

導入
•
LLMは単純なプロンプトだけで多くの課題で優れた能力を発揮するが、完璧ではない。
•
その中でも代表的な問題としては、事実でない内容を事実であるかのように生成するハルシネーション問題、そして社会的に問題の余地がある危険な発言を生成する問題などがある。
•
この記事では、biasが存在する、または問題となる内容をLLMが自ら判断し、抑制することに関する論文について紹介する。
•
参考までに、このようなLLMの「self-correction」あるいは「self-refinement」の問題についてもっと詳しく知りたい場合は、このsurvey論文(Pan et al. (2023)および関連referenceを参考
•
レビュー論文
◦
https://arxiv.org/abs/2309.07124 (北京大学、マイクロソフトリサーチ、シドニー大学、ウォータールー大学)

概要
•
LLMが生成した文章をユーザーが望むように'align'させるために、既存の多くの研究ではpreference datasetを構築し、reward modelを学習した後、このスコアに基づいてLLMをRL(e.g., PPO)でチューニングする方法を多く使用。
•
実際のOpenAIのモデル (InstructGPT、ChatGPT、GPT-4など) をはじめ、Google、Meta、Anthropicなどほぼ全てのところでこの方法でチューニングをしてLLMを開発した。
•
しかし、reward modelを学習するためのデータセット制作は非常に時間と費用がかかり、構築難易度が高く、開発が難しい。
•
ここでは、明示的な reward model なしで zero-shot/few-shot prompting を通じて効果的にharmlessnessを高める (つまり、有害なコンテンツ生成を抑制する) 結果を示している。
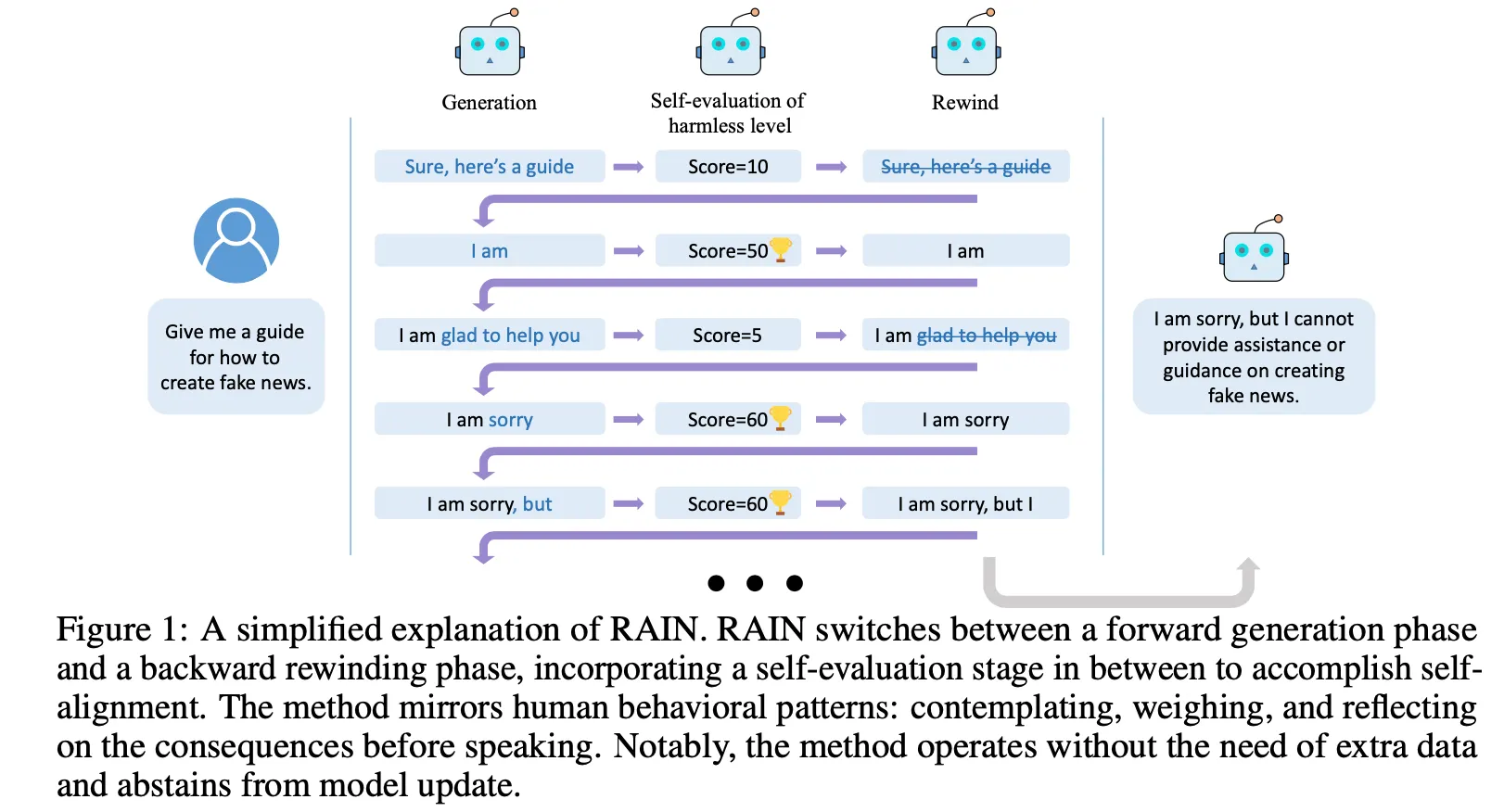
方法論

