

RAG(Retrieval Augmented Generation)とファインチューニング
大規模言語モデル(Large language model, LLM)は、一般的な課題をうまく処理する利点があります。私たちがChatGPTに熱狂する理由も、一般的な知識に関する質問や推論に対して必要な答えをうまく生成するためだと思います。しかし、日常生活での大規模言語モデルの有効活用には、個人や組織レベルで特定のデータを学習させることが不可欠です。
本稿では、RAGとファインチューニングという2つの方法を取り上げます。これらはいずれも、大規模言語モデルをベースにしてカスタマイズを行う手法ですが、それぞれにコストと性能の面で異なる特徴があります。
まず、言語モデルをプライベートなLLMとして使用できる方法として、ファインチューニングがあります。事前学習された大規模言語モデルに小さなデータセットを追加で学習させ、特定の作業に合わせて微調整して性能を改善する方法です。伝統的に、ファインチューニングは巨大な単位のウェブデータを事前学習し、小さな分野の課題に応じてチューニングを行う方法でしたが、モデルのパラメータ数がどんどん大きくなり、企業や研究者がモデル全体をファインチューニングすることが難しくなり、ファインチューニングしたモデルの保存とコストも非常に大きくなりました。この他にも、新しい情報を学習する際、以前に学習した情報を突然急激に忘れる現象、つまり破壊的忘却(Catastrophic forgetting)と呼ばれる現象も解決に困難がありました。
ChatGPTなどのLLMモデルが産業的に台頭し始めてからちょうど1年が経ち、各企業が見つけた費用対効果の高い代替手段がRAGと言えます。RAG手法は、LLMの強力なテキスト生成力をベースに、ユーザーのクエリに合った必要な文書スニペットを適切に取り出し、モデルにプロンプトを提供して応答する方法です。LlamaIndexやLangchainのような開発者ツールやunstructured.ioのような前処理SDK、そしてMilvusのような複数の商用のベクターサーチDBが最近1年間に誘致した投資額とバリュエーションを見ると、業界におけるRAGに対する関心度は容易に推測できると思います。
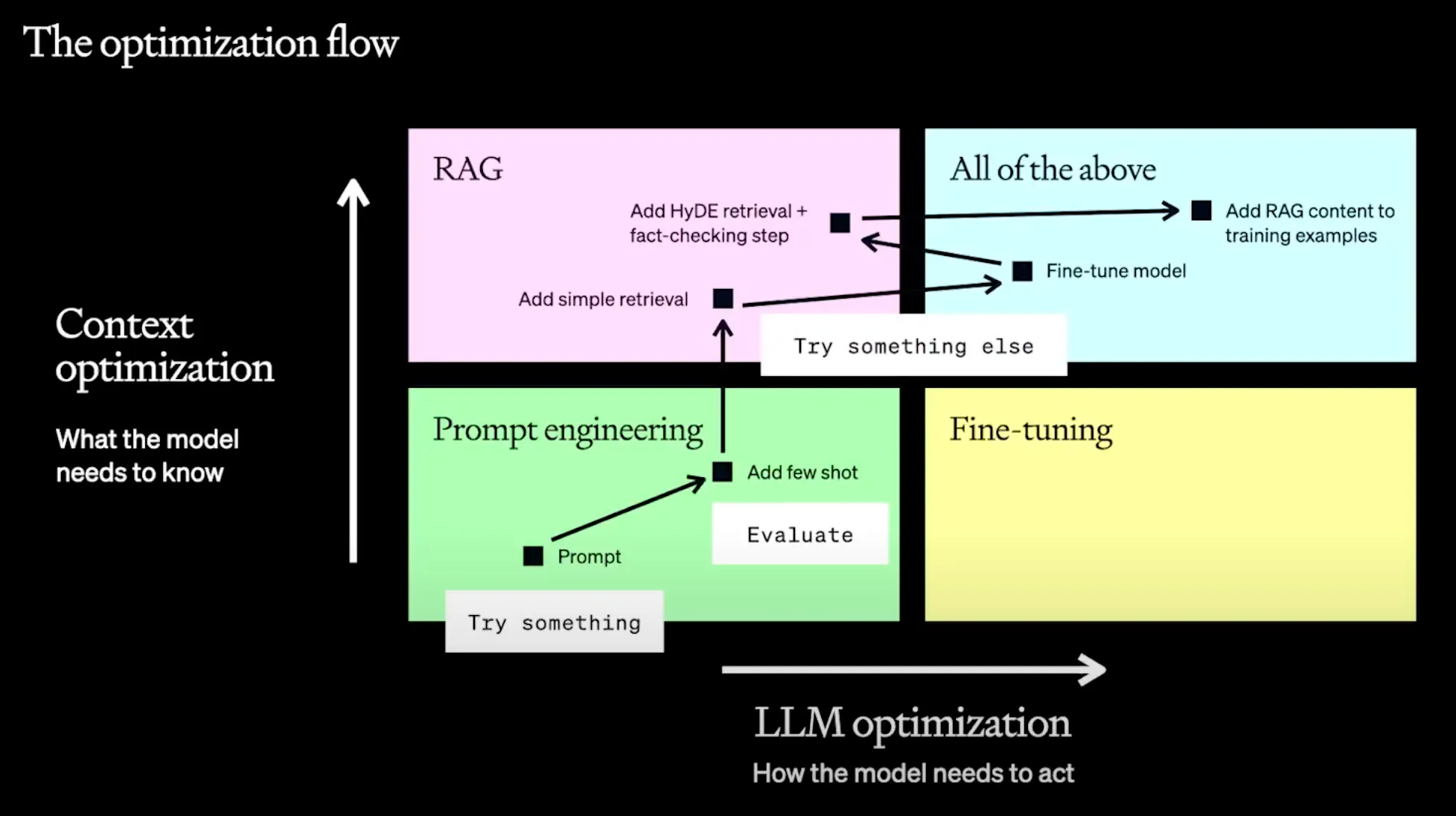
写真出典: OpenAI - A Survey of Techniques for Maximizing LLM Performance https://youtu.be/ahnGLM-RC1Y
しかし、モデルの目的そのものをより自由に変えられるという点で、ファインチューニングが持つ魅力も無視できません。モデルが応答するスタイルやトーンやマナー、フォーマットのような質的な面を変えたり、希望する形のアウトプットが出ることを保証したり、TextをSQLに変えるなどのプロンプトだけでは説明しにくい特定のタスクに特化する必要がある場合は、ファインチューニングが有利な場合もあります。
OpenAIは前回のDevDayでファインチューニングとRAGが必要な場合を2つの軸で整理して紹介しました。モデルの知識的な側面を修正したい場合にはRAGを、モデルがどのように答えて推論するかを修正したい場合にはファインチューニングが適していると紹介しました。
過去には簡単ではなかったベースモデルのファインチューニングが、2つの側面から、一般開発者にとってアクセスしやすい形になってきていると思います。一つは、商用化されたモデルのクラウドサービスとしての「ファインチューニング用のAPI」(https://platform.openai.com/docs/guides/fine-tuning/fine-tuning-examples)を提供していることと、もう一つは、ファインチューニングのプロセス全般の難易度が下がり、少しの知識さえあれば、公開モデルを利用して独自のデータセットを持ってプライベートな環境でファインチューニングができるようになったことです。 今回の記事シリーズでは、このように独自のデータセットでファインチューニングするプロセスを実習してみたいと思います。
1.
オープンソースベースの大規模言語モデルを基に、独自のデータセットでファインチューニングする。
2.
当該モデルのインファレンスをWebGPUを活用してローカルで行うことで、機密性の高い情報を外部に公開することなく、ローカルで自分だけのLLMを駆動できる。
今回の記事では、Meta AIが公開したLLaMA 7B Chatモデルを基に、QLoRAを活用して自分だけのデータをファインチューニングし、Hugging Faceに配布してみたいと思います。
経済的なファインチューニングのためのPEFTとQLoRA
