

Paper Review
Search

概要
•
不快な言語表現だけでなく、微妙に有害な非暴力的、非倫理的な出力まで検証できるデータセットを制作及び公開。
•
有害な出力を削減するための攻撃データセットの構築。
◦
拒否(Reject)する会話タイプが含まれている。
•
詳細なデータ構築方法論(instruction、生成手順など)を公開。
•
3つのサイズ(パラメータ2.7B、13B、52B)のモデルと合計4つのモデルタイプについて、scaling behaviorを調べて検証を行う。
◦
基本モデル (plain LM)
◦
Rejection sampling(RS) 適用モデル(LM with RS; RSはモデルが合計16個の答えを生成させた後、別のLMがこの答えに対する有害度を判断させ、最も危険度の低い2つの答えを出力する方式)。
◦
プロンプトを出したモデル (LM prompted to be helpful, honest, and harmless)
◦
人のフィードバックを活用して強化学習したモデル(RLHF)
◦
RLHFモデルはサイズが大きくなるにつれて徐々に防御が良くなる一方、他のモデルタイプはサイズによって比較的ほぼ同じようなレベルを示した。

AIの有害な出力を減らすためのレッド チーミング言語モデル(Red Teaming Language Models to reduce harms)
非暴力的、非倫理的な出力を検証できるデータセット
宋永淑 ソン・ヨンソク/ ML Researcher
harm
Generation
害
導入
•
•
この記事では、アルゴリズム問題だけでなく、様々な自然言語タスクでLLMが持つ優れたコード生成能力を適切に活用できる方法論を提示した「chain of code」という論文を紹介する。
•

概要
•
一行要約 : LLMにcode-driven reasoningをさせたら効果が良い。
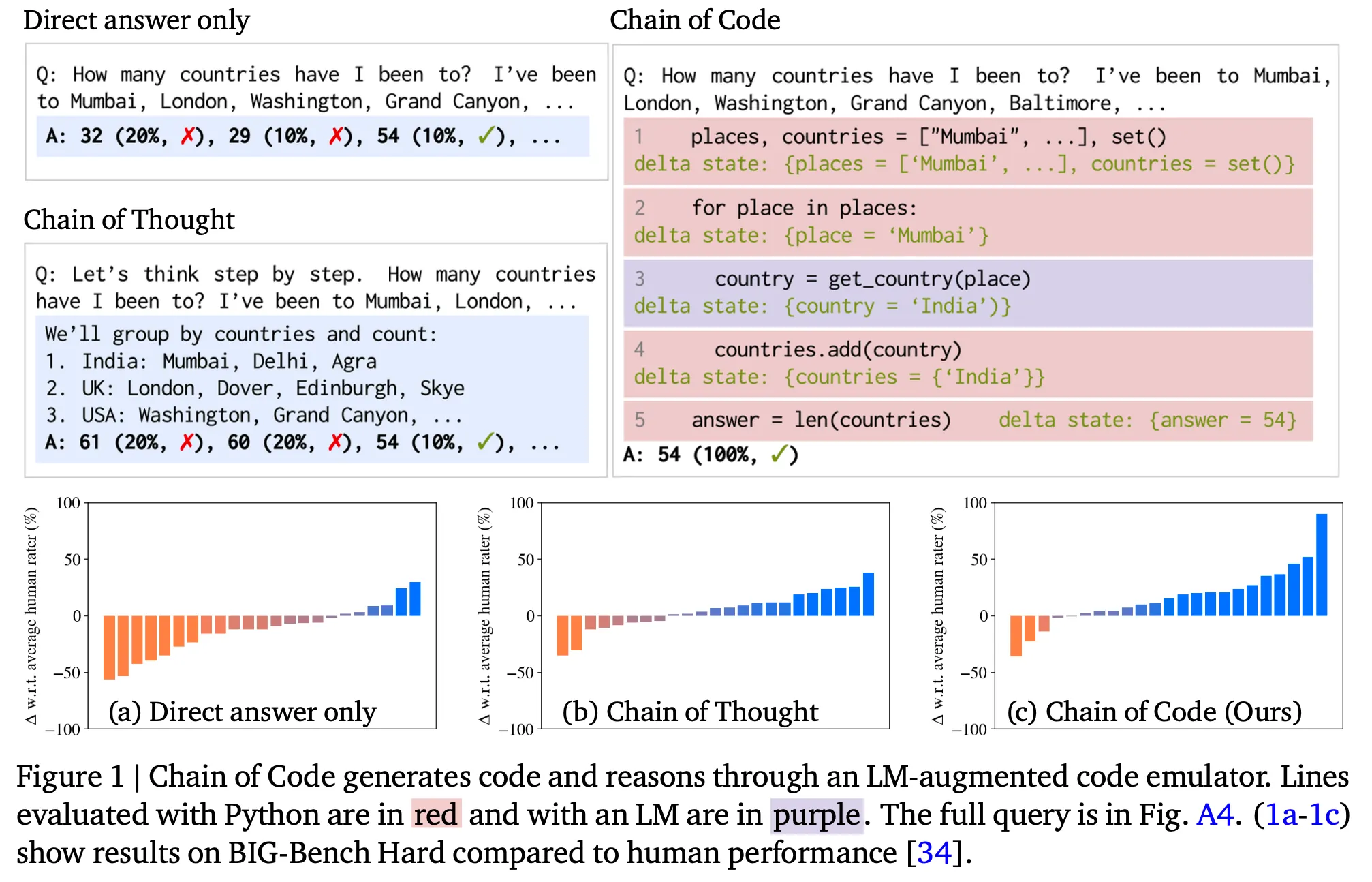
Codeを通じてLLMの推論能力を高めることができるのか?
コードを通じた巨大言語モデルの推論能力向上
朴宇明 パク ウミョン / CDO & Head of Research
Prompting
Tuning
この記事の前半ではSuper-NaturalInstructions(SuperNI)論文を概観した後、後半ではSuperNIに含まれるデータセットのうち、韓国語であったり、興味深いテーマを含んでいるデータセットを紹介します。

