

導入
•
Promptingは人間が大規模言語モデル(LLM)を制御し、コミュニケーションする手段である。
•
ユーザーは、欲しい結果を得るために、どうすればうまくPromptingを作成できるかという一般的な方法論に対するニーズは今後も増えると思われる。
•
最近、生成だけでなく、自然言語理解(文の分類、シーケンスラベル付け、質疑応答)課題でプロンプトチューニングがファインチューニングよりも性能が良くなったというレポート(Lifu Tu et al. (2022)やCOT(Jason Wei et al. (2022)などのプロンプト方法論、そしてマルチモーダルでの応用(Andy Zeng et al. (2022)などが発表され始めている。
•
この記事では、プロンプティングを通じてzero-shotのパフォーマンスを向上させる興味深い2つの論文を紹介する。

•
レビュー論文
◦
◦
概要
•
COSP : Consistency-based Self-adaptive Prompting
•
USP : Universal Self-adaptive Prompting
•
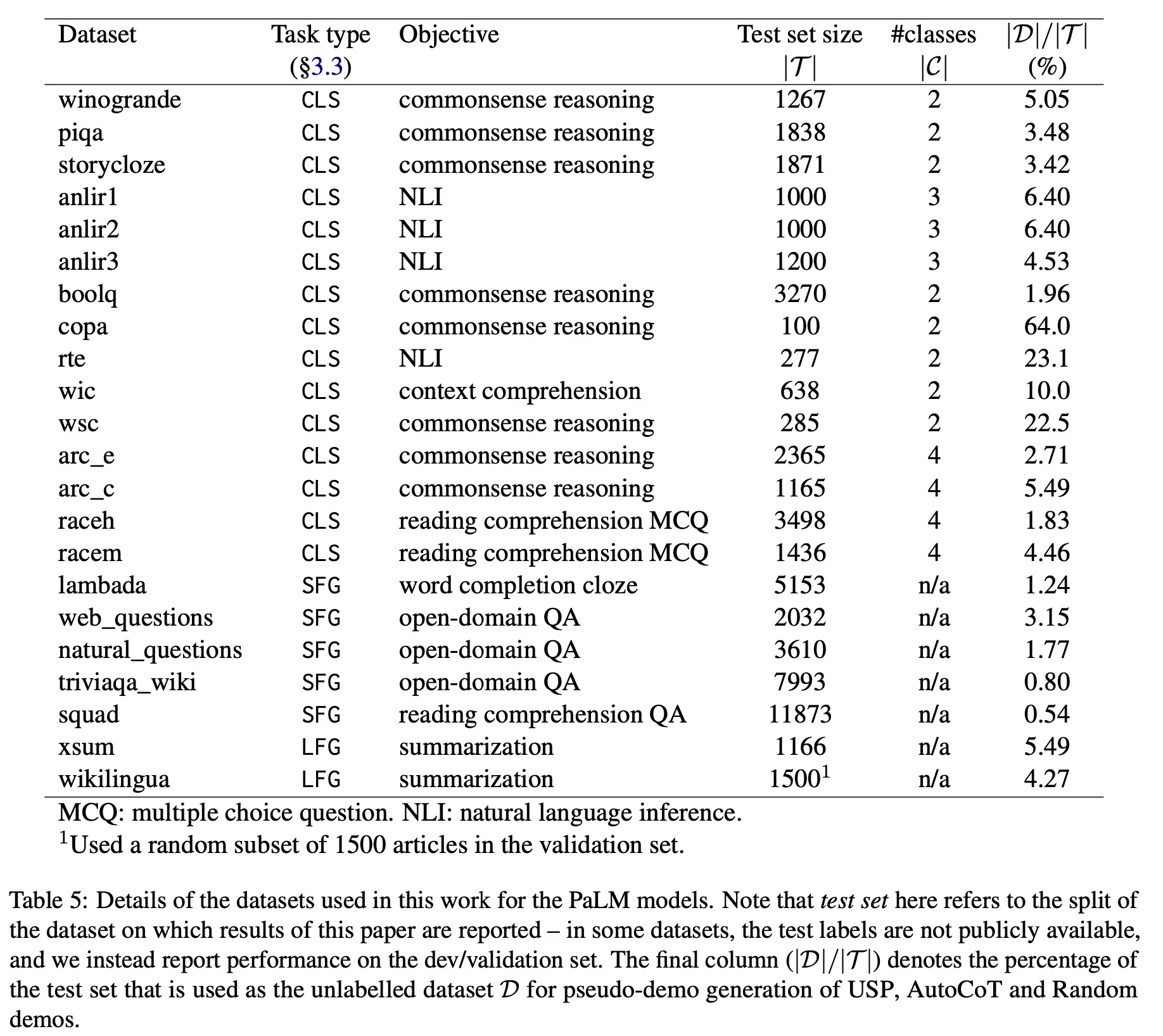
Unlabeled dataとblack-box LLMを通じてzero-shot in-context learning(ICL)の性能を向上させることを目的とした異なる2つの方法論
•
COSPが主にreasoningをターゲットにしているのに対し、USPはclassification(CLS)、short-form generation(SFG)、long-form generation(LFG)などもう少し多様なtaskをターゲットにしている。
•
方法論という側面でhigh-levelのコンセプトはほぼ似ているが、各段階の細かいところで若干の違いがある(COSPに対してUSPが持っている部分)
◦
デモ生成用データセットとテストセットを明確に分離(依存関係をなくす)
◦
Task-specific selectorを通じて与えられた課題に合ったデータ選択戦略を適用する。
◦
最終結果にはmajority votingを適用せず、LLMを一度だけ呼び出してgreedy decodingで生成する。
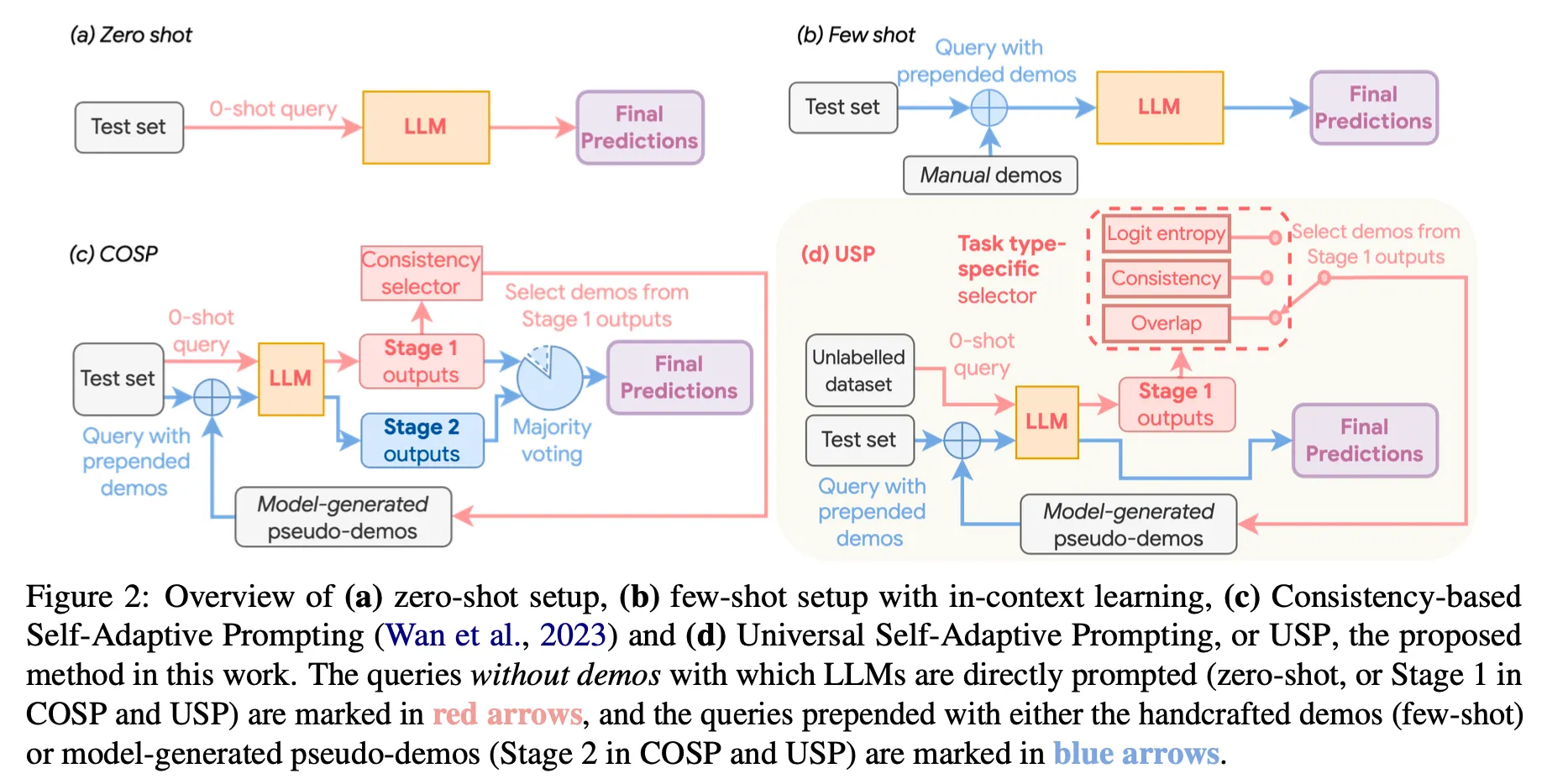