個人や会社の機密データを外部に持ち出すことなく、自分のモデルを継続的にチューニングし、更新することができたら、AIを「最高に飼いならし、育てられる」と言えます。 ファインチューニングする方法もやや簡単になっていて、まず、GPUの普及率が上がるとともにWebからGPUに直接アクセスできるようになり、一般の開発者がCUDAプログラミングに対する高い理解がなくてもWebからインファレンスを実行できるようになりました。また、ファインチューニングを行う際に、モデル全体のパラメータを修正することなく、一部のパラメータのみを更新しても、全体のパラメータを修正した場合と同等の性能を期待できるほど簡素化された手法が普及しています。
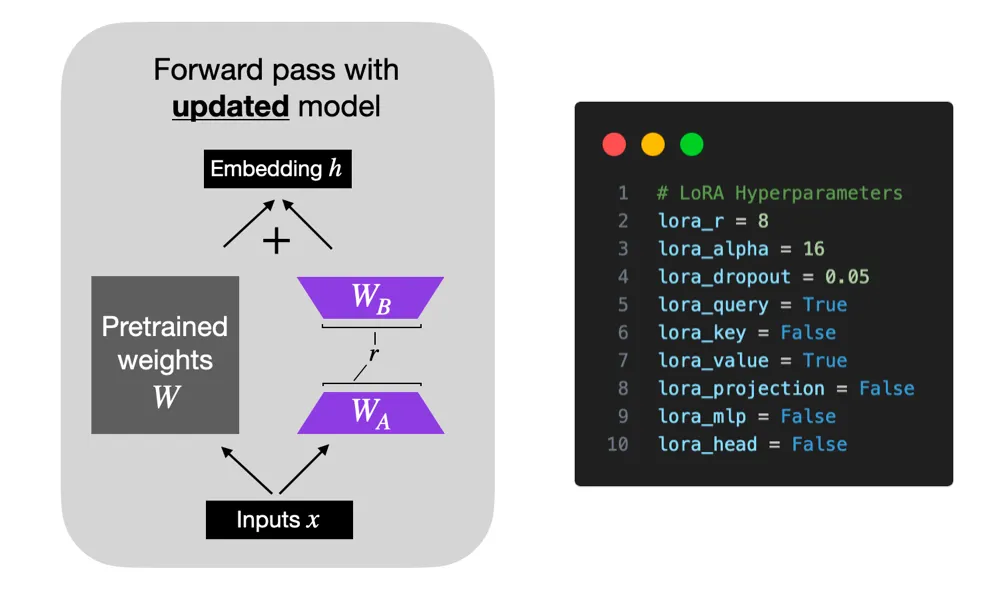
最近、ファインチューニングの手法としてチェックポイントやPEFT(Parameter Efficient Fine-tuning)などが注目されています。PEFTはモデル全体のパラメータをチューニングする必要がなく、一部のパラメータをチューニングしてもモデルの性能を少ないリソースでチューニングできる方法を意味します。PEFTにはLoRA(Low Rank Adapation)が主に使用されており、最近ではQLoRAが提案されています。LoRAは、固定されている重みを持っているPretrainedされたモデルに基づいて追加学習が可能なRank Decomposition行列をトランスフォーマーアーキテクチャの各層に付けたものです。つまり、トレーニング可能なレイヤーを追加して、別のトレーニングを通じて学習させたものになります。
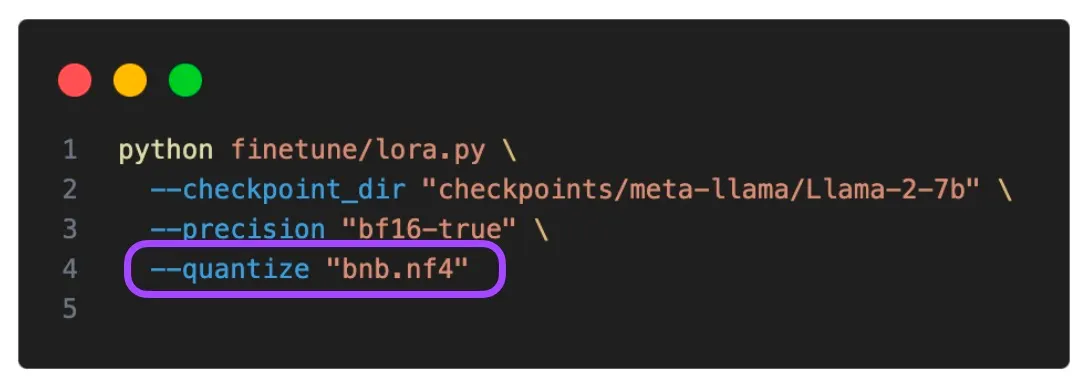
LoRAはLow Data Regimeのようにデータが少ない状況でもファインチューニングが容易という利点があり、ドメイン外のデータを一般化する際に良い性能を示すと言われています。私たちがLoRAを通じて学習させた重みは少量ですが、事前学習されたLLMモデル層の一番上の部分を占めることになり、他のパラメータにどれだけ影響を与えるかhyper parameterを適切に設定することでモデルの性能を決定することができます。
特に最近ではQLoRAという4ビット量子化手法が注目され、LLMモデルを少ないビットのフォーマットに設定することで、大きなメモリのGPUがなくてもファインチューニングが可能になりました。大規模言語モデルのパラメータサイズが大きくなっていく中でも、適切な量子化とdistillationを通じてモデルに保存され、メモリロードの負担を軽減します。QLoRAはLoRAの重みをNormalFloatというFP4を変形したデータ型を使用して4ビット量子化します。
このデータ型は、非線形的な間隔と非対称分布に基づいて-1から1までの範囲を表して保存します。量子化によりサイズを縮小しながらも、トレーニングやバックプロパゲーションでは逆量子化を行い、低レベルのビットを32ビットに近似して一定の性能を維持することができます。
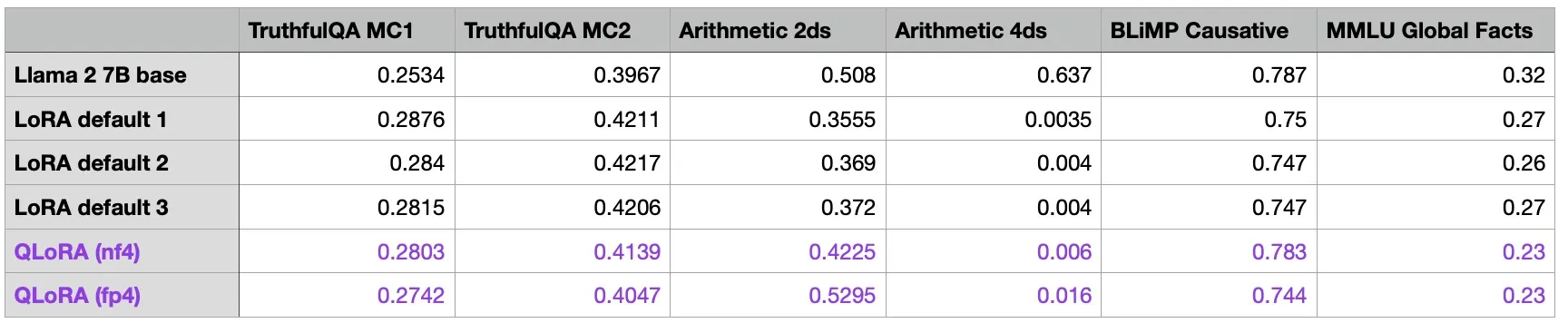
上の表を見ると、QLoRAを活用した場合、一般的なLoRAよりモデルへの影響が少ないことが確認できます。量子化がインメモリーロードの負荷を低減させるのにかなりの効果があることを考慮すると、コストパフォーマンス的に効果的な方法だと言えます。
そこでこの記事では、LLaMA2 7Bのベースモデルをもとに、QLoRAを活用したファインチューニングを簡単に実習します。実習に使用したJupyter Notebookファイルはこのリンクからダウンロードできます。
Step 1. 必要なライブラリをインストールしてインポート
!pip install -q accelerate==0.21.0 scipy tensorboardX peft==0.4.0 bitsandbytes==0.40.2 transformers==4.31.0 trl==0.4.7 tensorboardX
JavaScript
복사
import os # osモジュール オペレーティングシステムと相互作用できる機能を提供
import torch # PyTorchライブラリで、主にディープラーニングと機械学習モデルの構築、学習、テストに使用します。
from datasets import load_dataset # データを簡単に読み込んで処理する機能を提供します。
トランスフォーマーインポートから (
AutoModelForCausalLM, #因果的言語推論のためのモデル(例えばGPT)を自動で呼び出すクラス