論文紹介
概要
•
SuperNIはAllen Institute for AI、University of Washington、Arizona State Universityをはじめとする合計21機関所属の研究者が参加し、1600余りのNLP instructionデータを作成し、公開したプロジェクトです。
◦
•
https://arxiv.org/abs/2104.08773で61個のタスクに関するデータを公開することからスタート。
[論文レビュー]Super-NaturalInstructions
Super-Natural Instructions(SuperNI)論文・データセットの紹介
朴宇明 / CDO & Head of Research, 宋永淑 / ML Researcher
Instruction
LLM
dataset
Super-NaturalInstructions
導入
•
LLMはzero/few-shot promptingだけでも多くのtaskで優れた性能を発揮するが、回答結果は入力されたpromptの内容によって大きく影響を受ける
•
しかし、taskに合わせて人が直接最適なpromptを作ることは非常に難しく、時間とコストがかかる作業であり、また、promptがどれだけうまく動作するかを事前に確認することは容易ではない
•
この記事では、上記の問題に対する解決策の一つとして、LLMを活用して最適なプロンプトを自動的に生成する最新の研究と関連するreferenceについて紹介する
•
レビューした論文
◦
Automatic Prompt Engineer (APE) : https://arxiv.org/abs/2211.01910 (by Univ. of Toronto, Vector Institute, Univ. of Waterloo)
◦
◦
◦

(画像出典) プレゼンテーションの「Designer」機能を使用して画像を自動生成します。
自動的に最適なPromptを生成する方法
最適なプロンプト方法論の紹介。
朴宇明 / CDO & Head of Research
Prompting
AutoPrompt
導入
•
LLMは単純なプロンプトだけで多くの課題で優れた能力を発揮するが、完璧ではない。
•
その中でも代表的な問題としては、事実でない内容を事実であるかのように生成するハルシネーション問題、そして社会的に問題の余地がある危険な発言を生成する問題などがある。
•
この記事では、biasが存在する、または問題となる内容をLLMが自ら判断し、抑制することに関する論文について紹介する。
•
参考までに、このようなLLMの「self-correction」あるいは「self-refinement」の問題についてもっと詳しく知りたい場合は、このsurvey論文(Pan et al. (2023)および関連referenceを参考
•
レビュー論文
◦
https://arxiv.org/abs/2309.07124 (北京大学、マイクロソフトリサーチ、シドニー大学、ウォータールー大学)

概要
•
LLMが生成した文章をユーザーが望むように'align'させるために、既存の多くの研究ではpreference datasetを構築し、reward modelを学習した後、このスコアに基づいてLLMをRL(e.g., PPO)でチューニングする方法を多く使用。
•
実際のOpenAIのモデル (InstructGPT、ChatGPT、GPT-4など) をはじめ、Google、Meta、Anthropicなどほぼ全てのところでこの方法でチューニングをしてLLMを開発した。
•
しかし、reward modelを学習するためのデータセット制作は非常に時間と費用がかかり、構築難易度が高く、開発が難しい。
•
ここでは、明示的な reward model なしで zero-shot/few-shot prompting を通じて効果的にharmlessnessを高める (つまり、有害なコンテンツ生成を抑制する) 結果を示している。
LLMは自ら回答の危険性を判断できるのか?
超巨大言語モデルの回答の危険性を判断するに関連する論文の紹介
朴宇明 / CDO & Head of Research
Prompting
Alignment
LLM
導入
•
チャットボット、要約、機械翻訳など多くの自然言語生成AIの開発において、正確な評価(evaluation)は非常に重要であるが、苦痛なプロセスである。
•
LLMはpromptingだけで様々な問題解決で良い性能を示しており、最近の論文ではGPT-4を通じてevaluationを自動的に行うなど、人の判断が必要な領域で活用する事例が徐々に増えている。
•
この記事では、LLMを活用して事実検証(fact verification)を行い、自ら誤った情報を修正して幻覚(hallucination)を抑制する内容の論文について紹介する。
•
レビュー論文
◦
https://arxiv.org/abs/2309.11495 (by Meta AI)

