

導入
•
•
この記事では、アルゴリズム問題だけでなく、様々な自然言語タスクでLLMが持つ優れたコード生成能力を適切に活用できる方法論を提示した「chain of code」という論文を紹介する。
•

概要
•
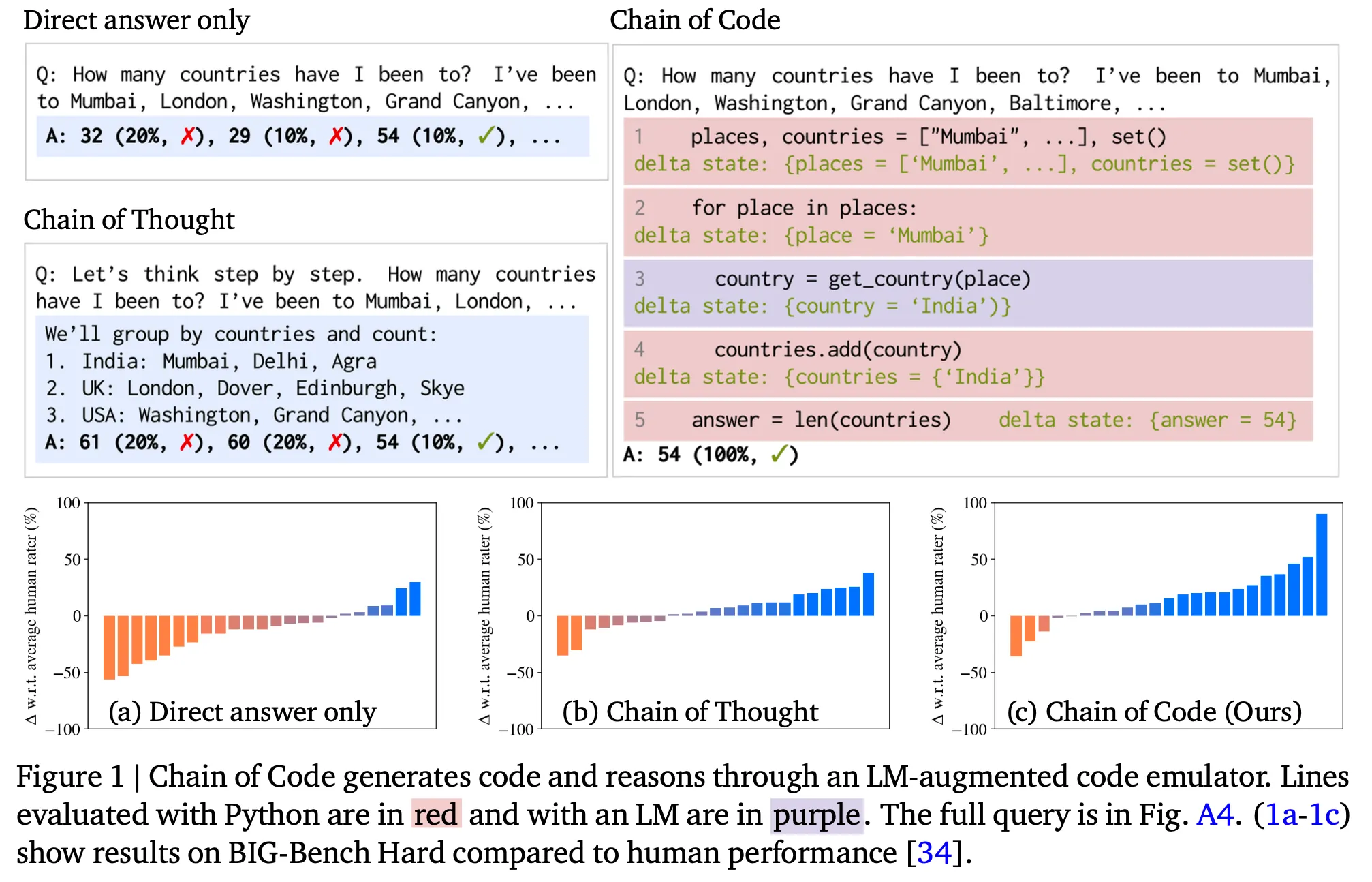
一行要約 : LLMにcode-driven reasoningをさせたら効果が良い。
•
数学的計算だけでなく、semantic reasoningをしなければならない問題でも、LLMに(pseudo) codeを生成させた後に適切なエミュレータで実行し、結果を得てからそれを活用すれば、より良い性能を達成できることが示された。(例えば、detect_sarcasm(input))
•
•
特にCoTは一定サイズ以上のLMでのみ効果があったのに対し、CoCは小さなLMでも効果があった。
方法論の詳細
•
代表的な既存の方法論との比較

•
Scratchpad : 推論過程をcode形式で生成。LLMがcode interpreterの役割を実行(codeの実行をLLMが自ら実行)
◦
Chain of thoughts : 推論過程を自然言語で生成。この内容を次のステップの生成に活用。
◦
Program of thoughts : 推論過程をcode形式で生成。生成したコードは別のcode interpreterで実行。
•
アイデアは比較的シンプル。Code generationとcode executionの段階で構成。
•
Code generation : prompting技法を通じて与えられた問題に対してLLMが解決過程をcodeの形で生成するようにする。
•
コード実行
◦
