


導入
•
"CICERO: A Dataset for Contextualized Commonsense Inference in Dialogues"データセットのようなケースは、人工知能モデルの常識的思考と関連している。常識的思考の形成は人にとっては簡単だが、人工知能にはまだ期待するのは難しい。
•
また、常識的思考は事実的思考とは異なり、行間を読んで解釈する必要があるため、推論の領域に属している。
•
CICEROにはCICERO-v1とCICERO-v2がある。ここではv2のデータと論文を中心に扱う。
•
下の画像は、日常的に起こる様々なこと(人は常識的に知っていること)から、5つの状況(原因、後続事象、前提条件、内的動機、感情反応)を推論して文章を生成する課題である。
•
評価は、人工知能が人間と同じような推論能力を発揮できるかどうかに基づく。
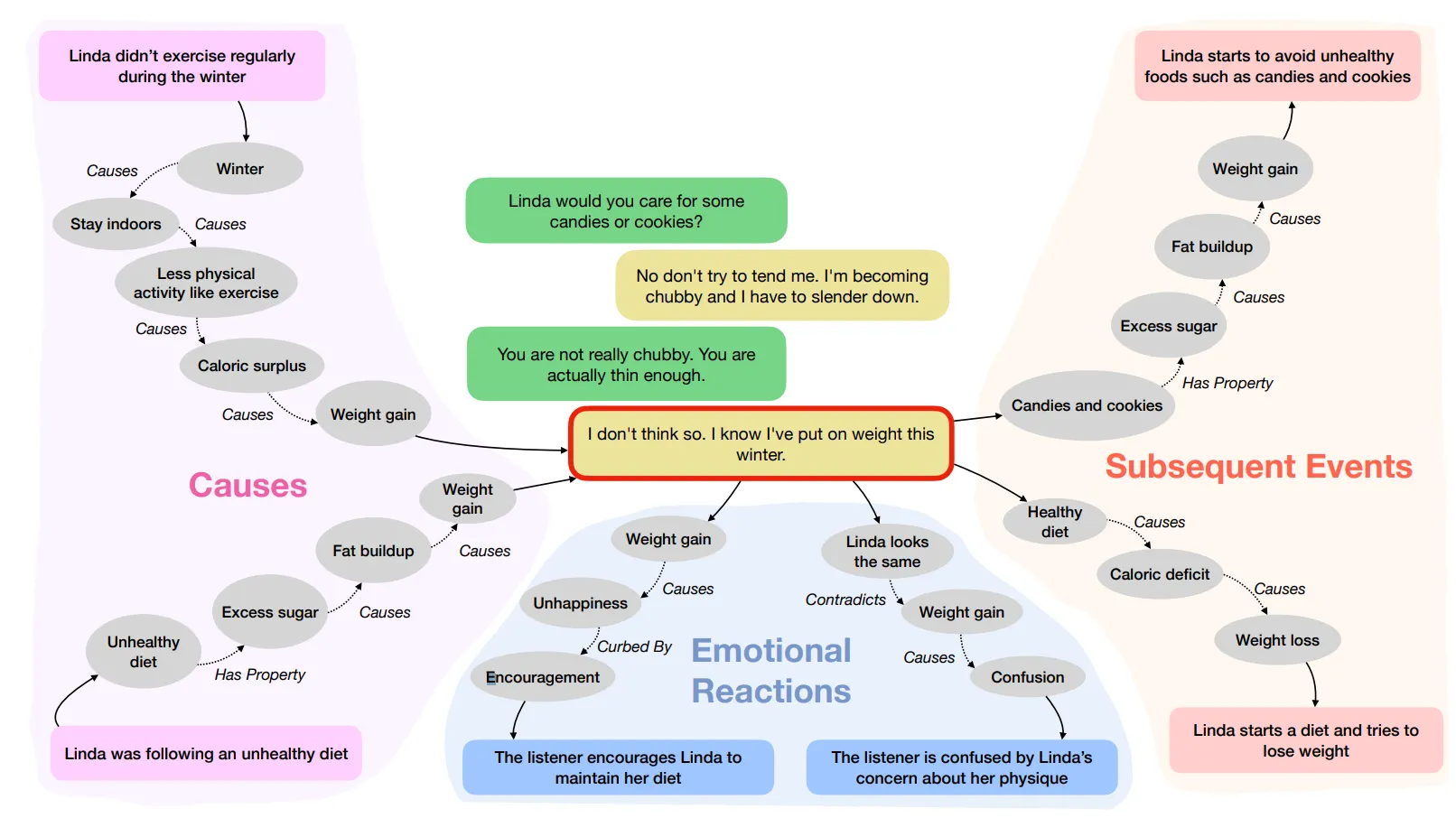
上の画像を他の例で、もう少し具体的にみると、次のようになる。
会話の例
A: 何のご用件ですか?
B: オレンジをください。
A: フロリダ・オレンジとカリフォルニア・オレンジの中でどちらにしますか?
B: どちらが良いですか?
A: フロリダオレンジは甘いですが、サイズが小さく、カリフォルニアオレンジには種がありません。
B: じゃあ、カリフォルニアオレンジを5個ください。
A: 他に必要なものはありますか?
B: バナナも食べたいですが、どうやって売っていますか?
A: 1ドルで1ポンドです。何個望みますか?
B:4個もらったらいくらですか?
A: 1ポンドです。
B: わかりました、いくらですか?