AutoTokenizer、#入力文をトークン単位で自動的に切り取る役割
BitsAndBytesConfig, #モデルの設定
HfArgumentParser, #パラメータ解析
TrainingArguments, #トレーニング設定
pipeline, #パイプライン設定
logging, #ロギングのためのクラス
)
Python
복사
•
私たちが最も注目すべきライブラリは「BitsAndBytes」です。先に見たベクトルのINT8最大絶対値量子化手法を使用できるように支援するMeta AIのライブラリです。
Step 2. Llama 2モデルとデータのインポート
# Hugging Faceハブでトレーニングしたいモデルをインポートして名前を指定する
model_name = "NousResearch/Llama-2-7b-chat-hf"
# instruction データ設定
dataset_name = "mlabonne/guanaco-llama2-1k"
# fine-tuning(ファインチューニング)をした後のモデルに付与される新しい名前を指定する変数。
new_model = "sionic-llama-2-7b-miniguanaco"
JavaScript
복사
私たちは今回の実習で事前学習されたベースモデルとしてLlama 2の7B Chatモデルを選択します。Meta AIのHuggingfaceレポジトリにLLaMA 2公式モデルがありますが、そのモデルはGatedバージョンなので、NousResearchで追加公開されたLLaMA 2 7B Chat HFモデルを使用します。
一方、Instructionファインチューニングのためのデータセットとしては、OpenAssistant Converation Dataset (OASST 1)をLLaMA 2のプロンプト形式に合わせて1000個に減らしたバージョンを使用しました。最後に、新しく作成するモデルの名前を自由に指定します。
Step 3. LoRA (Low-Rank Adaptation) パラメータ設定
# LoRAで使う low-rank matrices アテンション次元を定義。ここでは64に設定
# 値が大きければ大きいほど、より多くの修正が行われ、モデルがより複雑になる可能性があります。
lora_r = 64
# LoRA適用時に重みに乗算されるスケーリング要素。 ここでは16に設定。
# LoRAが適用されたとき、元のモデルの重みにどの程度影響を与えるかを決定。高い値は、重み付け調整の強度を増加させます。
lora_alpha = 16
# Dropout probability for LoRA layers # LoRA層に適用されるドロップアウト確率。ここでは0.1(10%)に設定。
lora_dropout = 0.1 # 一部のネットワーク接続をランダムに無効にすることで、モデルの堅牢性に貢献します
Python
복사
•
重みを調整して、より良い性能を出し、追加的な作業によりよく合うようにする手法です。これは、モデルの全体構造を変更することなく、効率的にモデルを調整することができるという利点があります。
•
上で peft ライブラリからImportした LoraConfig に割り当てるパラメータについて一つずつ説明します。
•
まず、 lora_r は、情報の損失と効率のバランスをとるために複数の試行を通じて決定できるパラメータです。モデルの重み付け行列を2つの低ランク行列の積で近似するため、lora_rの値が大きいほど、より多くの情報を保持しながらモデルがトレーニングデータに過度に適応し、オーバーフィッティングする可能性が高くなります。一方、 lora_r の値が低いほど情報が失われ、モデルがデータの複雑な特性を捉える可能性が低くなります。
•
また、lora_alphaは、LoRAを適用する際に重みに乗算されるスケーリングファクターで、元のモデルに対してLoRAの重みにどれだけ影響を与えるかを決定します。
•
最後に、lora_dropoutパラメータは、従来の機械学習で過適合を防ぐために、トレーニング過程でネットワークの一部の重みを0に設定する方法を適用するために使われます。これは、重み付け行列を調整する際に低ランク行列で重み付け行列に近似しますが、このときLoRAの変化量をモデルに適用する前に、一部の要素を任意に0にする方法です。
Step 4. bitsandbytes パラメータ設定。
前述したように bitsandbytes は QLoRA を適用するために使用される8ビット量子化ライブラリです。このライブラリで量子化に関する設定値を指定することができます。例えば、4ビットベースモデルを読み込み、4ビットモデルの演算で使用するデータ型の指定し、量子化のタイプを明示するなど詳細設定を行うことができます。