Python interpreterを優先的に使用し、ここで実行できない部分(例えば、detect_sarcasm(input))はLLMをエミュレータとして使用(すなわち、"LMulator")。
◦
基本的にはPythonのtry/except文を活用。実際の実装ディテールを基準として次のようなvariationが存在する。
▪
Interweave : 生成コードをline by lineで実行。エラーが発生した時、該当の生成ラインと前のcontextをLLMに入れ、state値を出力。
▪
try Python except LM : 生成コード全体をPythonで実行。エラー発生時にLMに入れて最終回答を生成
▪
try Python except LM state : 生成コード全体をPythonで実行。エラー発生時にLMに入れ、中間状態を出力。
◦
ベースライン
▪
LM state : 生成コード全体をLMに入れ、各ステップの中間状態を出力。Scratchpadに対応。
▪
Python:生成コード全体をPythonで実行。失敗時はただfail。
▪
LM : 生成コード全体を LM に入れて最終回答を生成。
▪
Direct:few-shot prompting。
▪
CoT : 思考の連鎖。
結果
•
全体的な性能面
◦
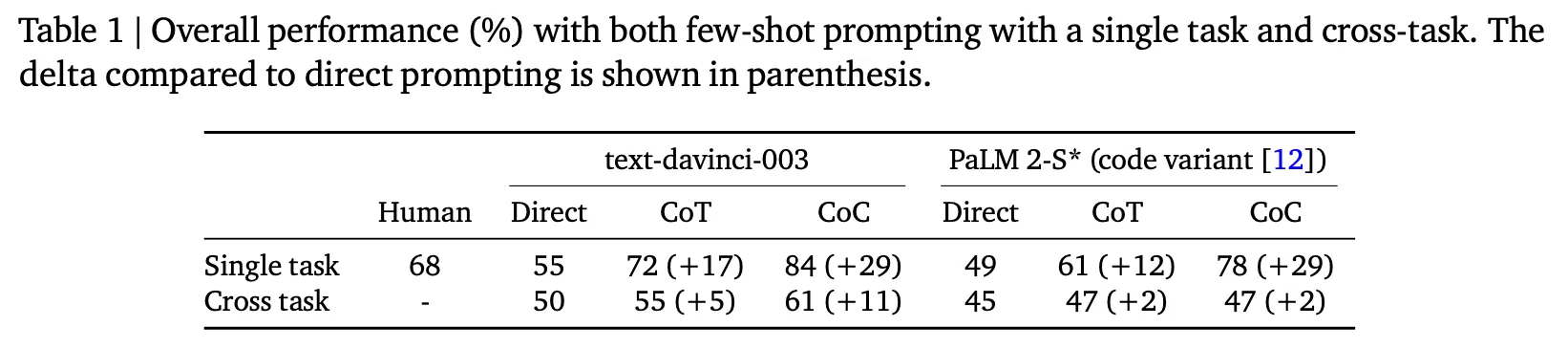
CoTよりはるかに優れた性能を示し、特にBBHで84%であればSOTAを達成したと言われる。
◦
さらに、同じ方法論を適用した場合、BBHデータセットではtext-davinci-003がPaLM 2よりも優れた性能を発揮する。
◦
•
CoCがうまく動作するタイプは?
