

表データの役割
•
表データの歴史
(1) 特定ドメインに関連するデータが主に構築されたが、バスケットボールに関連するRotowire(Wiseman et al, 2017)データセット、生物学に関連するKBGen(Banik et al, 2013)、Wikibio(Lebret et al, 2016)データセット、レストラン予約などに関連するE2E(Novikova et al, 2016, 2017)などがその例である。(2) 表による文章生成に関しては、Puduppully,R.(2018), Ankur Parikh et al(2020), Jonathan et al(2020) などがある。この記事では、その中でもToTTo:A Controlled Table-To-Text Generation Dataset について説明する。

ToTTo で表ベースの文章生成データを作成するプロセス
•
(1) 様々な形式のフォーマットからタイトル、サブタイトル、表情報を抽出した後、主要な表情報を黄褐色で強調表示(highlight)する。
•
(2) 表と一緒に収集した文章(下の画像でOriginal text)から表の内容と関係ないものは削除(text after deletion)した後、最終的に文章を作成し、文章生成の精度を高めた。
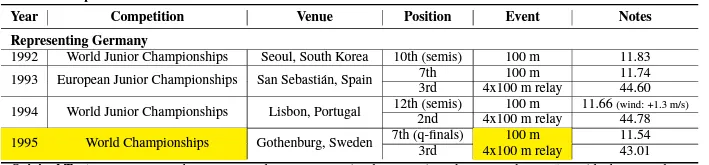
上記の画像から分かるように、様々な形式のフォーマットからデータを抽出するため、データ入力にも多くの時間とコストがかかる。 また、表から必要な情報を抽出することと、そこから推論可能な文章を作り出すことが、表ベースの文章生成の目標であり、難しい点である。
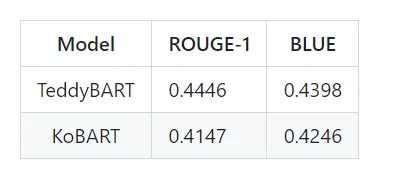
韓国では、「(韓国)国立国語院人工知能言語能力評価」示範運営課題のうち、「表ベースの文章生成」課題があり、ベースラインモデル及び学習と評価のためのデータセットはteddysumの korean_T2T_baselineで確認できる。 2022年基準モデルの性能は次の表の通りである。
議論事項
•
上記の表から確認できるように、50%にも満たないため、まだ改善すべき部分が多いことが分かります。
•
表情情報抽出で重要な情報を要約し、基礎統計を提示することは、現段階では重要な課題である。
•
入力データの多様なフォーマット、組織図のように重要情報と補助的情報を区別する必要がない形式などを考慮する必要がある。
最近の動向を反映した記事
•
文字認識参考リンク : Nougat (facebookresearch.github.io)
•
2D関係型テーブルを理解するための資料リンク : Paper page - Table-GPT: Table-tuned GPT for Diverse Table Tasks (huggingface.co)
参考文献
Ankur Parikh, Xuezhi Wang, Sebastian Gehrmann, Manaal Faruqui, Bhuwan Dhingra, Diyi Yang, and Dipanjan Das. 2020. ToTTo: A Controlled Table-To-Text Generation Dataset. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 1173–1186, Online. Association for Computational Linguistics.
Chin-Yew Lin, 2004, ROUGE: A Package for Automatic Evaluation of Summaries. In Text Summarization Branches Out, pages 74–81, Barcelona, Spain. Association for Computational Linguistics.
Eva Banik, Claire Gardent, and Eric Kow. 2013. The kbgen challenge. In Proc. of European Workshop on NLG.
Jekaterina Novikova, Ondˇrej Duˇsek, and Verena Rieser. 2017. The E2E dataset: New challenges for end-toend generation. In Proc. of SIGDIAL.
Sam Wiseman, Stuart M Shieber, and Alexander M Rush. 2017. Challenges in data-to-document generation. In Proc. of EMNLP.
Rémi Lebret, David Grangier, and Michael Auli. 2016. Neural text generation from structured data with application to the biography domain. In Proc. of EMNLP.
Sebastian Gehrmann, Tosin P. Adewumi, Karmanya Aggarwal, et al(2021), “The GEM Benchmark: Natural Language Generation, its Evaluation and Metrics”, In Proceedings of the 1st Workshop on Natural Language Generation, Evaluation, and Metrics, Online. Association for Computational Linguistics.