# 4-bit precisionベースのモデルロード
use_4bit = True
# 4ビットベースのモデルのdtype計算
bnb_4bit_compute_dtype = "float16"
# 量子化タイプ(fp4またはnf4)
bnb_4bit_quant_type = "nf4"
# 4ビット機モデルに対して重畳量子化を有効にする(二重量子化)
use_nested_quant = False
Python
복사
Step 5. **TrainingArguments パラメータ設定。
•
TrainerはHuggingfaceが提供するライブラリで、モデルの学習から評価まで一度に解決できるAPIを提供します。以下はTrainに必要なパラメータを定義したもので、Optimizerの種類とLearing Rate、Epoch数、SchedulerとHalf Precisionの使用有無などを指定することができます。
•
num_train_epochsパラメータでモデルがデータセット全体を何回繰り返して学習するかを指定することができ、per_device_train_batch_sizeで各GPUで一度に処理するデータ量を指定することもできます。ここでは1に設定われているので、一度に一つのデータのみを処理するようにしました。gradient_accumulation_stepsパラメータは、勾配を更新する前に何回勾配の更新を蓄積するかを決定するもので、ここでは1に設定し、ステップ毎に勾配を更新します。最後に、gradient_checkpointingパラメータでメモリ使用量を最適化することができます。これは大規模モデルを使用する場合に特に便利なパラメータで、必要なときにのみ特定の階層の勾配を保存し、残りの勾配を破棄してメモリを節約します。
•
max_grad_normパラメータを使ってモデルがデータから学習する速度を調節します。勾配が過度に大きくなって発生する可能性があるgradient exploding問題などを防止できるように勾配の最大サイズを設定します。そして今回の実習でAdamオプティマイザを使うのですが、この時、learning_rateを保守的に設定してモデルがデータから学習する速度を適切に遅くするようにします。最後にweight_decay値を適切に設定して、モデルの重みが大きすぎる値を持たないようにすることで、オーバーフィッティング現象を解消することができます。スケジューラはCosine Decayを使うことで、安定的に途切れることなくLossが減少するようにします。
#モデルが予測した結果とチェックポイントが保存される出力ディレクトリ。
output_dir = "./results"
# 訓練エポック数
num_train_epochs = 1
# fp16/bf16 学習有効化(A100でbf16をTrueに設定)
fp16 = False
bf16 = False
# トレーニング用バッチサイズ
per_device_train_batch_size = 1
# 評価用バッチサイズ
per_device_eval_batch_size = 1
# グラデーションを累積する更新ステップ数
gradient_accumulation_steps = 1
# グラデーションチェックポイントを有効にする
gradient_checkpointing = True
# グラデーションクリッピングの最大グラデーションノルムを設定します。
# 勾配クリッピングは、勾配の大きさを制限し、トレーニング中の安定性を高めます。
# Maximum gradient normal (グラデーションクリッピング) 0.3に設定します。
max_grad_norm = 0.3
# 初期学習率 AdamW オプティマイザー
learning_rate = 2e-6
# bias/LayerNorm 重みを除くすべてのレイヤーに適用する Weight decay 値。
weight_decay = 0.001
# オプティマイザー設定
optim = "paged_adamw_32bit"
# 学習率スケジューラのタイプ設定、ここではコサインスケジューラを使用します。
lr_scheduler_type = "コサイン"
# トレーニングステップ数(num_train_epochsオーバーライド)
max_steps = -1
# (0からlearning rateまで) 学習初期に学習率を徐々に増加させる linear warmupステップのRatio
warmup_ratio = 0.03