A: 3ドルです。
B: ここにあります。
A: ありがとうございます。
質問:赤色で表示された目標会話(カリフォルニアオレンジを5個ください)以降、どのようなイベントが発生したか、または発生する可能性がありますか?
 商人はカリフォルニアオレンジ5個を包みました。商人はカリフォルニアオレンジ2個を包みました。 商人はカリフォルニアライム2個を包みました。 商人がカリフォルニアオレンジ1個を包みました。 商人の友人がカリフォルニアオレンジ5個を包みました。
商人はカリフォルニアオレンジ5個を包みました。商人はカリフォルニアオレンジ2個を包みました。 商人はカリフォルニアライム2個を包みました。 商人がカリフォルニアオレンジ1個を包みました。 商人の友人がカリフォルニアオレンジ5個を包みました。モデルと結果の解釈
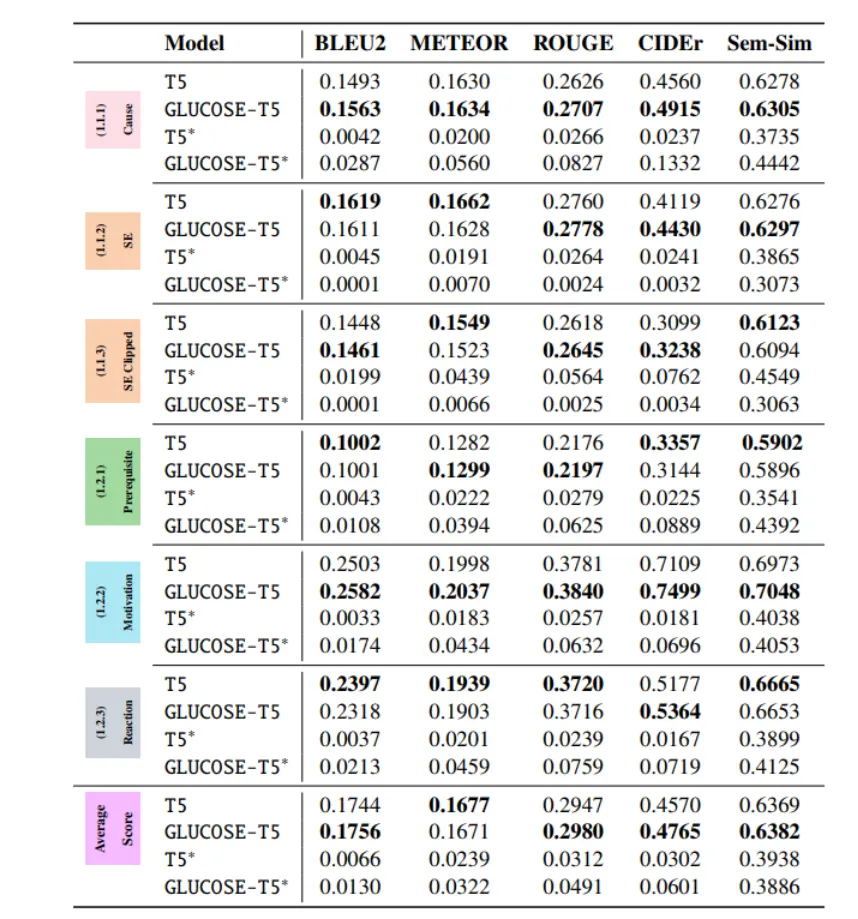
まず、生成モデルであるT5モデル(BLUE2、METERO、ROUGE、CIDEr、Sem-Sim)による結果は次のようになる。
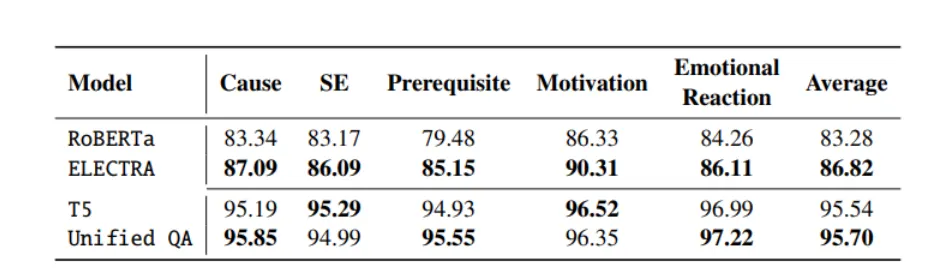
また、RoBERTa、ELECTRAのような分類モデルによるスコアでは、動機(Motivation)スコアが最も高い。
追加分析
このような一般常識の問題は、様々なモデルで挑戦してもいい課題である。以下はクclaude.aで簡単にテストした結果である。

上記の質問を回答が定めらていない推論質問ではなく、文脈の中で回答を見つけられる質問にした理由は、(1)客観的な評価が可能だから、(2)文脈理解能力と想像力(A.K.A脳内推論)を区別しなければならないからである。
つまり、推論問題にとって最も重要なのは、客観的な推論根拠を持って人と同じように推論したかどうかということである。
論文の出典
@inproceedings{ghosal-etal-2022-cicero,
title = "{CICERO}: A Dataset for Contextualized Commonsense Inference in Dialogues",
author = "Ghosal, Deepanway and
Shen, Siqi and
Majumder, Navonil and
Mihalcea, Rada and
Poria, Soujanya",
booktitle = "Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers)",
month = may,
year = "2022",
address = "Dublin, Ireland",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2022.acl-long.344",
pages = "5010--5028",
}
Plain Text
복사