があった。
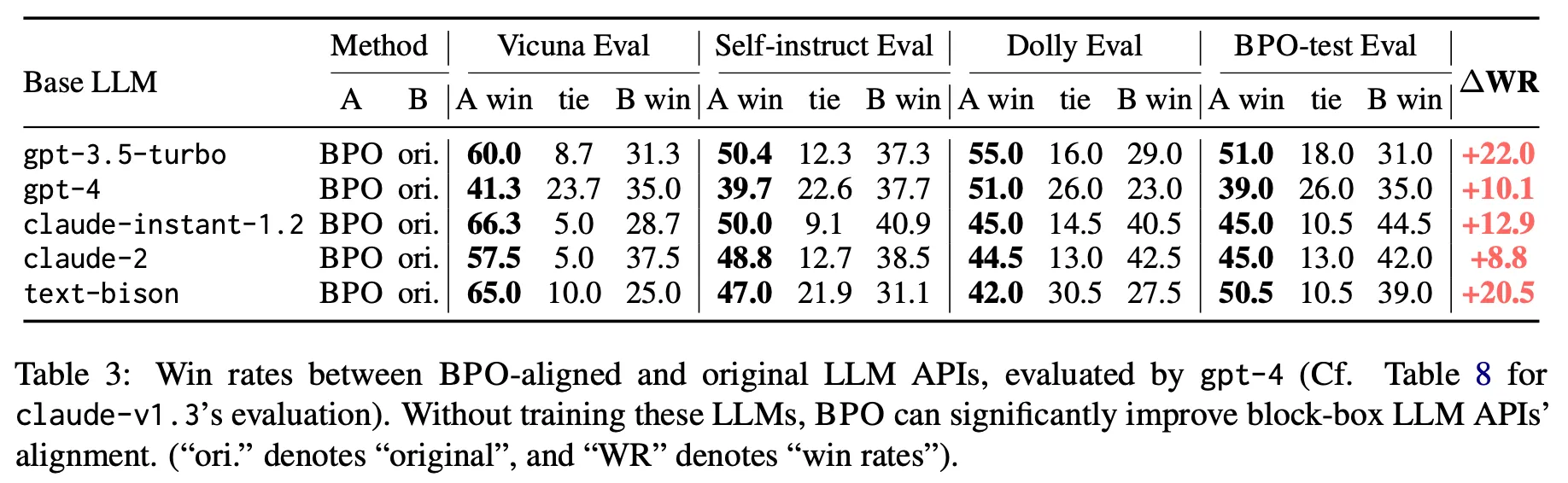
◦
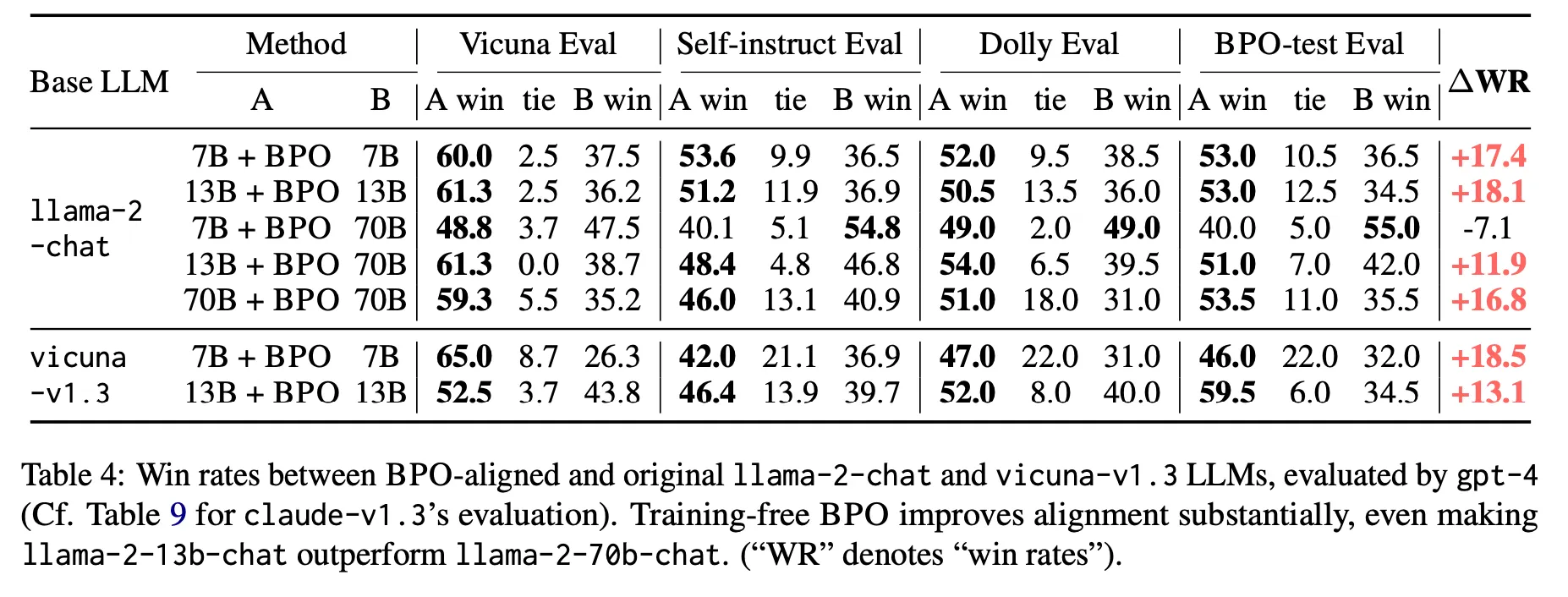
LLaMA 2とVicunaの両方で改善効果がある。特に、13B+BPOが70B originalより全てのケースで性能が良いという点は注目すべきである。つまり、Promptの最適化を通じて期待できる改善幅がかなり大きいことが分かる。
◦
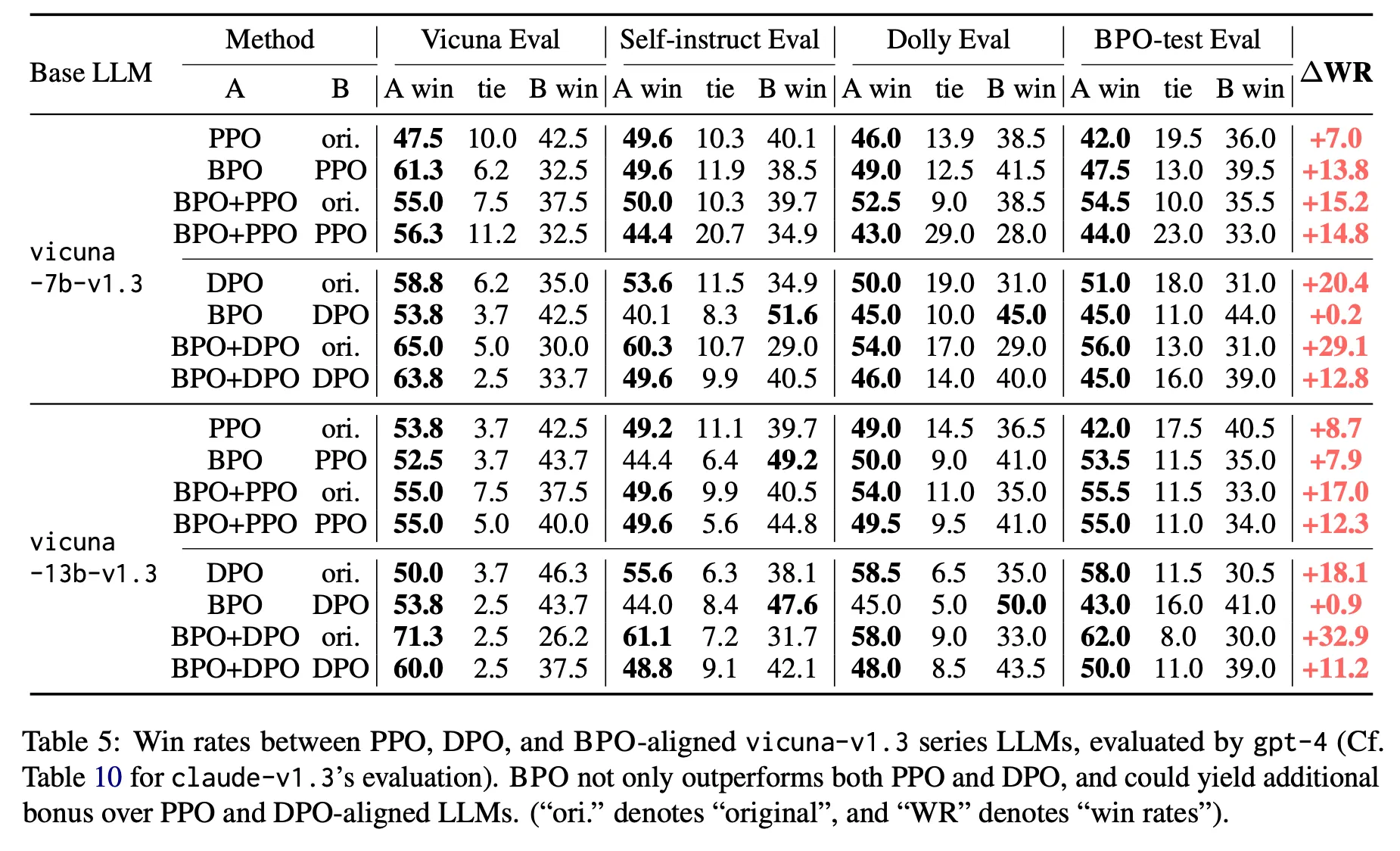
PPOやDPOなどと比較した場合よりも優れた性能を示し、これと組み合わせるとさらに改善される。
議論事項
•
実際、特定のtaskでうまく動作するプロンプトを作るのは非常に難しい問題であり、上記の方法論はtaskに合う最適なプロンプトを自動で生成することが目的である