概要
プロンプティングで事実確認(Fact Verification)
超巨大言語モデルの発話が事実かどうかを確認する方法論に関連する論文の紹介
朴宇明 / CDO & Head of Research, 김덕현 / Head of Development
Prompting
Fact Verification
導入
•
Promptingは人間が大規模言語モデル(LLM)を制御し、コミュニケーションする手段であると言える。
•
別途パラメータを更新することなく、プロンプトだけ入力する in-context learning(ICL) 方式により、LLMが様々な問題で優れた性能を発揮している。
•
この記事では、複雑な推論(reasoning)問題において、最新の方法論である diversity of thought に関連する主な reference について紹介する。

プロンプティングを通じたLLMの推論能力向上
超巨大言語モデルの推論能力向上のためのプロンプトの方法論
朴宇明 / CDO & Head of Research
Prompting
Tuning
導入
•
Promptingは人間が大規模言語モデル(LLM)を制御し、コミュニケーションする手段である。
•
ユーザーは、欲しい結果を得るために、どうすればうまくPromptingを作成できるかという一般的な方法論に対するニーズは今後も増えると思われる。
•
最近、生成だけでなく、自然言語理解(文の分類、シーケンスラベル付け、質疑応答)課題でプロンプトチューニングがファインチューニングよりも性能が良くなったというレポート(Lifu Tu et al. (2022)やCOT(Jason Wei et al. (2022)などのプロンプト方法論、そしてマルチモーダルでの応用(Andy Zeng et al. (2022)などが発表され始めている。
•
この記事では、プロンプティングを通じてzero-shotのパフォーマンスを向上させる興味深い2つの論文を紹介する。

•
レビュー論文
概要
•
COSP : Consistency-based Self-adaptive Prompting
•
USP : Universal Self-adaptive Prompting
•
Unlabeled dataとblack-box LLMを通じてzero-shot in-context learning(ICL)の性能を向上させることを目的とした異なる2つの方法論
効果的なプロンプティング(Prompting)方法論の紹介
効果的なプロンプティング(Prompting)方法論の紹介
朴宇明 / CDO & Head of Research
Prompting
Tuning
MTEB(Massive Text Embedding Benchmark)
MTEBとは
•
様々な埋め込み作業でテキスト埋め込みモデルの性能を測定するために作成した大規模なベンチマークです。
•
2023年10月10日現在のデータセット、言語、スコア、モデルの数
•
総データセット数: 129
•
総言語数113
MTEB上位の方法論
MTEBの上位方法論の紹介
朴宇明 / CDO & Head of Research
MTEB
Embedding
Benchmark

はじめに
•
推論とは、すでに知られている事実をもとに新たな判断や結論を導き出すことである。推論は知的活動をする上に不可欠な能力である。
•
したがって、LLMがどのような推論能力を示すかは、人々がAIが本当に「知能」を持っているかを体感する重要な要素といえる。
•
Scratchpads, Chain of Thoughtsなどをはじめ、LLMが持つ推論能力を最大限に引き出すための研究が継続的に行われている。
•
この記事では、推論をより効率的に行うために2段階に分けてアプローチしたSelf-Discoverという方法を紹介する。
•
概要
LLMの推論能力を高める : Self Discover
解法を先に設計した後、実際の問題を解く2段階方式で推論能力を向上させます。
박우명 / CDO & Head of Research
LLM
超巨大言語モデル
Reasoning

導入
LLMは、複雑な推論能力を必要になるタスクや、様々な文脈を理解して処理しなければならない困難なタスクでも非常に優秀な性能を見せている。
最近、モデルが生成した回答を自ら評価し、エラーを修正することで性能を向上させることで、hallucinationを減らす「self-correction方法論」の研究が活発に行われている。
この記事では、self-correctionのプロセスを2段階に細分化し、最新のLLMが各段階でどのような面を見せるかについて実験を行う。
概要
一行要約 : 現在のLLMは、推論過程の中で正確にどこで論理的なエラーが発生したかを見つける能力は劣るが、適度なレベルのフィードバックを受ければ答えを修正する能力はある。
LLMは自分でエラーを検出し、修正できるのか?
超巨大言語モデルがエラーを検出し、回答を修正できるかどうかについての実験
박우명 / CDO & Head of Researcher
LLM
Self Correction