

導入
•
Promptingは人間が大規模言語モデル(LLM)を制御し、コミュニケーションする手段であると言える。
•
別途パラメータを更新することなく、プロンプトだけ入力する in-context learning(ICL) 方式により、LLMが様々な問題で優れた性能を発揮している。
•
この記事では、複雑な推論(reasoning)問題において、最新の方法論である diversity of thought に関連する主な reference について紹介する。

•
レビュー論文
◦
◦
◦
◦
概要
•
一般的な Prompting はディレクティブと例文 (zero-shotの場合はディレクティブのみ)で構成され、最終結果をすぐに生成させる方式です。
•
ここで紹介する論文が提案する方法は大きく2つに分けられる。
◦
解決過程をLLMが自ら作成:Scratchpads, CoT
◦
LLMに何度も問題を解かせた後、Ensemble : SC, DoT
•
これは、例えば人が数学の問題を解くときに、解く過程を書き留めて、何度も検算するのと同じような感覚で解釈できる。
方法論
•
Method 1:解答プロセスをLLMが自ら作成する
◦
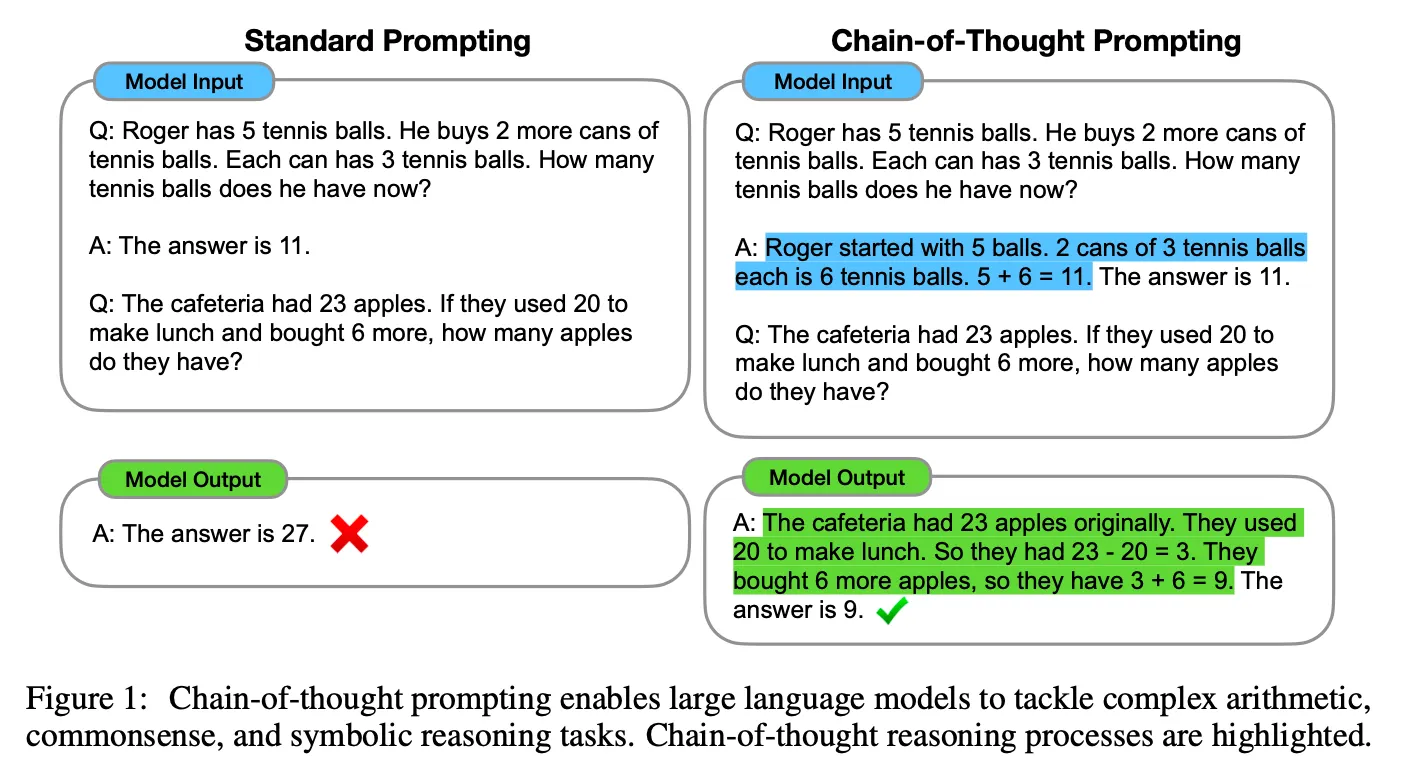
ScratchpadsとCoTともに解答過程をモデルが自ら生成する点は同じだが、CoTがより自然言語形式で生成するという点で違いがある。

Scratchpads
Chain-of-Thought
◦
Scratchpadsが先に登場したが、CoT方式が自然言語形態で生成してLLM能力をleverageするのにより効果的であり、より多くのタスクに適用できる一般的な方法論であるため、CoTがさらに注目されたと考えられる。