# #シーケンスを同じ長さのバッチにグループ化し、メモリを節約し、トレーニングを高速化します。
group_by_length = True
# X 更新段階ごとにチェックポイントを保存
save_steps = 0
# #毎X更新ステップログ
logging_steps = 25
Python
복사
Step 6. SFTパラメータ値の設定
•
以前準備したデータセットをもとにSupervised Fine-Tuning(SFT)を進めてみましょう。私たちはSFTTrainerでImportしたライブラリを使います。
•
SFTは、プロンプトデータセットを利用してベースモデルを学習させてファインチューニングする手法で、与えられた一定トークンに対して次のトークンを予測する形式で行われます。私たちのデータセットでは、与えられた質問に対する回答を推測する形になります。
•
max_seq_lengthは入力シーケンスの最大サイズを意味します。例えば、2つの文が合わさったとき、maximum sequenceがどの程度になるかを決定します。
•
packing とは、訓練過程での効率を高めるために、複数の例文を一つのInputシーケンスにまとめる手法を意味する。
•
device_mapを通してGPUを何回ロードするかを指定することができます。筆者の学習環境はGPU1枚だけでしたので、0番のGPUをロードするように設定しました。
# 最大シーケンス長設定
max_seq_length = None
# 同じ入力シーケンスに複数の短い例を入れ、効率を上げることができます。
packing = False
# GPU 0 フルモデルロード
device_map = {"":0}
Python
복사
Step 7. データロードとデータタイプの決定
•
上で説明したパラメータを注入してみましょう。まず、SFTを進めるためデータセットをロードします。そしてBitsAndBytesConfigインスタンスを生成する時、先ほどのデータ型を注入してみましょう。
dataset = load_dataset(dataset_name, split="train")
[Output]
Downloading readme: 100%|██████████| 1.02k/1.02k [00:00<00:00, 8.09MB/s]
Downloading data files: 0%| | 0/1 [00:00<?, ?it/s]
Downloading data: 0%| | 0.00/967k [00:00<?, ?B/s]
Downloading data: 100%|██████████| 967k/967k [00:00<00:00, 2.20MB/s]
Downloading data files: 100%|██████████| 1/1 [00:00<00:00, 2.24it/s]
Extracting data files: 100%|██████████| 1/1 [00:00<00:00, 1054.38it/s]
Generating train split: 100%|██████████| 1000/1000 [00:00<00:00, 89155.15 examples/s]
Plain Text
복사
compute_dtype = getattr(torch, bnb_4bit_compute_dtype)
# モデル計算に使用するデータ型の決定
bnb_config = BitsAndBytesConfig(
load_in_4bit=use_4bit, # モデルを4ビットでロードするかどうかを決定
bnb_4bit_quant_type=bnb_4bit_quant_type, #量子化タイプを設定します。
bnb_4bit_compute_dtype=compute_dtype, # 計算に使用されるデータ型を設定する
bnb_4bit_use_double_quant=use_nested_quant, # ネスティング量子化を使用するかどうかを決定する。
)
JavaScript
복사
Step 8. GPUの互換性を確認
•
現在のGPUがbfloat16形式をサポートしているか確認します。GPUのCUDAのバージョンが8以上であれば、該当のデータ型をサポートします。
•
bfloat16とは、モデルのトレーニング速度を上げることができるデータ型で、16ビット浮動小数点形式を表します。もちろん32ビット浮動小数点形式より精度は比較的劣りますが、求めるメモリ容量が少ないという点で、モデル学習に有用であると言えます。