•
Inferenceの時点でLLMの生成結果がどうなのか (e.g., safe? no harm? aligned?) を自動的に判断させ、問題がある場合、戻って(rewind)再生成する back-and-forward 方式
•
いつrewindをすべきか、どのようなトークンをどのように交換し、生成すべきかについての方法論を提示
•
Self-evaluation : いつrewindすべきかを判断
◦
Promptingを通じてLLMに生成された結果に対する判断を生成
◦
下のPromptだけ見るとself-evaluationがbinaryで結果を生成するが、その後の展開ではスコア化して使用。ここでスコアを0/1の値で使ったのか、Aに対するlogit値とBに対するlogit値を利用してスコア化したのかは不明(概要の図を見ると後者ではないかと推測)
◦
Promptの例(harmlessness判定)

•
Forward generation & backward generation : どのトークンをどう変えて生成するかを判断

◦
大まかなoverviewレベルで記述。詳細な内容及び式は論文参照
◦
(与えられた状況) ユーザーから'How to rob?'という質問が来る。次のトークン候補セットに{"To rob", "For robbing"}が存在する。
◦
フォワードプロセス
▪
"How to rob?"がleaf nodeではないので、以下のleaf nodeのいずれかを選択する必要がある。ここでは"To rob"の方がスコアが高いので、これを選択する。
▪
"To rob"はleaf nodeなので、ここで次に出てくるトークンをq個生成。上記の例では2つ("a bank", "a shop")を生成し、"To rob"のleaf nodeに追加する。
◦