•
Method 2 : LLMに問題を複数回解かせた後、生成結果をensemble
◦
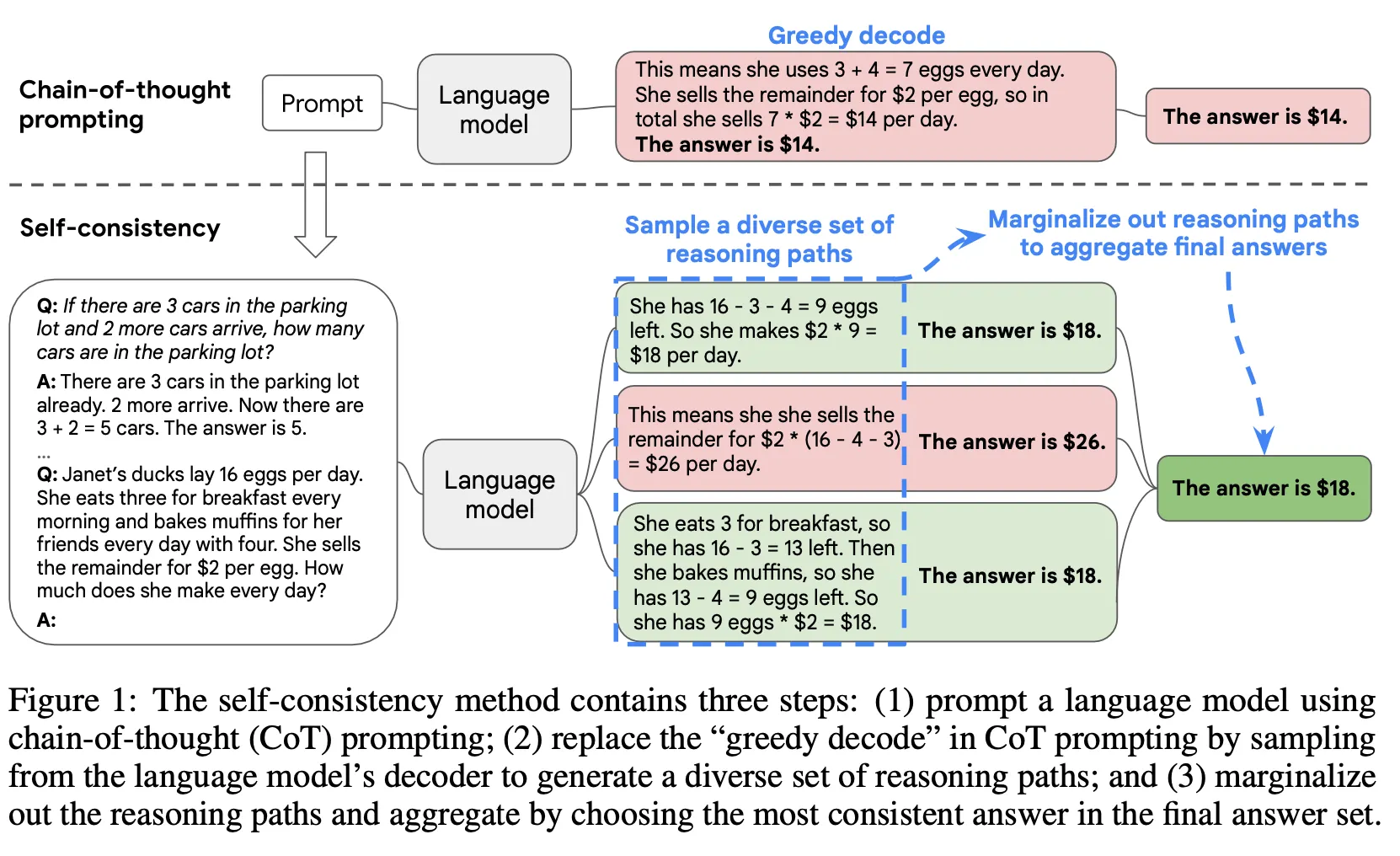
SC
▪
CoT PromptingをLLMに入力して様々な種類の結果を生成する。
▪
生成した結果に対してmajority voteを適用し、最も多くの回答を最終回答として決定する。
▪
様々な種類のdecoder sampling方法(e.g., temperature, top-k, top-p, nucleus samplingなど)適用可能。
▪
◦
DoT
▪
一つの質問に対して異なるアプローチで解く過程を生成し、結果を導き出した後、ensembleする方法。