方法論
•
Stage 1 : pseudo dataの生成と選択
◦
Zero-shot 結果の生成
▪
COSP : zero-shot CoT promptでLLMを複数回呼び出し、1次生成結果を得る。
▪
USP : zero-shot promptでclassificationは1回、その他のgenerationは複数回呼び出して1次生成結果を得る。
◦
Promptに入れるデモデータを選択
▪
基本戦略
•
生成した例題のqualityを測定できるscoring functionの定義およびscoreの計算。scoring functionの定義は各taskごとに異なる(下記参照)
•
下記の値が最大になる例をGreedyに一つずつ選択して、希望の数K個になるまで追加(S_c : cosine similarity)

◦
COSP
▪
m個の生成結果のうち、heuristic rule(例えば、数に関する問題に数字が存在しない、長さが短すぎるなど)を適用してfiltering
▪
Scoring function : USPと同じscoring functionを使うために元のCOSP論文の関数から符号を変更。(q_a, q_b : a(b)-th phrases in rationale r)
◦
USP
▪
Classification
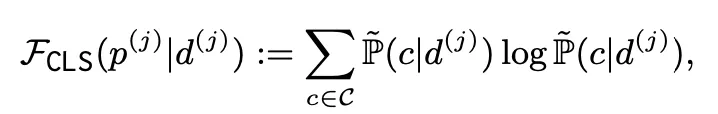
▪
Short-form Generation
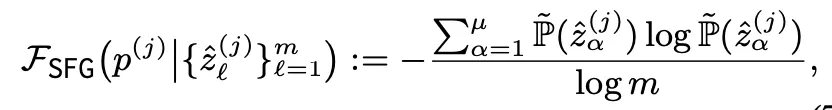
▪
Long-form Generation
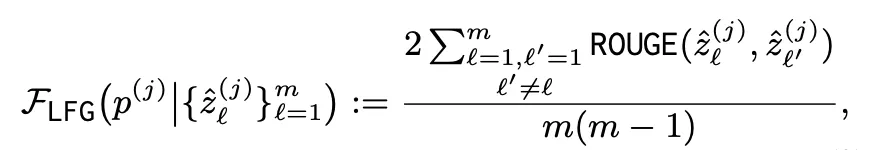
•
Stage 2 : few-shot 結果生成 & 最終結果導出
◦
COSP
▪
最終選択したK個の例を既存のプロンプトに追加してLLMを呼び出し、さらにm個の結果を生成。
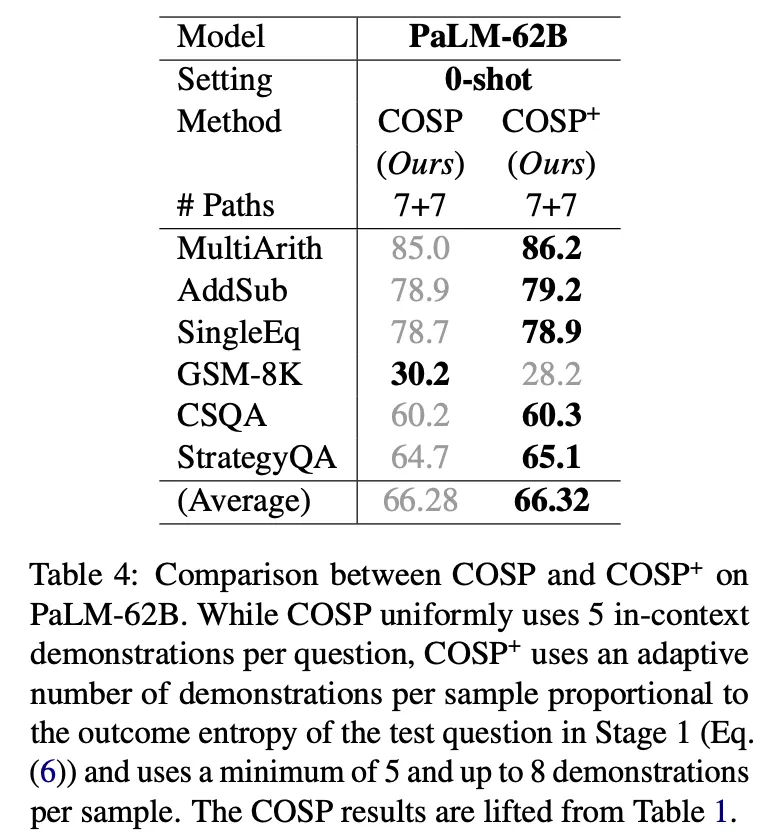
▪
normalized entropyに応じて動的にK値を調整するCOSP+も実験 : entropyが高いということはそれだけ難しい問題である可能性が高いので、より多くの例を選択。追加の性能向上があった。
▪
majority votingで最終結果選択
◦
USP
▪