◦
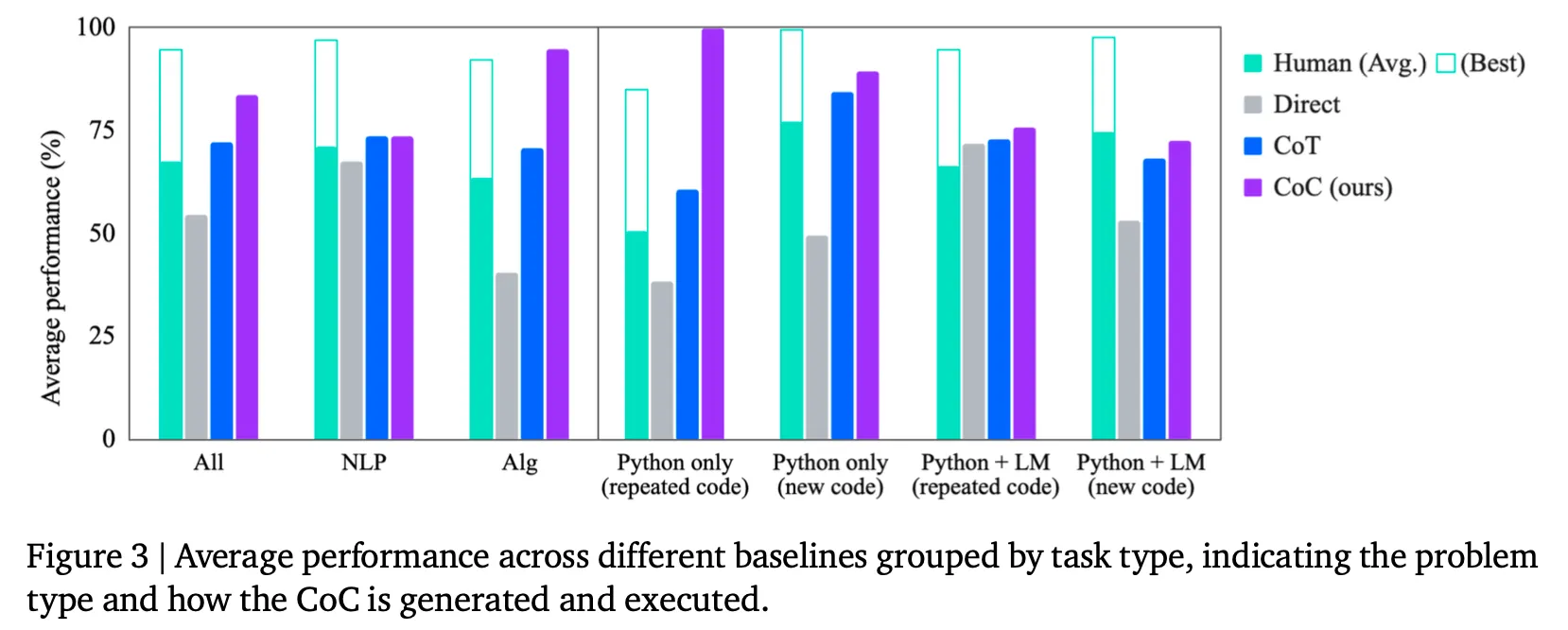
NLP taskはCoTと同様のレベルであり、algorithm taskでは特に強みがある。
◦
Pythonでは完全実行可能し、同じコードで入力だけ変わるtask(Python only & repeated code)ではほぼ完璧な姿を見せている。