# もしGPUがバージョン8以上であれば (major >= 8) bfloat16をサポートするというメッセージを出力。
# bfloat16はトレーニング速度を上げることができるデータ型。
if compute_dtype == torch.float16 and use_4bit:
major, _ = torch.cuda.get_device_capability()
if major >= 8:
print("=" * 80)
print("Your GPU supports bfloat16: accelerate training with bf16=True")
print("=" * 80)
Python
복사
Step 9.ベースモデルのロード
•
では、事前訓練されたベースモデルとトークナイザーをロードし、LoRA演算を適用してみましょう。
# Load base model
model = AutoModelForCausalLM.from_pretrained(
model_name,
quantization_config=bnb_config,
device_map=device_map
)
model.config.use_cache = False
model.config.pretraining_tp = 1
# Load LLaMA tokenizer
tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)
# 同じバッチ内で入力のサイズを同じにするために使用するPadding TokenをEnd of SequenceというSpecial Tokenとして使用します。
tokenizer.pad_token = tokenizer.eos_token
tokenizer.padding_side = "right" # Fix weird overflow issue with fp16 training. Padding을 오른쪽 위치에 추가한다.
# Load LoRA configuration
peft_config = LoraConfig(
lora_alpha=lora_alpha,
lora_dropout=lora_dropout,
r=lora_r,
bias="none",
task_type="CAUSAL_LM", # ファインチューニングするタスクをOptionalで指定できますが、ここではCASUAL_LMを指定しました。
)
# Set training parameters
training_arguments = TrainingArguments(
output_dir=output_dir,
num_train_epochs=num_train_epochs,
per_device_train_batch_size=per_device_train_batch_size,
gradient_accumulation_steps=gradient_accumulation_steps,
optim=optim,
save_steps=save_steps,
logging_steps=logging_steps,
learning_rate=learning_rate,
weight_decay=weight_decay,
fp16=fp16,
bf16=bf16,
max_grad_norm=max_grad_norm,
max_steps=max_steps,
warmup_ratio=warmup_ratio,
group_by_length=group_by_length,
lr_scheduler_type=lr_scheduler_type,
report_to="tensorboard"
)
# Set supervised fine-tuning parameters
trainer = SFTTrainer(
model=model,
train_dataset=dataset,
peft_config=peft_config,
dataset_text_field="text",
max_seq_length=max_seq_length,
tokenizer=tokenizer,
args=training_arguments,
packing=packing,
)
Python
복사
[Output]
pytorch_model-00002-of-00002.bin: 0%| | 0.00/3.50G [00:00<?, ?B/s]
Upload 2 LFS files: 0%| | 0/2 [00:00<?, ?it/s]
pytorch_model-00002-of-00002.bin: 1%| | 30.5M/3.50G [00:04<06:41, 8.64MB/s]
.