LLMを一度だけ呼び出し、greedy decodingで生成します。
結論
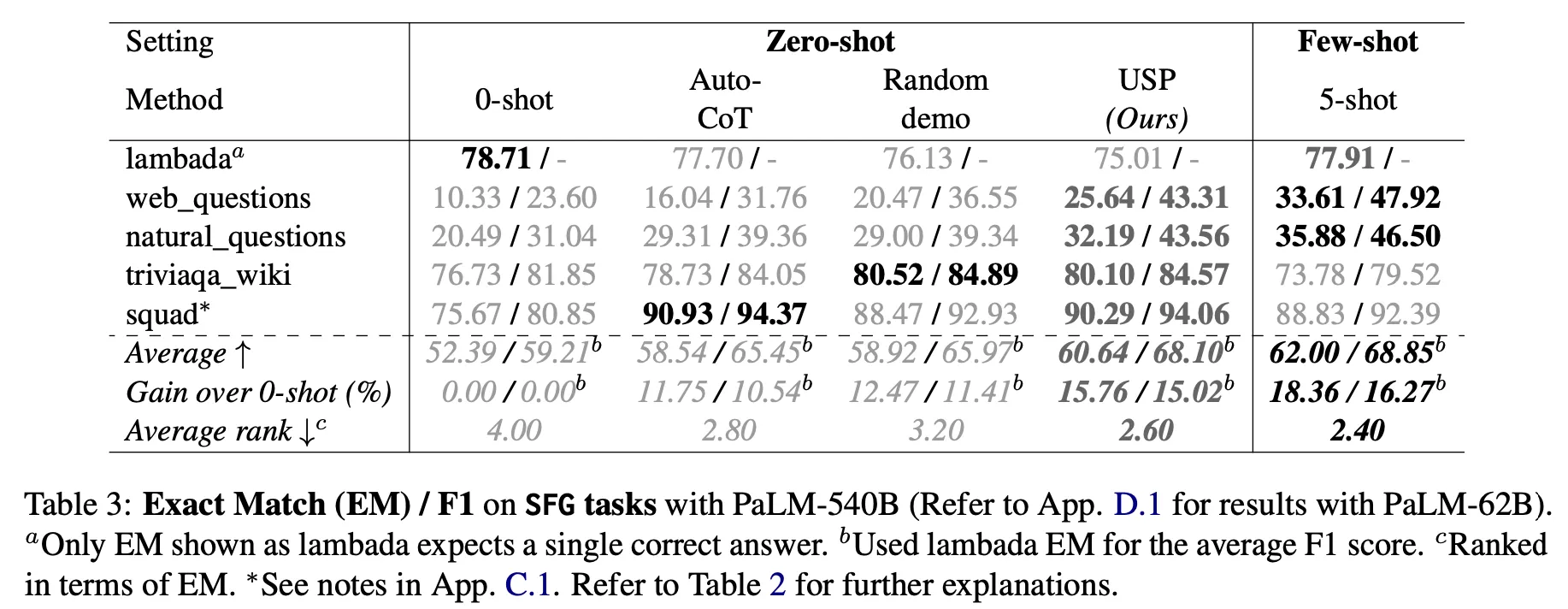
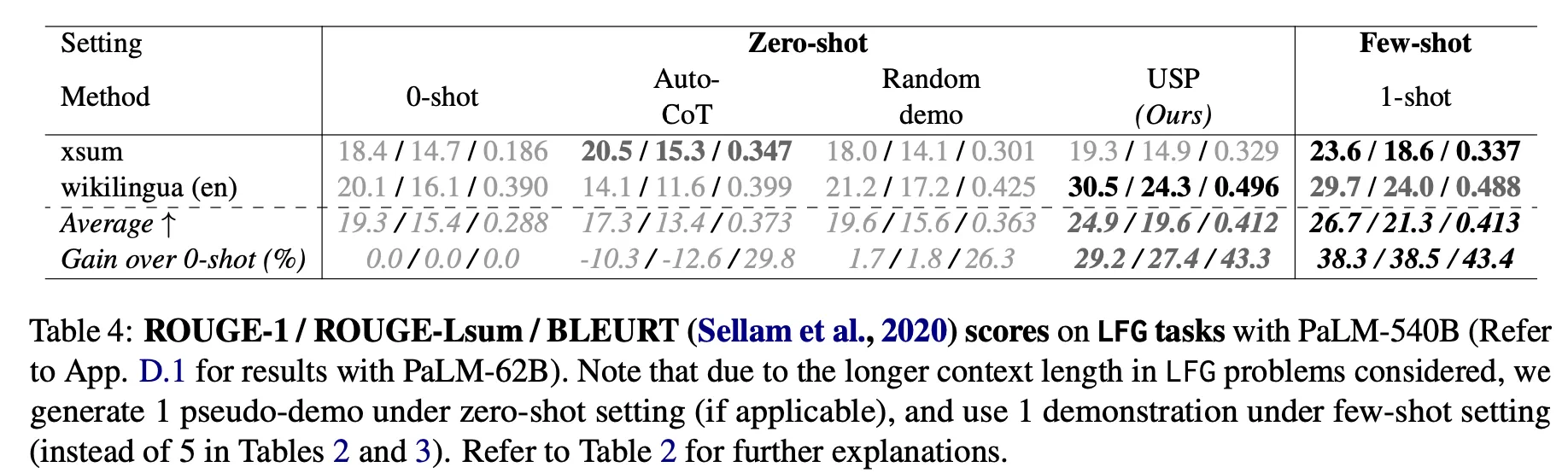
•
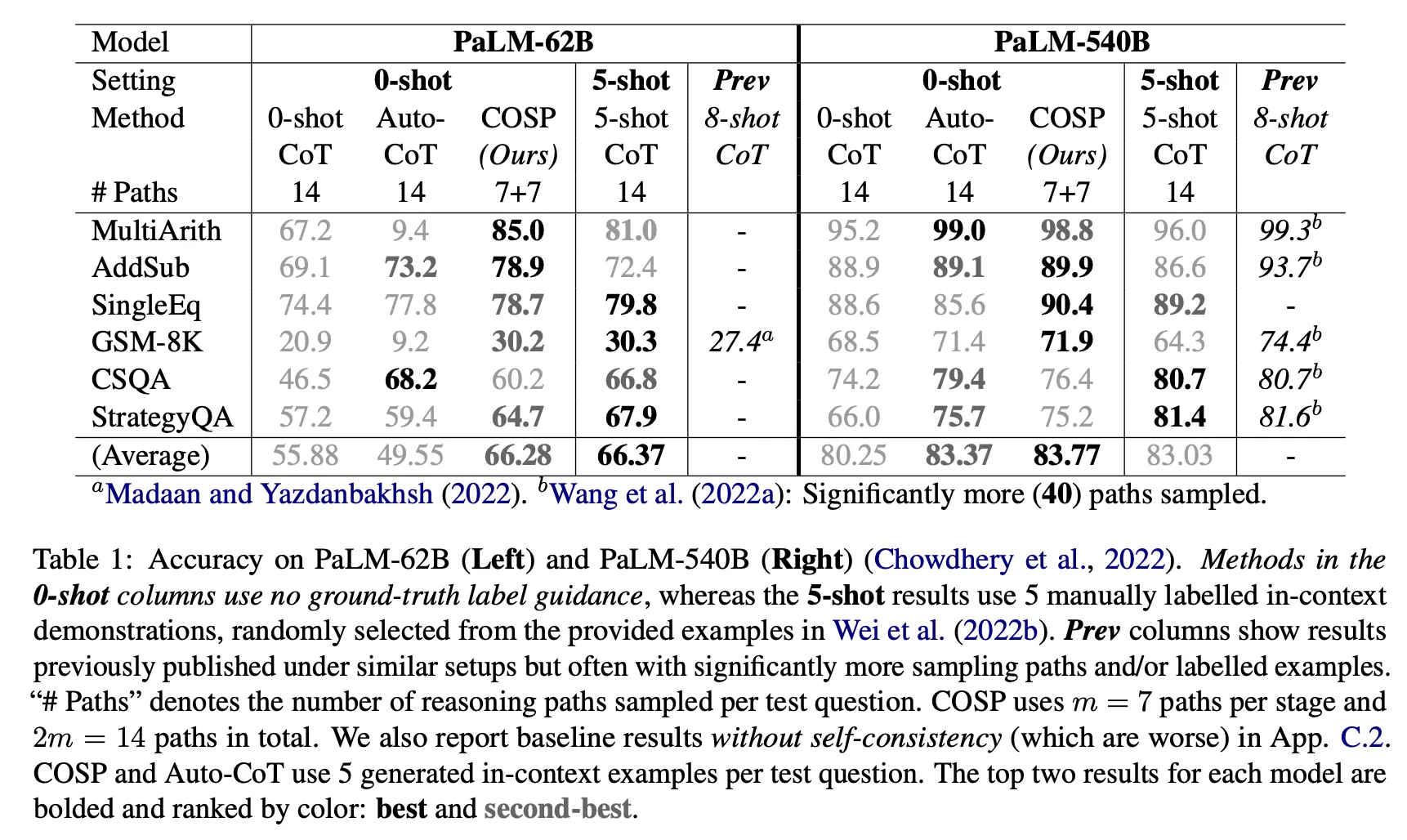
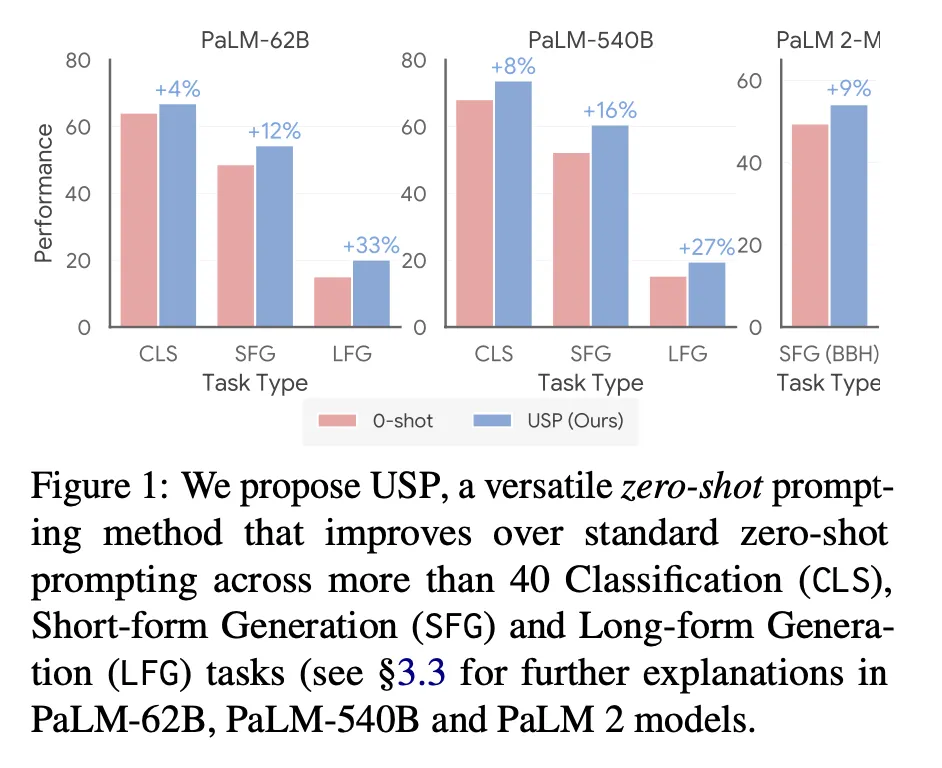
Zero-shotに比べて性能向上が確認された。
•
COSP on 6 reasoning tasks : 絶対値が >10% (PaLM-62B), >3%(PaLM-540B) 改善
•
USP on 40 NLG, NLU tasks : 相対値で 4-33% (PaLM-62B), 8-27% (PaLM-540B) 向上

議論事項
•
同じ著者がほぼ同時期に発表した、同じ目的を達成するための2つの方法論。
•
Labeled dataが全くない状況でモデル性能を高める興味深い方法論。しかし、完全なzero-shot ICL方法論というよりは、データおよびプロンプト生成方法論の観点から適用する方が実用的に有用だと判断。
◦