残りの場合も効果が減るものの、まだbaselineに比べて優れた結果を示している。
•
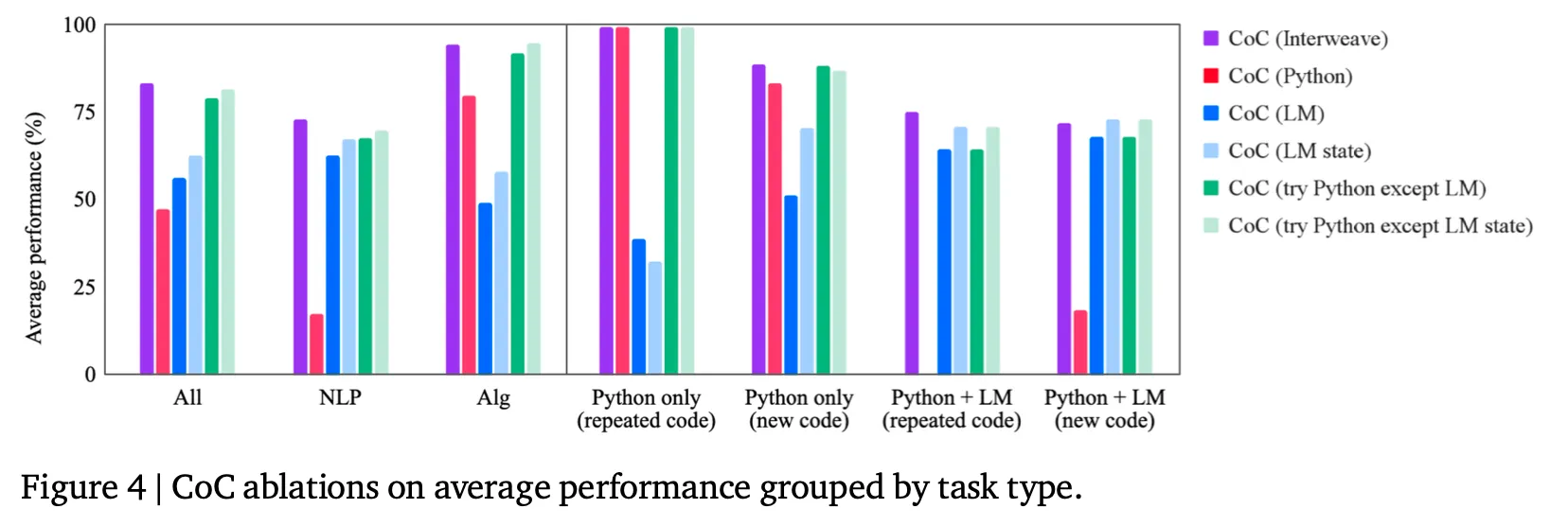
CoCにおけるエミュレータの種類による性能の比較
◦
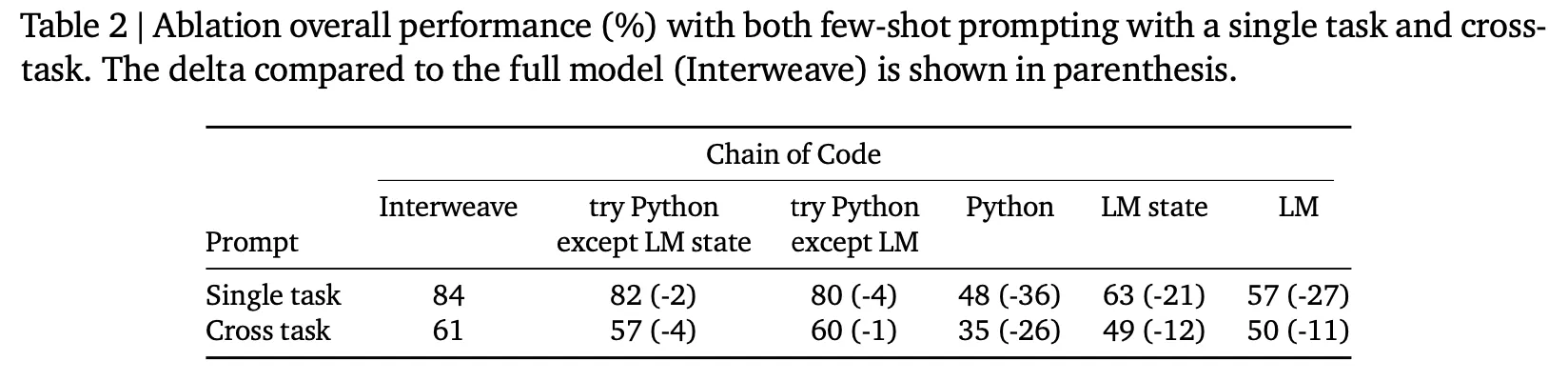