.
.
pytorch_model-00001-of-00002.bin: 100%|██████████| 9.98G/9.98G [06:55<00:00, 24.0MB/s]
Upload 2 LFS files: 100%|██████████| 2/2 [06:58<00:00, 209.07s/it]
CommitInfo(commit_url='https://huggingface.co/sigridjineth/sionic-llama-2-7b-miniguanaco/commit/09f9f8db31ad72f292add66f6a35b92fc64bd031', commit_message='Upload tokenizer', commit_description='', oid='09f9f8db31ad72f292add66f6a35b92fc64bd031', pr_url=None, pr_revision=None, pr_num=None)
Plain Text
복사
Step 10.モデルのトレーニングとトレーニングしたモデルの保存
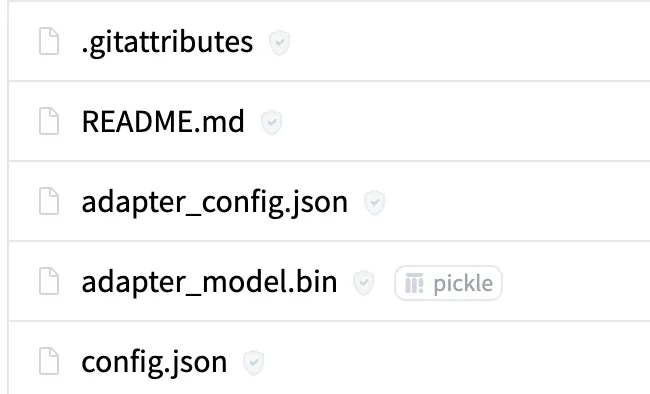
これでモデルを保存すると、bade_modelパラメータを除いたAdapter部分だけ保存されます。下記のように adapter_config.json ファイルが表示されたら成功です。
•
前述したように、trainerオブジェクトは以前に定義されたいくつかの設定(モデル、データセット、トレーニングパラメータなど)を含みます。trainメソッドでデータセットを繰り返して処理し、モデルの重みを更新する様子を見ることができます。
trainer.train()
# トレーニングが完了したモデルを 'new_model' に保存します。
trainer.model.save_pretrained(new_model)
Python
복사
[Output]
You're using a LlamaTokenizerFast tokenizer. Please note that with a fast tokenizer, using the `__call__` method is faster than using a method to encode the text followed by a call to the `pad` method to get a padded encoding.
/home/elicer/.local/lib/python3.10/site-packages/torch/utils/checkpoint.py:429: UserWarning: torch.utils.checkpoint: please pass in use_reentrant=True or use_reentrant=False explicitly. The default value of use_reentrant will be updated to be False in the future. To maintain current behavior, pass use_reentrant=True. It is recommended that you use use_reentrant=False. Refer to docs for more details on the differences between the two variants.