▪
与えられた質問に対して、あるアプローチで答えを求めるかをディレクティブに入力。上記の例では"Using direct calculation", "Using algebra", "Using visualization" 3つのアプローチで生成している。
▪
2つの方法論を提案
•
DIV-SE(DIVerse reasoning path Self-Ensemble) : 1つのプロンプトは1つの方法だけを生成させた後、n回呼び出して生成する方法
•
IDIV-SE(In-call DIV-SE) : 上の図の例のように、一つのプロンプトにnつの方法に対する答えを同時に生成する方法

結果
•
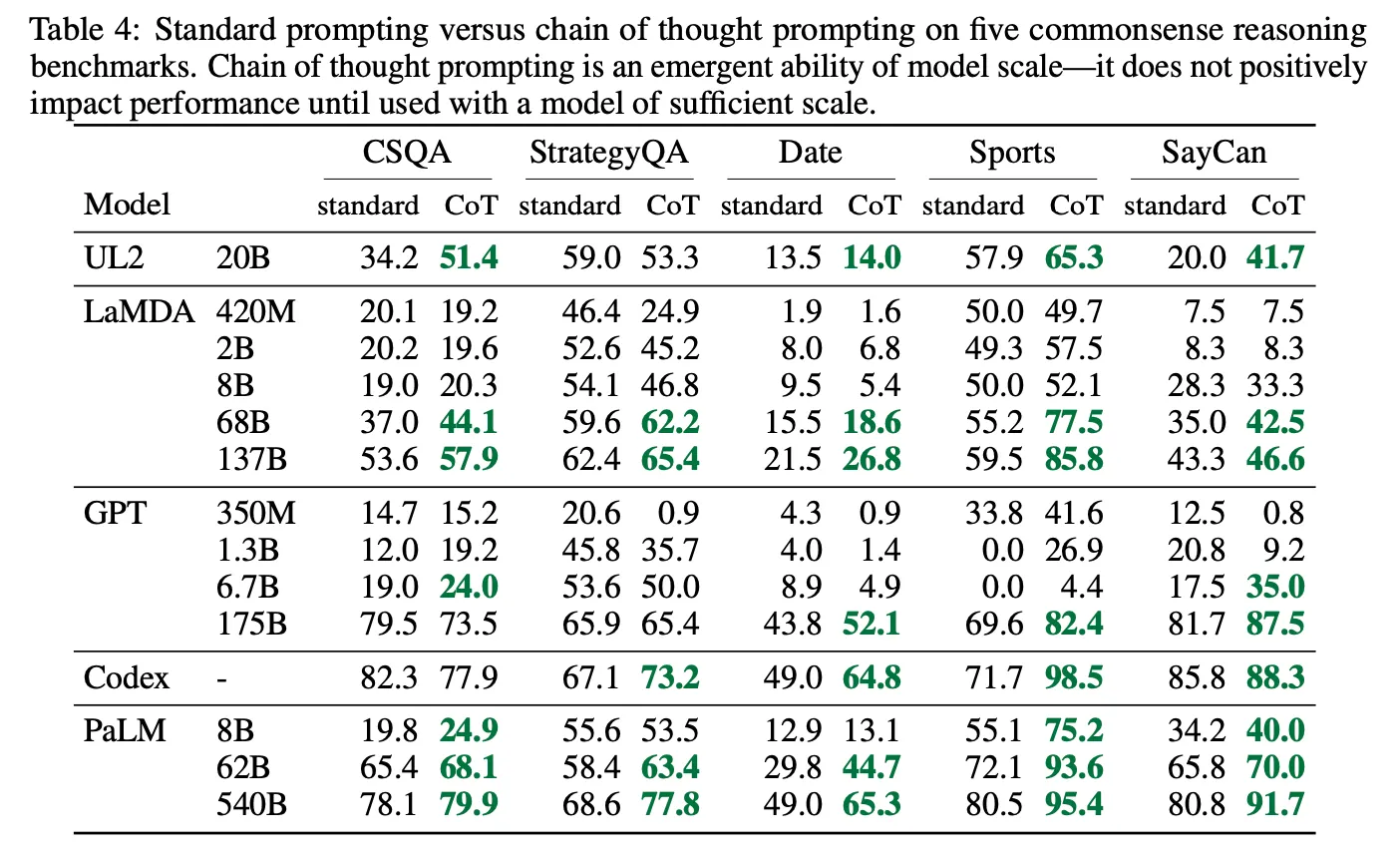