•
APE&iPrompt
◦
似たような時期に公開されたほぼ同じアプローチ。新しいプロンプト候補の生成方法に若干の違いがある。
◦
特別なチューニング過程なく、プロンプト生成と性能予測ともにLLMのICL能力を活用する簡単な方法。
◦
ただ、Auto Instructで指摘したように単純なmeta promptで複数のinstructionを生成する時、多様性が落ちる可能性がある問題はある。
◦
また、iPromptの場合、初期論文であることを考慮しても、prompt生成にGPT-Jを使った部分は残念。
◦
LLMによるprompt自動生成の初期研究として、LLMを通じて少なくとも適度なレベルのhuman promptあるいはそれ以上の性能を得ることができることを示したことに意義がある。
•
Auto Instruct
◦
与えられたtaskに対してどのinstructionが効果的かを判断するinstruction rankingモデルを提案し、有効性を実証したことが最も印象的
◦
ただ、このモデルが一般化できるかどうかが注目ポイント。もし他の言語とunseen taskに対して一般化されるとしたら非常に有用だと判断
•
BPO
◦
Task descriptionレベルの簡単なinputを最適なpromptで自動的に生成するモデルがkey contributionと判断
◦
特に13B+BPOで70Bの性能を超えた点、BPOがPPOに比べて性能が良い点などが印象的
◦
ただし、別途のinstruction ranking段階なしにChatGPTが生成したinstructionをほぼ無条件にoptimized promptとみなすようだが、このプロセスがどれだけreliableかは疑問