使用できるlabeledデータが全くなく、LLMをblack-box APIでしか使えない状況を想定。
スタートアップを含むほとんどの状況に適用可能な方法論。
◦
一度結果を得るたびにzero-shotで複数回生成し、few-shotで最終生成する2段階を経なければならないため、この方法論のままinferenceを構成するにはコストと応答速度の面で問題が存在します。
◦
したがって、最初のpseudo dataを生成して選択するStage 1の場合は、リアルタイムinferenceの時ではなく、プロンプトを設計する段階で作業し、実際のinferenceはStage 2の呼び出し1回だけ発生するように活用可能。COSPでも最後のmajority voting段階をfew-shotに対してだけすれば、上記のような方法でStageを分離して実装可能。
もっと読む
Lifu Tu, Caiming Xiong and Yingbo Zhou(2022), “Prompt-Tuning Can Be Much Better Than Fine-Tuning on Cross-lingual Understanding With Multilingual Language Models”, Conference on Empirical Methods in Natural Language Processing.
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Ed Chi, Quoc Le, Denny Zhou(2022), “Chain-of-Thought Prompting Elicits Reasoning in Large Language Models”
Andy Zeng, Maria Attarian, Brian Ichter, Krzysztof Choromanski, Adrian Wong, Stefan Welker, Federico Tombari, Aveek Purohit, Michael Ryoo, Vikas Sindhwani, Johnny Lee, Vincent Vanhoucke, Pete Florence(2022), “Socratic Models: Composing Zero-Shot Multimodal Reasoning with Language”