Standard Prompting vs CoT
◦
LLMのサイズが小さい場合、むしろ性能低下が存在するが、モデルが大きい場合(60B以上)、比較的大きな幅の性能向上が存在(emergent ability)
◦
小さなLLMの場合、誤った解き過程を生成し、それがノイズになることが多くて、性能がむしろ低下したように見える。
◦
上記の現象は、LLMの絶対的なサイズよりもLLMが持つ能力に大きな影響を受ける。 つまり、sLLMでも最近登場するはるかに優れたモデルの場合は効果がある(例えば、20BサイズのChatGPT)。
◦
様々な種類のtaskで効果がある
•
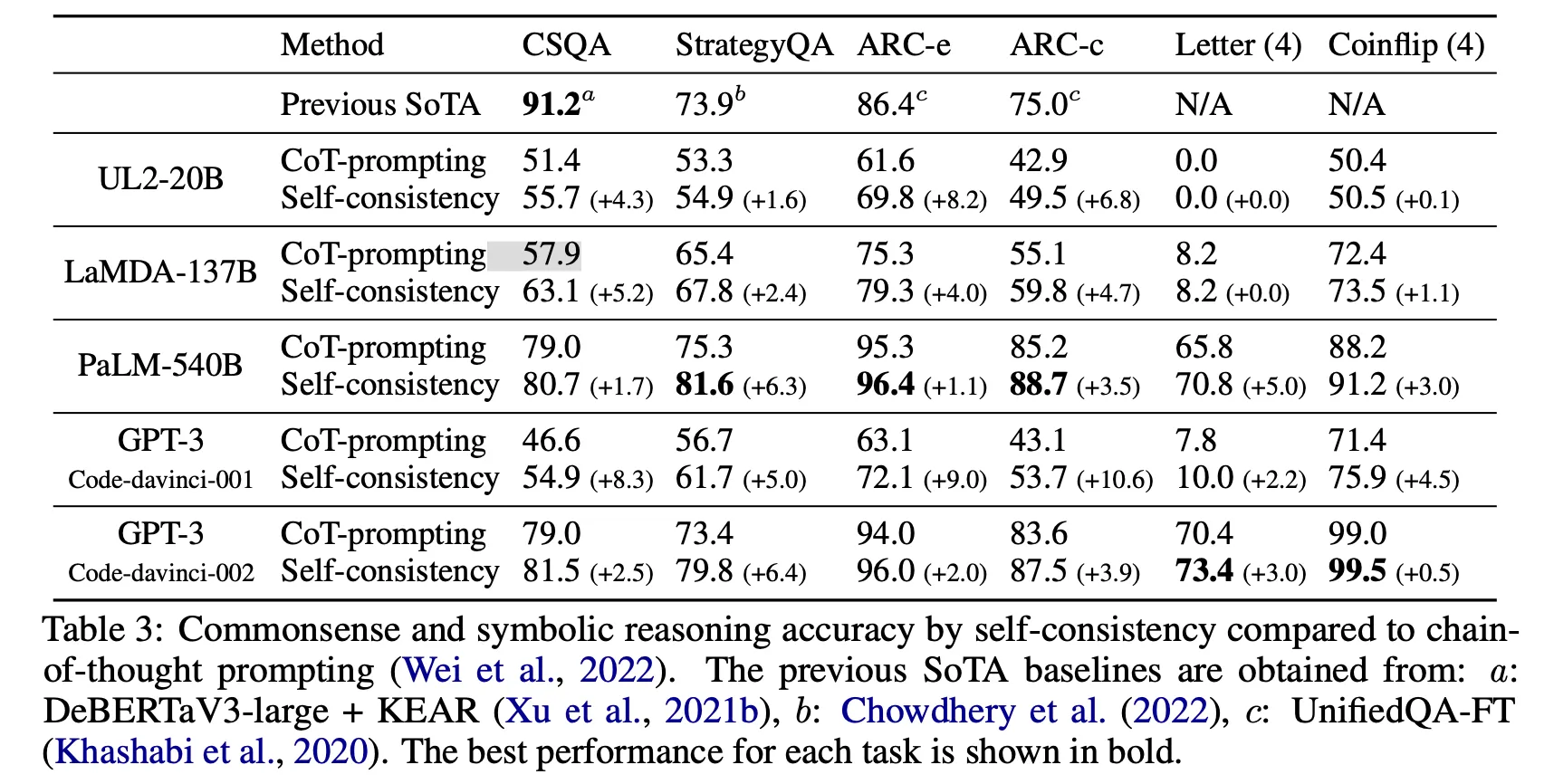
CoT vs SC
◦
スコア上昇幅の差は存在するが、single inferenceに比べほぼ全てのLLM、全てのtaskで効果がある。