提案された方法の中でinterweaveが一番良いが、他の2つの代替方法(try Python except LM state, try Python except LM)もほぼ同じような性能を示す。
•
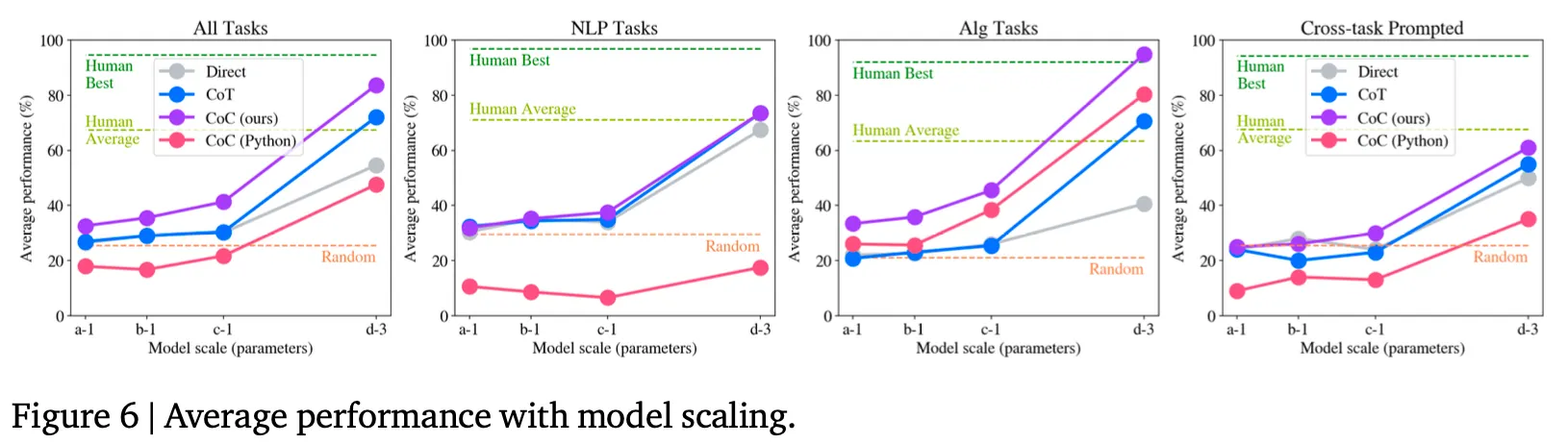
Modelサイズによる効果は?