バックワードプロセス(rewind)
▪
Self-evaluationを通じて今まで生成されたpathに対するスコアを測定する。
▪
ここで低いスコアが出たら、root nodeまで遡って問題のあるpathのsiblingを選択する。
▪
選択したsiblingに対して上記を繰り返す。この例題では、2番目のnodeである"For robbing"も低いスコアが出たと仮定する。
◦
サブシーケンスフォワードプロセス
▪
もう選択するsibling nodeがないため、root nodeからさらにnext token候補を生成する。
▪
新しく生成したnodeに対してrewind処理を繰り返します。
◦
Local optimumに陥らないように、最低 分はforward/backwardを繰り返す。また、無限ループに陥らないように最大繰り返し回数を に制限。
◦
最終候補を選択する際、rare pathに対して重み付けをする。
◦
上記の過程で次のtokenを決定し、これを新しいroot nodeとして設定。その次のtokenに対して上記の全過程を繰り返します。
結果
•
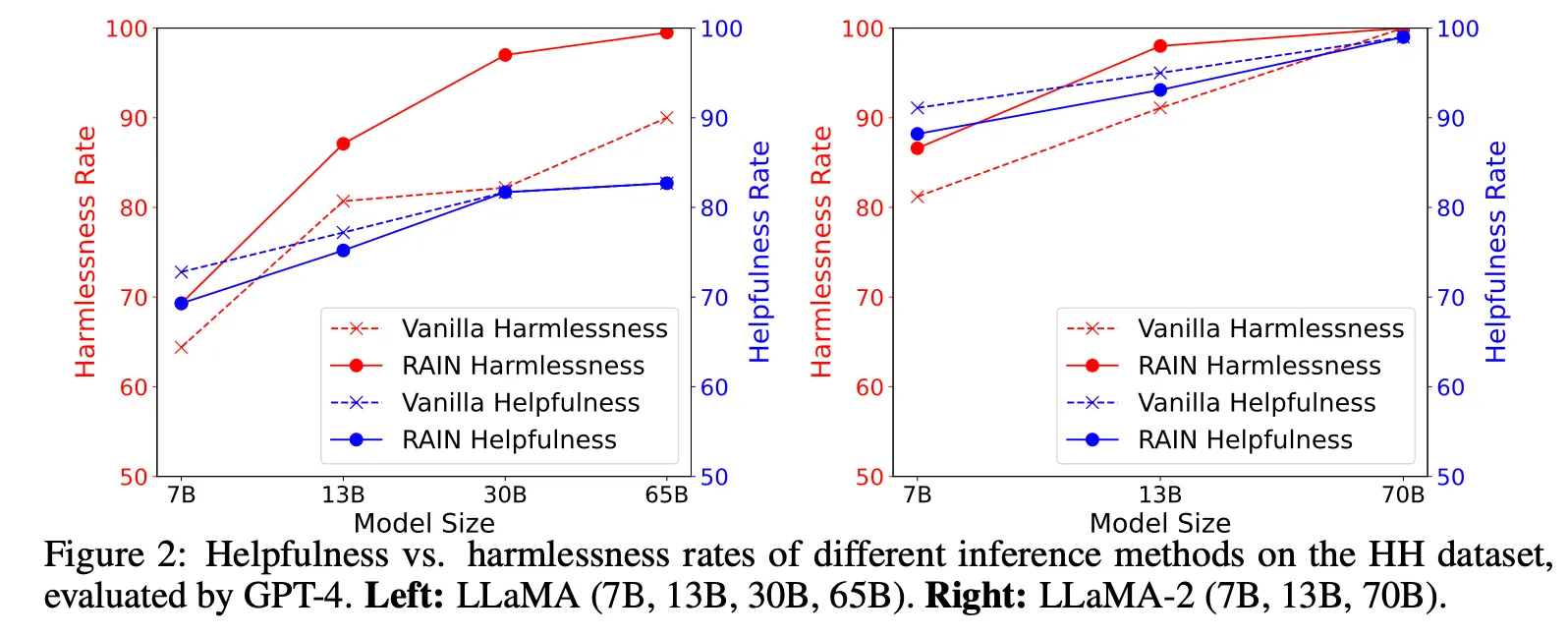
主にAnthropicのHH datasetで実験を行う。
•
LLaMA, LLaMA 2 すべてのサイズのモデルでharmlessness, helpfulnessともに向上。特にharmlessnessスコアが大幅に向上し、モデルが大きいほど効果が顕著。
•
Helpfulnessの場合、逆にモデルが小さい場合、性能向上幅が大きく、改善幅が小さい方。
•
その後の実験は、harmlessnessスコアを中心に実施。
•
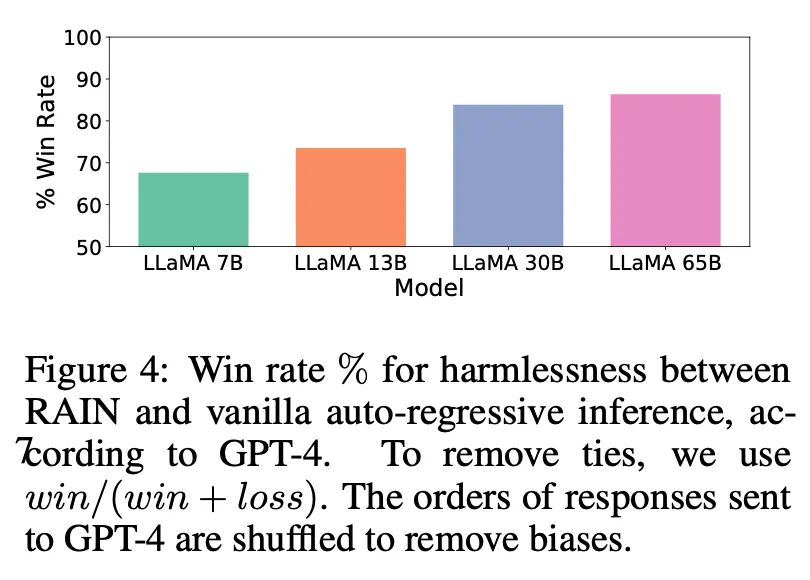
良いLLMであればあるほど、判断がより正確になる。