warnings.warn(
[1000/1000 37:46, Epoch 1/1]
warnings.warn(
Step Training Loss
25 1.691000
50 2.435900
75 1.529900
100 2.866300
125 1.665800
150 2.570100
175 1.635100
200 2.771900
225 1.516600
250 2.527600
275 1.659200
300 2.742900
325 1.806100
350 2.258200
375 1.736300
400 2.426000
425 1.647400
450 2.333400
475 1.522800
500 2.074800
525 1.554100
550 2.018100
575 1.577300
600 2.528600
625 1.618900
650 2.385800
675 1.494100
700 2.507100
725 1.608700
750 2.616200
775 1.460400
800 2.407700
825 1.504700
850 2.582100
875 1.583400
900 2.475300
925 1.485700
950 2.668500
975 1.676400
1000 2.351000
Plain Text
복사
Step 11.モデル名の出力と基本モデルリロード後、LoRA重み付けとの統合
•
学習されたLoRA adapterの重みを元のモデルにマージするmerge_and_unloadメソッドを活用してモデルとLoRAを別々に呼び出してマッピングせずに一つのモデルとして活用します。
•
LoRAアダプタで得られたファインチューニングの結果物のサイズは数MBしかありません。これらのアダプタを事前学習されたモデルに merge_and_unload の一行でマージし、そのモデルを配布します。このようなアダプタパターンの利点は、特定の課題に応じて、ファインチューニングされたアダプタを柔軟に設定できることです。
# base_modelとnew_modelに保存されたLoRAの重みを統合して新しいモデルを生成します。
base_model = AutoModelForCausalLM.from_pretrained(
model_name,
low_cpu_mem_usage=True,
return_dict=True,
torch_dtype=torch.float16
)
model = PeftModel.from_pretrained(base_model, new_model) # LoRAの重みを取得し、基本モデルに統合する
JavaScript
복사
[Output]
NousResearch/Llama-2-7b-chat-hf
Loading checkpoint shards: 100%|██████████| 2/2 [00:00<00:00, 4.03it/s]
Plain Text
복사
model = model.merge_and_unload()
Python
복사
# プリトレーニングされたトークナイザーをリロードします。
tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)
# トークナイザーのパディングトークンを終了トークン(end-of-sentence token)と同じに設定する。
tokenizer.pad_token = tokenizer.eos_token
# パディングをシーケンスの右側に適用します。
tokenizer.padding_side = "right"
JavaScript
복사
Step 12. Hugging Face Hubログイン
•
私たちが最終的にマージしたモデルをアップロードするために、最後にHuggingfaceにログインしましょう。
from huggingface_hub import interpreter_login
interpreter_login()
JavaScript
복사
[Output]
_| _| _| _| _|_|_| _|_|_| _|_|_| _| _| _|_|_| _|_|_|_| _|_| _|_|_| _|_|_|_|
_| _| _| _| _| _| _| _|_| _| _| _| _| _| _| _|
_|_|_|_| _| _| _| _|_| _| _|_| _| _| _| _| _| _|_| _|_|_| _|_|_|_| _| _|_|_|
_| _| _| _| _| _| _| _| _| _| _|_| _| _| _| _| _| _| _|
_| _| _|_| _|_|_| _|_|_| _|_|_| _| _| _|_|_| _| _| _| _|_|_| _|_|_|_|
To login, `huggingface_hub` requires a token generated fromhttps://huggingface.co/settings/tokens .
Token: ········
Add token as git credential? (Y/n) y
Token is valid (permission: write).
Cannot authenticate through git-credential as no helper is defined on your machine.
You might have to re-authenticate when pushing to the Hugging Face Hub.
Run the following command in your terminal in case you want to set the 'store' credential helper as default.
git config --global credential.helper store
Readhttps://git-scm.com/book/en/v2/Git-Tools-Credential-Storage for more details.
Token has not been saved to git credential helper.
Your token has been saved to /home/elicer/.cache/huggingface/token
Login successful
Plain Text
복사
Step 13. モデルとトークナイザーをHugging Face Hubにアップロード
•
モデルとトークナイザーをHugging Face Hubにアップロードします。このプロセスが重要な理由は、私たちがファインチューニングしたモデルをダウンロードして、Local環境のWebGPUをサポートするブラウザで駆動するためです。
•
また、必要なときにいつでもアクセスしてダウンロードすることができ、共同研究者が協力するのに役立ちます。
•
model.push_to_hub(new_model, use_temp_dir=False)
tokenizer.push_to_hub(new_model, use_temp_dir=False)
JavaScript
복사
[Output] pytorch_model-00002-of-00002.bin: 0%| | 0.00/3.50G [00:00<?, ?B/s]
Upload 2 LFS files: 0%| | 0/2 [00:00<?, ?it/s]
pytorch_model-00002-of-00002.bin: 1%| | 30.5M/3.50G [00:04<06:41, 8.64MB/s]
pytorch_model-00002-of-00002.bin: 1%|▏ | 46.3M/3.50G [00:05<03:24, 16.9MB/s]B/s]
pytorch_model-00002-of-00002.bin: 1%|▏ | 51.4M/3.50G [00:06<03:56, 14.6MB/s]]
.
.
.
pytorch_model-00001-of-00002.bin: 100%|██████████| 9.98G/9.98G [06:55<00:00, 24.0MB/s]
Upload 2 LFS files: 100%|██████████| 2/2 [06:58<00:00, 209.07s/it]
CommitInfo(commit_url='https://huggingface.co/sigridjineth/sionic-llama-2-7b-miniguanaco/commit/09f9f8db31ad72f292add66f6a35b92fc64bd031', commit_message='Upload tokenizer', commit_description='', oid='09f9f8db31ad72f292add66f6a35b92fc64bd031', pr_url=None, pr_revision=None, pr_num=None)
JavaScript
복사
今回はLLaMA2を基盤に独自のデータセットを活用して事前訓練されたモデルをファインチューニングするプロセスを実習してみました。次の記事では、私たちがHuggingfaceにアップロードしたモデルを基に、外部ネットワークが繋がらない環境下でもWebGPUを活用してプライベートなLLMを駆動するようにフロントエンドを構成する方法に対して説明したいと思います。
参考資料
下記のリンクを参考に作成しました
•
LLaMA公式Hugging Face: meta-llama/Llama-2-7b · Hugging Face
•
テストリンク : LIama:abs.perplexity.ai
•
関連ニュースとブログ