◦
CoTのようにモデルサイズが大きいほど効果が大きくなる。
◦
ただし、CoTと違ってモデルが小さくてもdirect promptingに比べて性能が同等か、その以上である。これはモデルにとってnatural languageを生成することよりcodeを生成することが比較的簡単な課題であることを示す結果だと判断される。
•
Generalization能力
◦
Cross taskは、解きたいtaskに該当する例を入れるのではなく、他のtaskの例を入れたときの性能である。したがって、複数のtaskに対する一般化能力を測定できる方法だと言える。
◦
上の図(Table 2の最後の行、Figure 6の4番目のグラフ)から分かるように、クロスタスクでCoCの効果が大きく減少するものの、比較対象技法に比べて効果がある。
•
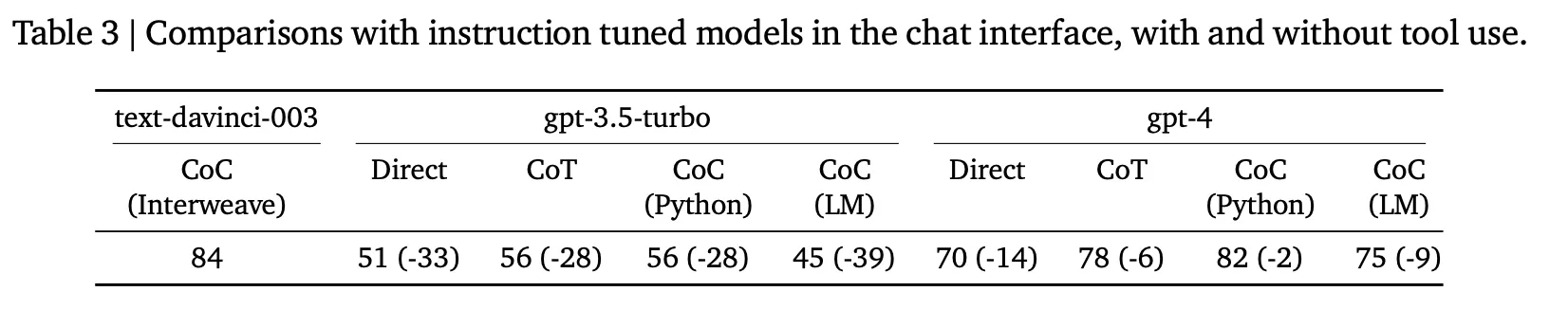
Chat modelでの効果
◦
InstructGPT(text-davinci-003) vs ChatGPT(3.5) vs ChatGPT(4)
▪
それぞれの方法論に合ったinstructionをchat interfaceに入力する。 (e.g., "direct answer", "step-by-step", "write python code to help solve the problem, if it's helpful")
▪
ChatGPTの場合Direct、CoT、CoC(Python)とCoC(LM)のみ適用して実験する。
▪
ChatGPTでも複数のターンにわたってCoC(try Python except LM)のような方法は適用できそうだが、この部分は別途に実験されていない。
議論事項
•
GPT-3の公開はLLMがparameter updateなしで簡単なpromptの入力だけで様々なtaskを実行できる可能性を示したのに対し、InstructGPTおよび以降のモデルではLLMの理解および推論能力が飛躍的に向上した姿を見せた。
•
その原因としては、instruction followingデータとともに大量のcodeを学習したことが重要な要素であると知られている。
•
理由を推測してみると、codeとは、ある問題を解決するために定型化された形で論理構造を表現する手段なので、LLMが様々な推論過程で"code"の助けをもらい、関係を導き出したり、計算を行い、次のactionを予測するなどの姿を見せるからだと推測する。
•
従来にもLLMに明示的にcodeを生成してreasoningに活用した事例はあった。しかし、この論文は生成コードに対してcode interpreterとLLM interpreterの両者の能力を両方 leverageする方法論を提示した部分がkey ideaだと思う。
•
LLMの能力を最大化するためには、コーディング能力と言語理解能力の両方を最大限に活用する必要があると考えている。