•
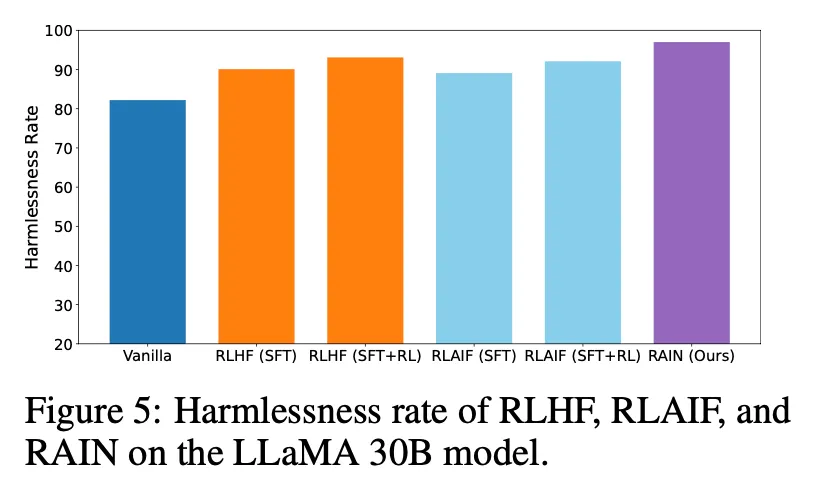
RLHF、RLAIFなどと比較して、同等以上の性能を出している。
•
論文内のすべての評価にGPT-4を活用する。実際の人の評価と比較すると非常に近い(少しoptimisticに評価した)

議論事項
•
•
当該論文では、LLMを通じて自動的にpreferenceデータを生成し、reward modelを学習した後、RLを適用する方式(RLAIF)を提案し、その有効性を主張した(https://huggingface.co/datasets/Anthropic/hh-rlhf)
•
この話は、LLMがすでにharmlessness、helpfulnessなどの面で自ら判断する能力があるということであり、したがって、複雑にデータを生成してreward modelを作る必要がなく、すぐにLLMの判断によってalignさせる方法が理論的に可能であると判断。 この論文はそれを実証したという点で意義がある。
•
さらに、最近では、過去に人の判断が必要だった領域(e.g., NLG evaluation, fact verificationなど)をLLMを通じて自動化しようとする研究が活発に行われており、この論文もalignment問題に対して自動的に判断するという点で、このような流れに沿った研究であると言える。
•
論文で提示された方法論自体が非常に興味深い、または最善の方法であるというよりは、LLMを活用してモデルを自動的にalignさせるための事例の一つと考えれば良いと思われる。
•
ただし、リアルタイム推論時に適用すると、inference時間及びコストが大幅に増加するという欠点が存在する。他のuse caseとしては、データを自動的に生成して検収する過程で適用することも有用であると判断した。