◦
ただし、サンプリングする回数だけLLMを呼び出す必要があるため、比例して推論コストが発生します。
•
SC vs DoT
◦
より良いcost-performance tradeoffを提供
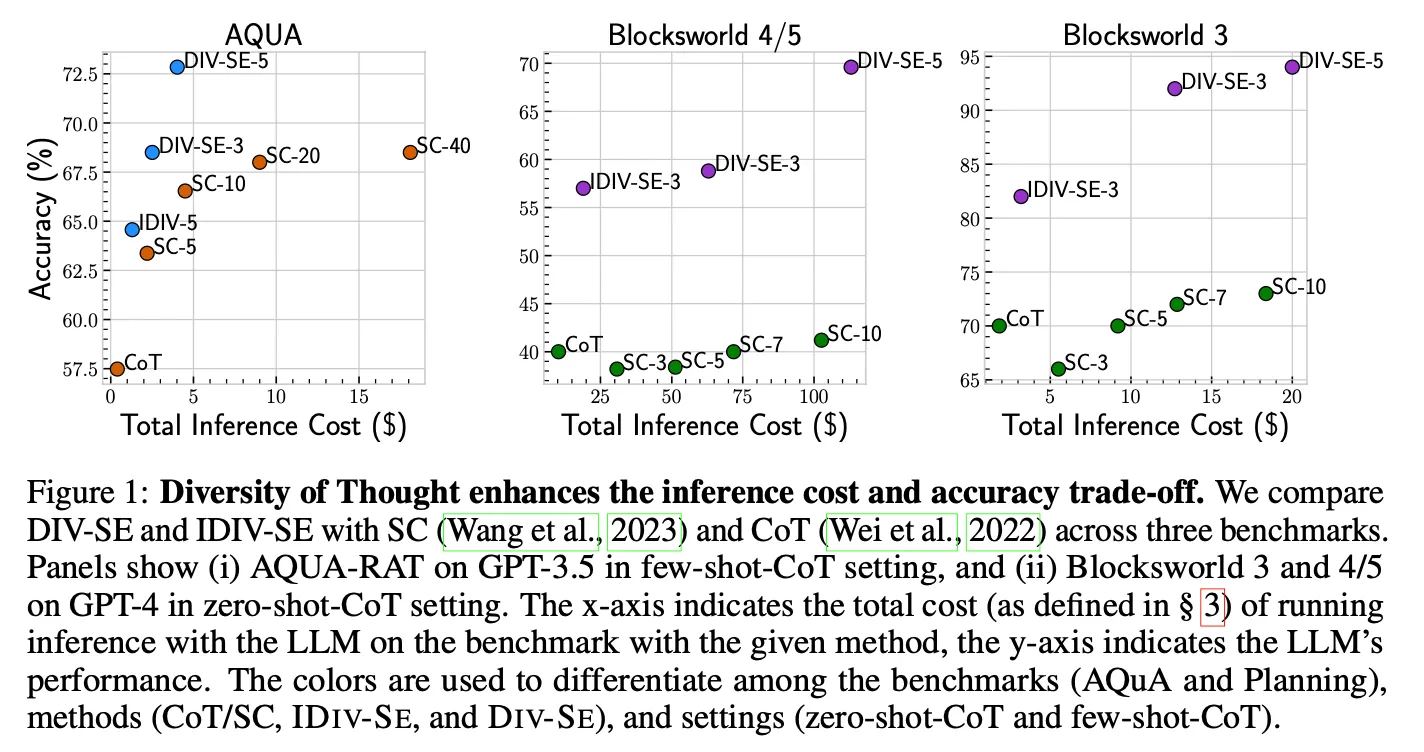
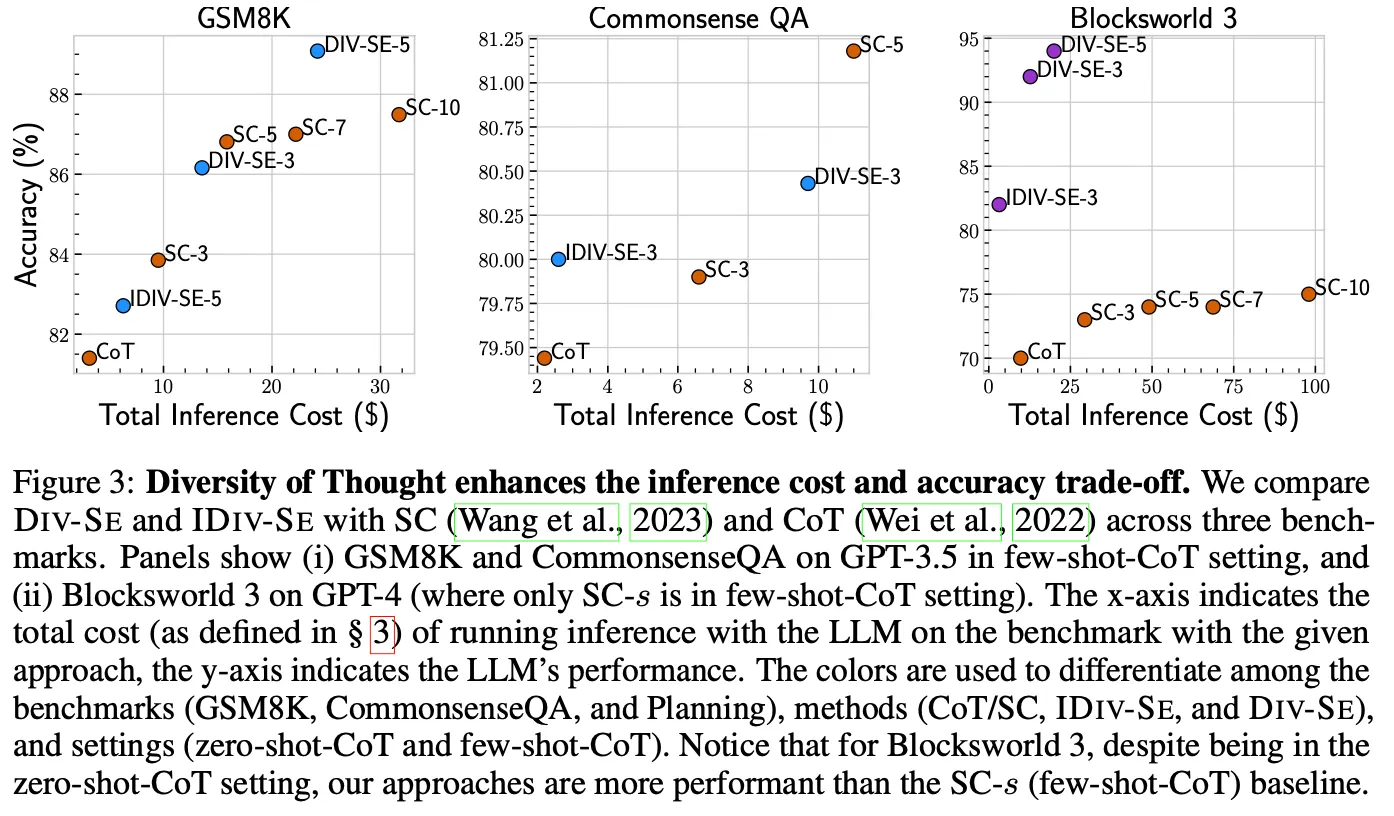
議論事項
•
LLMの能力が向上し、zero-shot, few-shotで解決できる問題の種類やレベルが徐々に高まっている。
•
したがって、最適な結果を得るためのプロンプト設計方法論が今後非常に重要になると思われる。
•
プロンプトを通じてパフォーマンスを向上させるための比較的簡単で有用な方法論として参考になる結果だと判断。